Java NIO 介绍
引言
Java NIO (New IO) 是 Java 1.4 版加入的新特性,虽然 Java 技术日新月异,但历经 10 年,NIO 依然为 Java 技术领域里最为重要的基础技术栈,而且依据现实的应用趋势,在可以预见的未来,它仍将继续在 Java 技术领域占据重要位置。
NIO 弥补了原来的 I/O 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。通过定义包含数据的类,以及通过以块的形式处理这些数据,NIO 不用使用本机代码就可以利用低级优化,这是原来的 I/O 包所无法做到的。
I/O 简介
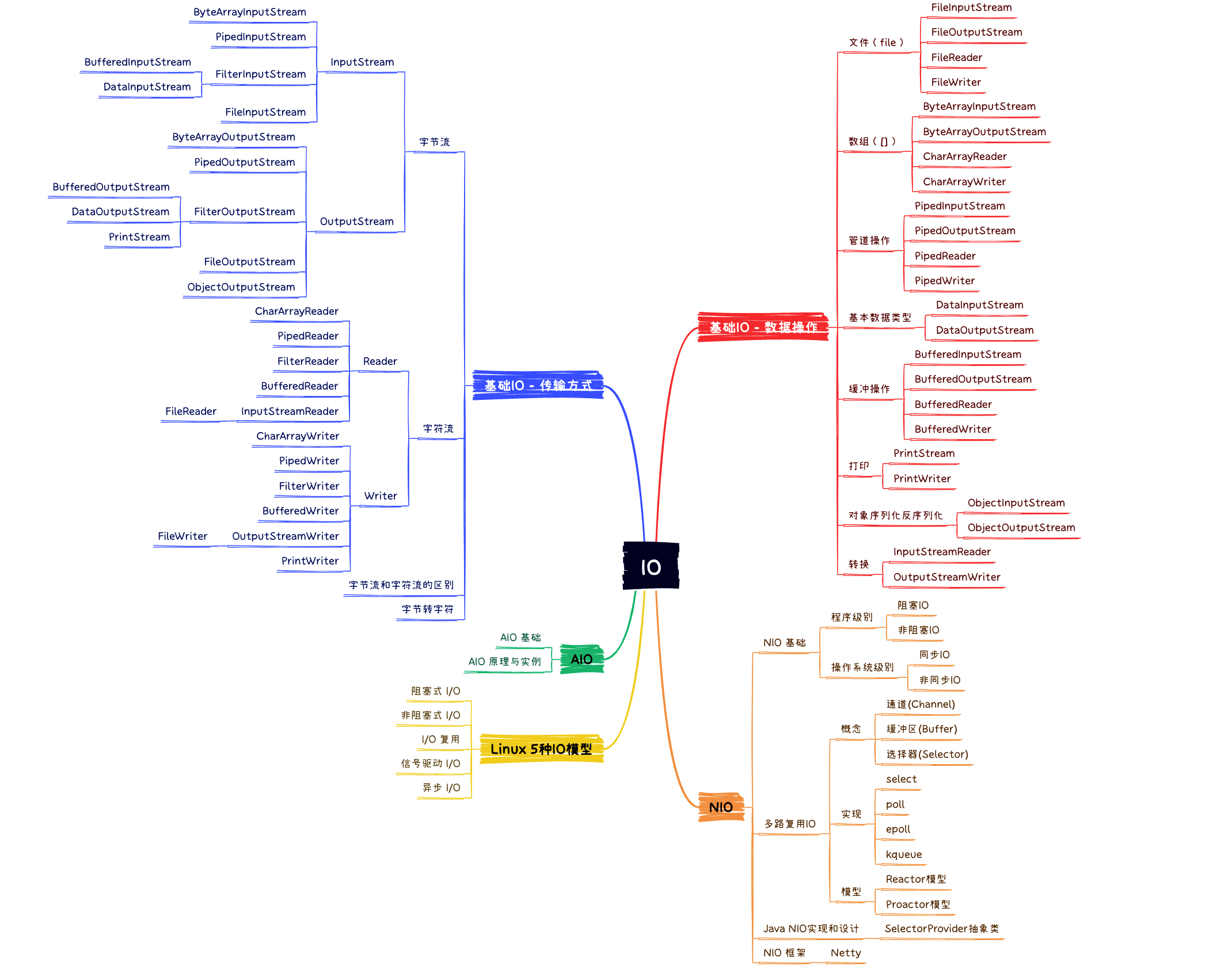
I/O(Input/Output,输入/输出)指的是计算机与外部世界或者一个程序与计算机的其余部分的之间的接口。它对于任何计算机系统都非常关键,因而所有 I/O 的主体实际上是内置在操作系统中的。单独的程序一般是让系统为它们完成大部分的工作。
在 Java 编程中,直到最近一直使用 流 的方式完成 I/O。所有 I/O 都被视为单个的字节的移动,通过一个称为 Stream 的对象一次移动一个字节。流 I/O 用于与外部世界接触。它也在内部使用,用于将对象转换为字节,然后再转换回对象。
为什么要使用 NIO
NIO 的创建目的是为了让 Java 程序员可以实现高速 I/O 而无需编写自定义的本机代码。NIO 将最耗时的 I/O 操作(即填充和提取缓冲区)转移回操作系统,因而可以极大地提高速度。
流与块的比较
原来的 I/O 库(在 java.io.* 中) 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
-
面向流的 I/O 系统:一次一个字节地处理数据。
一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
-
面向块的 I/O 系统:以块的形式处理数据。
每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
多路复用 IO
目前流行的多路复用 IO 实现主要包括四种:select、poll、epoll、kqueue。下表是它们的一些重要特性的比较:
| IO 模型 | 性能 | 思路 | 操作系统 | JAVA支持情况 |
|---|---|---|---|---|
| select | 较高 | Reactor | windows、linux | 支持 |
| poll | 较高 | Reactor | linux | 支持 |
| epoll | 高 | Reactor/Proactor | linux | 支持 |
| kqueue | 高 | Proactor | linux、macos | 不支持 |
多路复用 IO 技术最适用的是“高并发”场景,所谓高并发是指 1 毫秒内至少同时有上千个连接请求准备好的场景,如:网络IO,其他情况下多路复用 IO 技术发挥不出来它的优势。
