

2020 CVPR ,这里只对Attention Scaling for Crowd Counting做简要叙述,因英语水平有限,部分叙述有误的地方,请多多指点。需要的话请看原文:https://github.com/gjy3035/Awesome-Crowd-Counting
摘要
人群计数的主要任务是学习图片与密度图之间的映射关系。由于人群密度在图片上的变化较大,以数据为驱动的网络很容易在人群数量估计时出现误差。为解决这一问题,我们提出了一种减轻不同区域计数性能差异的方法。主要包括Density Attention Network(DANet) 和Attention Scaling Network(ASNet)两个网络。DANet为ASNet提供了与不同密度水平区域相关的注意力掩膜。ASNet首先生成中间密度图和缩放因子,然后将它们与注意力掩膜相乘,以输出多张基于注意力的不同密度水平的密度图。这些密度图相加得到最终密度图。注意尺度因子有助于减弱不同区域的估计误差。此外,还提出了一种新的自适应金字塔损失(APLoss)来分层计算子区域的估计损失,从而减少训练偏差。并在多个数据集上取得了不错的效果。
具体方法
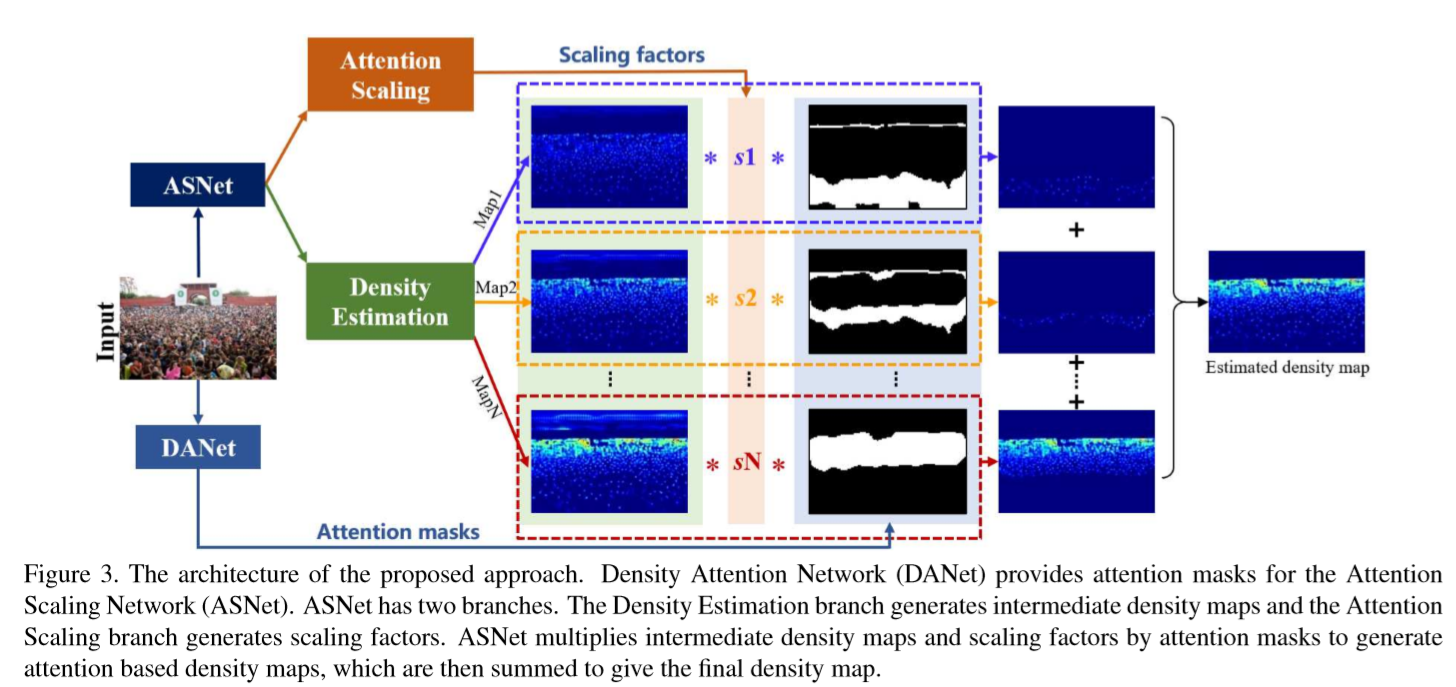 如上图所示,网络由DANet和ASNet构成。DANet为ASNet提供关于不同密度级别区域的注意力掩模.ASNet由密度图生成器(Density Generating) 和注意力尺度因子(Attention Scaling)两个分支构成。ASNet将它们与注意力掩模相乘,叠加之后形成最终的密度图。
如上图所示,网络由DANet和ASNet构成。DANet为ASNet提供关于不同密度级别区域的注意力掩模.ASNet由密度图生成器(Density Generating) 和注意力尺度因子(Attention Scaling)两个分支构成。ASNet将它们与注意力掩模相乘,叠加之后形成最终的密度图。
Density Attention Network
