1、定位符
`^`:标记开始的位置(*特别说明,^在方括号表达式中使用,此时它表示不接受该字符集合,即"非"*)
`$`:标记结束的位置
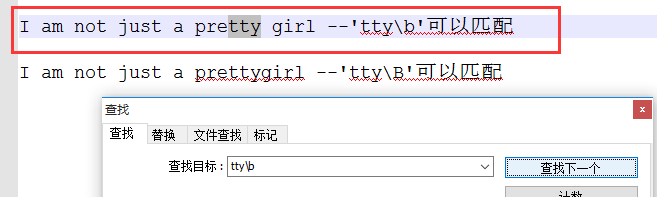
`\b`:匹配一个单词边界,也就是指单词和空格间的位置(单词边界不仅指空格)
`\B`:匹配非单词边界
示例:关于‘\b’和'\B'的区别
![]()
![]()
2、 限定符
`*`:匹配前面的子表达式零次或多次。等价于{0,}
`+`:匹配前面的子表达式一次或多次。等价于{1,}
`?`:匹配前面的子表达式零次或一次。等价于{0,1}
`{n}`:n 是一个非负整数。匹配确定的 n 次。等价于{0,}
`{n,}`:n 是一个非负整数。至少匹配n 次。等价于{1,}
`{n,m}`:m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。等价于{0,1}
3、 表达式
`()`:标记一个子表达式的开始和结束位置
`[`:标记一个中括号表达式的开始[]
`{`:标记限定符表达式的开始{}
4、 贪婪与非贪婪
\*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配
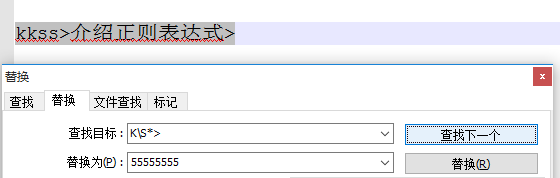
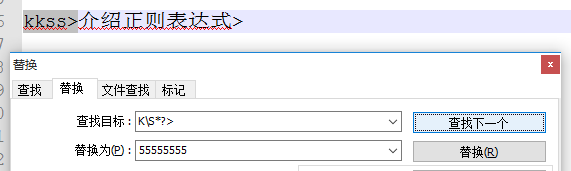
示例1:“kkss>介绍正则表达式>” ---匹配以‘k’开头,以'>'结尾的内容
①**贪婪**:
1)文本编辑器里:K\S*>匹配: kkss>介绍正则表达式>
2)程序里:/k.\*>/匹配: kkss>介绍正则表达式>
②**非贪婪**:
1)文本编辑器:k\S*?> 匹配:kkss>
2)程序: /k.\*?>/ 匹配:kkss>
文本编辑器例图:
![]()
![]()
示例2:‘1site sea sue sweet see case sse ssee losesk’---可以试试以下效果,帮助理解以上内容(文本编辑器即可)
①\bs\S*?e\b
②s\S*?e\b
③s\S*?e
④s\S*e
⑤s*?e -----这是个错的,为什么错,可以思考一下为什么错
5、字符簇
`[a-z]` :匹配所有的小写字母
`[A-Z]` :匹配所有的大写字母
`[a-zA-Z]` :匹配所有的字母
`[0-9]` :匹配所有的数字
`[0-9\.\-]` :匹配所有的数字,句号和减号
`[ \f\r\t\n]` :匹配所有的白字符
`(x|y)` :匹配x或y
6、 其他特殊字符
`\w` 匹配字母数字及下划线,等价于[a-zA-Z0-9_]
`\W` 匹配任何非单词字符。等价于 [^A-Za-z0-9_]
`\s` 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]
`\S` 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]
`\d` 匹配一个数字字符。等价于 [0-9]
`\D` 匹配一个非数字字符。等价于 [^0-9]
`.` 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n] ' 的模式
7、 正向反向
①`(?:pattern).`:匹配 pattern 但不获取匹配结果,非获取匹配。例:industr(?:y|ies) =>'industry|industries' 。---左边是官方解释,尚有一些疑问,我理解的是 ‘完全匹配’