传统 IO 模型
传统 IO 模型,其主要是一个 Server 对接 N 个客户端,在客户端连接之后,为每个客户端都分配一个执行线程。如下图所示:
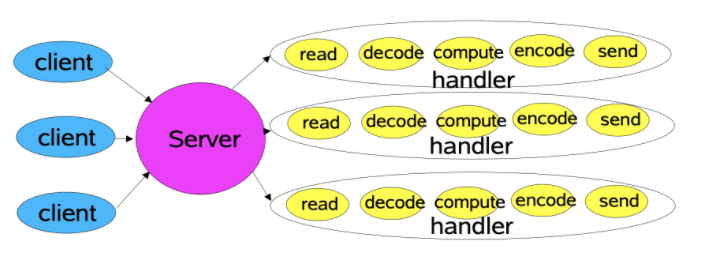
从图中可以看出,传统 IO 的特点在于:
-
每个客户端连接到达之后,服务端会分配一个线程给该客户端,该线程会处理包括读取数据,解码,业务计算,编码,以及发送数据整个过程;
-
同一时刻,服务端的吞吐量与服务器所提供的线程数量是呈线性关系的。这种设计模式在客户端连接不多,并发量不大的情况下是可以运行得很好的,但是在海量并发的情况下,这种模式就显得力不从心了。
这种模式主要存在的问题有如下几点:
-
服务器的并发量对服务端能够创建的线程数有很大的依赖关系,但是服务器线程却是不能无限增长的;
-
服务端每个线程不仅要进行 IO 读写操作,而且还需要进行业务计算;
-
服务端在获取客户端连接,读取数据,以及写入数据的过程都是阻塞类型的,在网络状况不好的情况下,这将极大的降低服务器每个线程的利用率,从而降低服务器吞吐量。
Reactor 事件驱动模型
单线程 Reactor 事件驱动模型
单线程 Reactor 事件驱动模型的示意图:
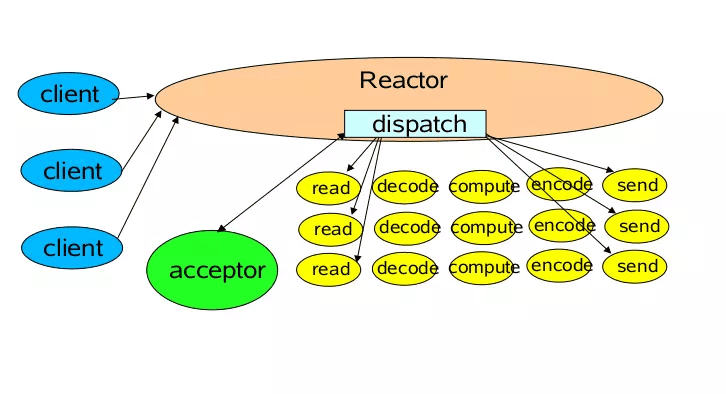
在 Reactor 模型中,主要有四个角色:客户端连接、Reactor、Acceptor 和 Handler。其中,Acceptor 会不断地接收客户端的连接,然后将接收到的连接交由 Reactor 进行分发,最后由具体的 Handler 进行处理。
对比传统的阻塞 IO 模型, Reactor 模型相对于传统的IO模型主要有如下优点:
-
Reactor 模型是以事件进行驱动的,其能够将接收客户端连接、网络读写、以及业务计算进行拆分,从而极大的提升处理效率;
-
Reactor 模型是异步非阻塞模型,工作线程在没有网络事件时可以处理其他的任务,而不用像传统 IO 那样必须阻塞等待。
但是,在上面的 Reactor 模型中存在两个缺点,由于网络读写和业务操作都在同一个线程中,在高并发情况下,高频率的网络读写事件处理 和 大量的业务操作处理 会成为系统瓶颈。
基于线程池的 Reactor 事件驱动模型
因此,在单线程 Reactor 模型的基础上,又提出了使用线程池的方式处理业务操作的模型。如下图所示:
在多线程进行业务操作的模型下,该模式主要具有如下特点:
-
使用一个线程进行客户端连接的接收以及网络读写事件的处理;
-
在接收到客户端连接之后,将该连接交由线程池进行数据的编解码以及业务计算。
相较于前面的模式,这种模式性能有了很大的提升,主要在于在进行网络读写的同时,也进行了业务计算,从而大大提升了系统的吞吐量。但是,这种模式也有其不足,主要在于:网络读写是一个比较消耗 CPU 的操作,在高并发的情况下,将会有大量的客户端数据需要进行网络读写,此时一个线程将不足以处理这么多请求。