DANet的目标是生成一个可以表示不同密度区域的注意力掩模,相当于一个像素级别的语义分割任务。DANet使用一个以像素为中心的局部计数来表示密度等级,使得局部区域的每个像素点都属于同一密度等级。具体4个步骤:1. 使用一个64x64的滑窗来获得每个局部区域的人群数量,计算所有非零局部计数的平均值AvgCnt1,并找到这些局部计数里的最小值MinCnt1和最大值MaxCnt1; 2. 以{MinCnt1,AvgCnt1,MaxCnt1}为阈值,将所有的局部区域划分为低密度区域和高密度区域;3. 进而以迭代的方式,可以求出所有低密度区域的平均值AvgCnt21,和高密度区域的平均值AvgCnt22. 从而可以将密度区域按照{MinCnt1,AvgCnt21,AvgCnt1,AvgCnt22,MaxCnt1}划分为4个密度等级。由此可以一直迭代地计算下去。4.利用这些阈值集,根据其对应的局部计数,自动标注密度图每个像素点的密度等级。
密度标签完成之后,对DANet网络进行训练。DANet的网络结构如下:
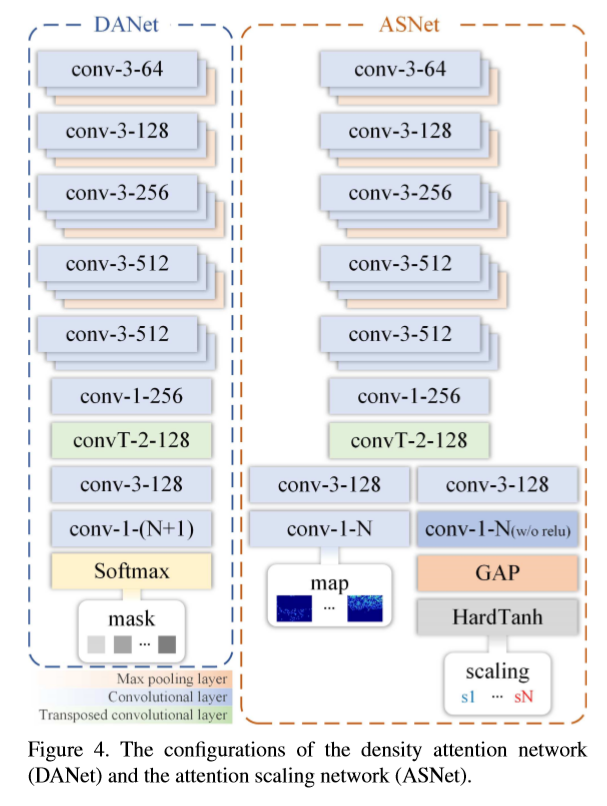
Attention Scaling Network
ASNet由两个分支结构组成:DE-branch 和 AS-branch。DE生成还需要矫正的中间密度图;AS学习缩放因子,它主要是结合DANet提供的注意力掩膜来调整中间密度图。DE-branch可被认为是一种粗略的估计策略,它通过乘以缩放因子来调整局部的人群估计的误差。
Adaptive Pyramid Loss
Euclidean loss 忽略了不同层次的密度对网络训练过程的影响。因为图片中人群密度的分布往往是不均衡的,相应的估计误差会使训练后的网络在计数时产生误差。
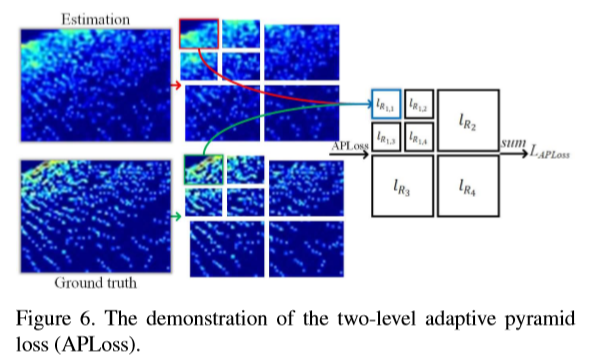
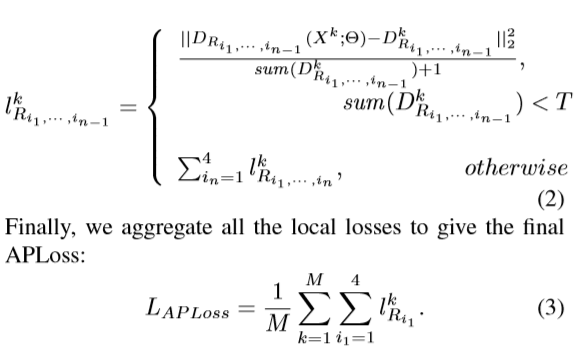
实验细节
对于DANet和ASNet,前13个卷积层由预先训练的VGG-16模型初始化,其余层由均值为0、标准差为0.01的高斯分布随机初始化。Adam算法用于优化模型。DANet和ASNet都通过端到端进行训练。采用交叉熵作为DANet的损失函数。训练DANet时,将训练批次的大小设置为1。然后训练ASNet,将训练批的大小设置为8。

最后为自己的一个关于人群计数的github代码打个广告:https://github.com/latencytime9527/Crowd-Counting-MFANet