②`(?=pattern)`:正向肯定预查,例:Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。
③`(?!pattern)`:正向否定预查,例:Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。
④`(?<=pattern)`:反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反.例:"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。
⑤`(?< !/pattern)`:反向否定预查,与正向否定预查类似,只是方向相反。例:"(?< !95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。
示例:
①`(?:pattern)---window(?:2000) 查到window开头2000结尾的,选中window2000
![]()
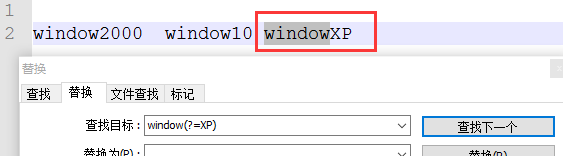
②(?=pattern)---window(?=XP) 查到window开头XP结尾的,选中window
![]()
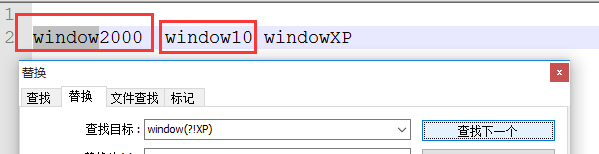
③(?!pattern)---window(?!XP) 查到window开头,非XP结尾的,选中window
![]()
④(?<=pattern)---(?<=2000)window 查找以2000开头和window结尾的 选中window
![]()
⑤(?< !/pattern) 是④的反向
五、可视化的正则表达式神器
可以先贴图看是否需要:
六、常用的正则应用表达式
1、验证手机号码:^1[3|4|5|7|8][0-9]{9}\$
2、 验证身份证号(地区+年月日+顺序码+校验码)
(15位):"\d{14}[[0-9],0-9xX]",(18位):"\d{17}[[0-9],0-9xX]"
(18位)^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]\$
(15位)^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{2}\$
汇总:(^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]\$)|(^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{2}\$)
3、 匹配ip地址:([1-9]{1,3}\.){3}[1-9]
4、 匹配长度为3的字符:"^.{3}\$"
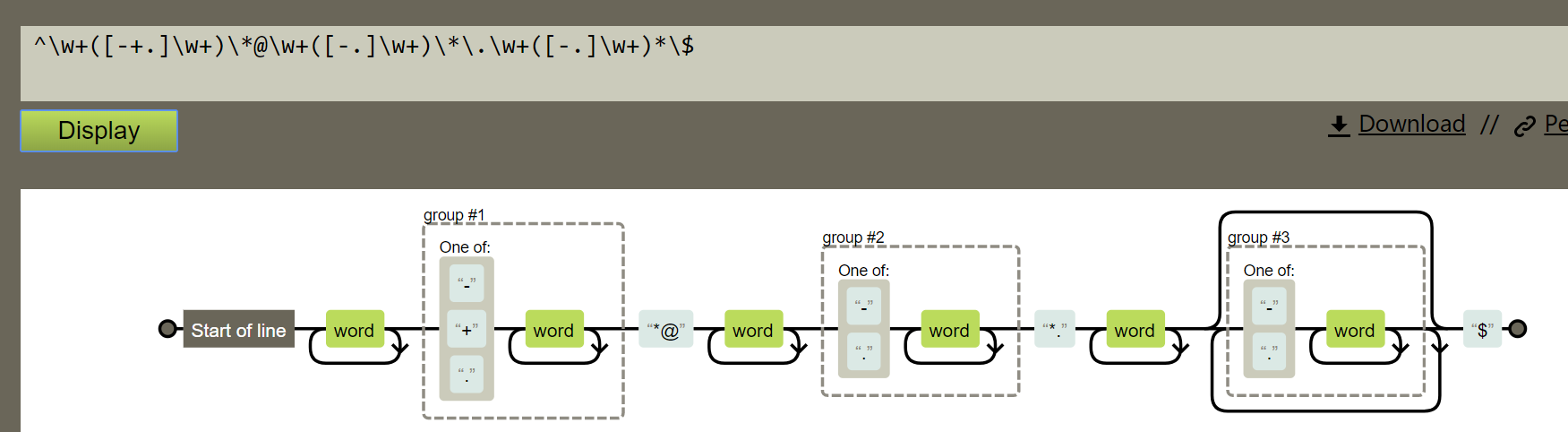
5、验证Email地址:("^\w+([-+.]\w+)\*@\w+([-.]\w+)\*\.\w+([-.]\w+)*\$")
6、 验证URL:"^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$"
七、其他学习资料
http://www.runoob.com/regexp/regexp-tutorial.html
八、常用积累记录
1、【这里是要留下了的内容', '2016-12-9 13:51:14.811668', '案号');】变为【这里是要留下来的内容】,使用正则表达式:【 ', '.*; 】 表示以【', '】开头,以【;】结尾,【.*】表示贪婪匹配任何字符。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号