基于主从的 Reactor 事件驱动模型
因此,在线程池的基础上,又提出了一种改进的模型,即使用线程池进行网络读写,而仅仅只使用一个线程专门接收客户端连接。如下图所示:
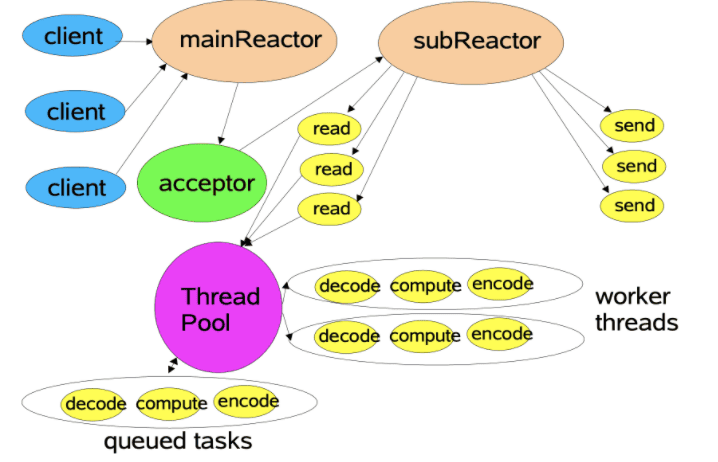
改进后的 Reactor 模型将 Reactor 拆分为: mainReactor 和 subReactor
-
mainReactor:主要进行客户端连接的处理,处理完成之后将该连接交由 subReactor 以处理客户端的网络读写。
-
subReactor:则是使用一个线程池来支撑的,其读写能力将会随着线程数的增多而大大增加。
对于业务操作,这里也是使用一个线程池,而每个业务请求都只需要进行编解码和业务计算。
通过这种方式,服务器的性能将会大大提升,在可见情况下,其基本上可以支持百万连接。
Java 对多路复用 IO 的支持
通道 和 缓冲区 是 NIO 中的核心对象,几乎在每一个 I/O 操作中都要使用它们。
通道是对原 I/O 包中的流的模拟。到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象。一个 Buffer 实质上是一个容器对象。发送给一个通道的所有对象都必须首先放到缓冲区中;同样地,从通道中读取的任何数据都要读到缓冲区中。
Buffer
在 JAVA NIO 框架中,为了保证每个通道的数据读写速度,JAVA NIO 框架为每一种需要支持数据读写的通道集成了 Buffer(缓冲区) 的支持。
缓冲区实质上是一个数组,但是一个缓冲区不 仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
在 NIO 框架中,所有数据都是用缓冲区处理的:
-
在读取数据时,它是直接读到缓冲区中的。
-
在写入数据时,它是写入到缓冲区中的。
缓冲区的存储方式
按照存储方式划分,缓冲区有两种类型:直接缓冲区、非直接缓冲区。

非直接缓冲区
在 JVM 中内存中创建,在每次触发 read/write 系统调用之前或者之后,JVM 都会将用户空间的数据复制到内核缓冲区(或者将数据从内核缓冲区复制到用户地址空间),用户空间的缓冲区中的内容驻留在 JVM 内,因此销毁容易,但是占用JVM内存开销,处理过程中有复制操作。
特点:
-
分配在 JVM 堆内存中
-
受到垃圾回收的管理
-
在读写操作时,需要将数据从堆内存复制到操作系统的本地内存,再进行 I/O 操作
-
创建方式: ByteBuffer.allocate(int capacity)
ByteBuffer buffer = ByteBuffer.allocate(1024);
直接缓冲区
特点:
-
分配在操作系统的本地内存中
-
不受垃圾回收的管理
-
在读写操作时,直接在本地内存中进行,避免了数据复制,提高了性能
-
创建方式: ByteBuffer.allocateDirect(int capacity)
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);- 还有前面提到的 FileChannel.map() 方法,会返回一个类型为 MappedByteBuffer 的直接缓冲区。
对比
| 对比 | 非直接缓冲区 | 直接缓冲区 |
|---|---|---|
| 内存 | 堆外内存 | JVM 堆内存 |
| 优点 | 安全 | 速度快 |
| 缺点 | 速度慢,读写效率低 | 不安全,CPU占用率高,大文件容易导致卡死 |
缓冲区的数据类型
按照数据类型划分,每一种基本 Java 类型都有一种缓冲区类型:ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。
每一个 Buffer 类都是 Buffer 接口的一个实例。 除了 ByteBuffer,每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使用 ByteBuffer,所以它具有所有共享的缓冲区操作以及一些特有的操作。
缓冲区内部细节
Buffer 类维护了 4 个核心变量来提供关于其所包含的数组信息。它们是:
-
Capacity(容量 ):缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定,并且永远不能被改变。
-
Limit(上界):缓冲区里的数据的总数,代表了当前缓冲区中一共有多少数据。
-
Position(位置):下一个要被读或写的元素的位置。Position 会自动由相应的 get()和 put()函数更新。
-
Mark(标记):一个备忘位置。用于记录上一次读写的位置。
这里,我们使用一个示例,来演示核心变量的值得变化过程:
【示例】
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
byteBuffer.put("abcdefghijkl");
// 切换为读模式
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.limit()];
byteBuffer.get(bytes);
System.out.println(new String(bytes, 0, bytes.length));
byteBuffer.clear();
其变化过程如下:

Channel
A channel represents an open connection to an entity such as a hardware device, a file, a network socket, or a program component that is capable of performing one or more distinct I/O operations, for example reading or writing.
-- JDK API
Channel(通道):被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。一个通道会有一个专属的文件状态描述符。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据。
Channel 通道只负责传输数据、不直接操作数据。操作数据都是通过 Buffer 缓冲区来进行操作!通常,通道可以分为两大类:文件通道和套接字通道。
所有被 Selector 注册的通道,只能是继承了 SelectableChannel 类的子类。常用的通道类型如下:
-
FileChannel
用于文件 I/O 的通道,支持文件的读、写和追加操作。FileChannel 允许在文件的任意位置进行数据传输,支持文件锁定以及内存映射文件等高级功能。FileChannel 无法设置为非阻塞模式,因此它只适用于阻塞式文件操作。
-
SocketChannel
用于 TCP 套接字 I/O 的通道。SocketChannel 支持非阻塞模式,可以与 Selector 一起使用,实现高效的网络通信。SocketChannel 允许连接到远程主机,进行数据传输。
-
ServerSocketChannel
用于监听 TCP 套接字连接的通道。与 SocketChannel 类似,ServerSocketChannel 也支持非阻塞模式,并可以与 Selector 一起使用。ServerSocketChannel 负责监听新的连接请求,接收到连接请求后,可以创建一个新的 SocketChannel 以处理数据传输。
-
DatagramChannel
用于 UDP 套接字 I/O 的通道。DatagramChannel 支持非阻塞模式,可以发送和接收数据报包,适用于无连接的、不可靠的网络通信。
FileChannel
文件通道传输数据有三种方式:直接读写缓冲区、内存映射文件、sendfile 系统调用。
直接操作缓冲区
使用 FileChannel 配合 ByteBuffer 缓冲区实现文件复制的功能。
【示例】
public class FileUtils {
public static void copy(Path source, Path destination) throws IOException {
try (FileChannel sourceChannel = FileChannel.open(source, StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(destination, StandardOpenOption.WRITE, StandardOpenOption.CREATE)) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (sourceChannel.read(buffer) != -1) {
buffer.flip();
destinationChannel.write(buffer);
buffer.clear();
}
}
}
}
测试验证:
public class FileUtilsTest {
public static void main(String[] args) {
Path source = Paths.get("D:\\Temp\\log.txt");
Path destination = Paths.get("D:\\Temp\\log1.txt");
try {
FileUtils.copy(source, destination1);
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用 mmap 的方式
使用内存映射文件(MappedByteBuffer)的方式实现文件复制的功能(直接操作缓冲区)。
【示例】
public class FileUtils {
public static void copy2(Path source, Path destination) throws IOException {
try (FileChannel sourceChannel = FileChannel.open(source, StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(destination, StandardOpenOption.WRITE,
StandardOpenOption.CREATE, StandardOpenOption.READ)) {
long fileSize = sourceChannel.size();
MappedByteBuffer sourceMappedBuffer = sourceChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileSize);
MappedByteBuffer destinationMappedBuffer = destinationChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize);
for (int i = 0; i < fileSize; i++) {
byte b = sourceMappedBuffer.get(i);
destinationMappedBuffer.put(i, b);
}
}
}
}
MappedByteBuffer 是 ByteBuffer 的子类,MappedByteBuffer 用于表示一个内存映射文件,即将文件的一部分或全部映射到内存中,以便通过直接操作内存来实现对文件的读写。这种方式可以提高文件 I/O 的性能,因为操作系统可以直接在内存和磁盘之间传输数据,无需通过 Java 应用程序进行额外的数据拷贝。
在循环中,我们逐字节地从源文件的 MappedByteBuffer 读取数据并将其写入目标文件的 MappedByteBuffer。这样就实现了文件复制功能。利用内存映射文件(MappedByteBuffer)实现的文件复制,可能会比使用 ByteBuffer 的方法更快。
需要注意的,使用 MappedByteBuffer 进行文件操作时,数据的修改可能不会立即写入磁盘。可以通过调用 MappedByteBuffer 的 force() 方法将数据立即写回磁盘。
使用 sendfile 的方式
通道之间通过 transferTo() 实现数据的传输。
【示例】
public class FileUtils {
public static void copy(Path source, Path destination) throws IOException {
try (FileChannel sourceChannel = FileChannel.open(source, StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(destination, StandardOpenOption.CREATE, StandardOpenOption.WRITE)) {
long position = 0;
long count = sourceChannel.size();
while (position < count) {
long transferred = sourceChannel.transferTo(position, count - position, destinationChannel);
position += transferred;
}
}
}
}
FileChannel 的 transferTo() 方法是一个高效的文件传输方法,它允许将文件的一部分或全部内容直接从源文件通道传输到目标通道(通常是另一个文件通道或网络通道)。这种传输方式可以避免将文件数据在用户空间和内核空间之间进行多次拷贝,提高了文件传输的性能。
transferTo() 方法在底层使用了操作系统提供的零拷贝功能(如 Linux 的 sendfile() 系统调用),可以大幅提高文件传输性能。
在 Java 中,零拷贝技术主要应用于文件和网络 I/O。FileChannel 类的
transferTo()和transferFrom()方法就利用了零拷贝技术,可以在文件和网络通道之间高效地传输数据。
ServerSocketChannel 和 SocketChannel
为了解决传统阻塞式网络 I/O 的性能问题,Java NIO 引入了 ServerSocketChannel 和 SocketChannel。它们是非阻塞 I/O,可以在单个线程中处理多个连接。
-
ServerSocketChannel:用于创建服务器端套接字
类似于 ServerSocket,表示服务器端套接字通道。它负责监听客户端连接请求,并可以设置为非阻塞模式,这意味着在等待客户端连接请求时不会阻塞线程。
-
SocketChannel:用于创建客户端套接字
类似于 Socket,表示客户端套接字通道。它负责与服务器端建立连接并进行数据的读写。SocketChannel 也可以设置为非阻塞模式,在读写数据时不会阻塞线程。
分散和聚集
通道可以有选择地实现两个新的接口: ScatteringByteChannel 和 GatheringByteChannel。
Scatter 和 Gather 是 Java NIO 中两种高效的 I/O 操作,用于将数据分散到多个缓冲区或从多个缓冲区中收集数据。
Scatter
Scatter(分散):它将从 Channel 读取的数据分散(写入)到多个缓冲区。这种操作可以在读取数据时将其分散到不同的缓冲区,有助于处理结构化数据。例如,我们可以将消息头、消息体和消息尾分别写入不同的缓冲区。
一个 ScatteringByteChannel 是一个具有两个附加读方法的通道:
long read( ByteBuffer[] dsts );
long read( ByteBuffer[] dsts, int offset, int length );
Gather
Gather(聚集):它将多个缓冲区中的数据聚集(读取)并写入到一个 Channel。这种操作允许我们在发送数据时从多个缓冲区中聚集数据。例如,我们可以将消息头、消息体和消息尾从不同的缓冲区中聚集到一起并写入到同一个 Channel。
一个 GatheringByteChannel 是一个具有两个附加写方法的通道:
long write( ByteBuffer[] srcs );
long write( ByteBuffer[] srcs, int offset, int length );
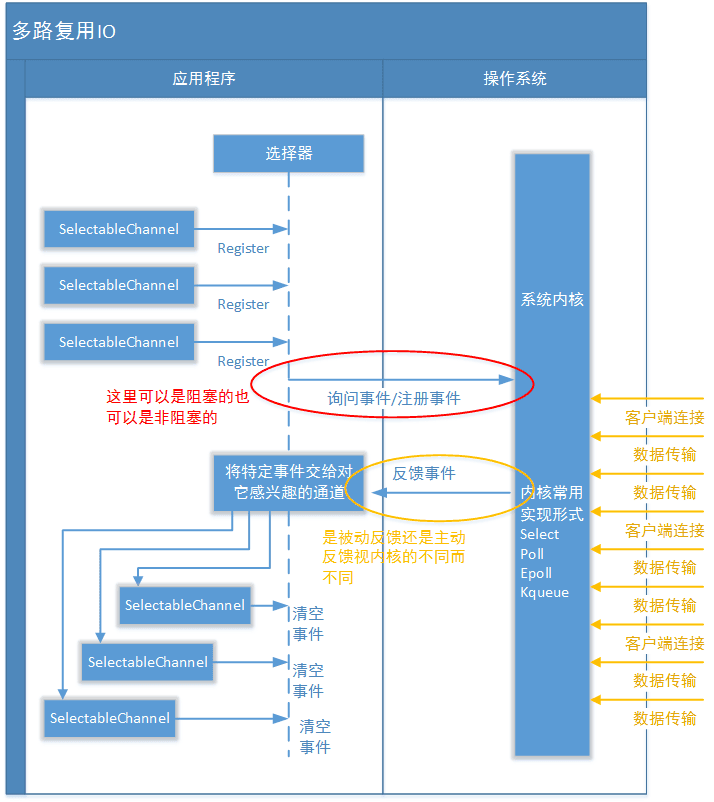
Selector
Selector 是 Java NIO 中的一个关键组件,用于实现 I/O 多路复用。它允许在单个线程中同时监控多个 ServerSocketChannel 和 SocketChannel,并通过 SelectionKey 标识关注的事件。当某个事件发生时,Selector 会将对应的 SelectionKey 添加到已选择的键集合中。通过使用 Selector,可以在单个线程中同时处理多个连接,从而有效地提高 I/O 操作的性能,特别是在高并发场景下。
JAVA NIO 框架中核心的多路复用 IO 技术的 选择器 进行实现,如下:
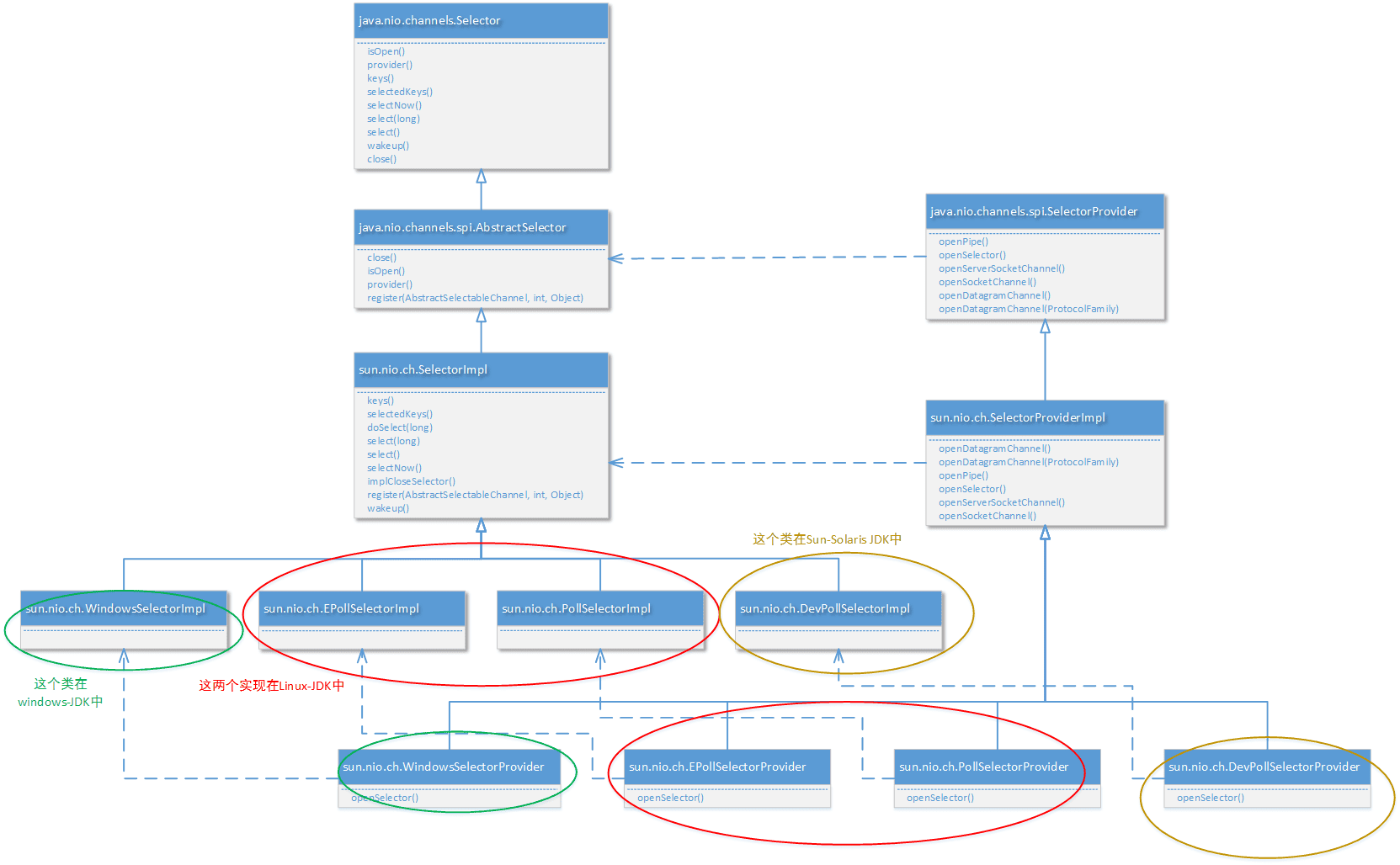
如上图所示,可以看出,不同的 SelectorProvider 实现对应了不同的选择器。由具体的 SelectorProvider 实现进行创建。
事件订阅和Channel管理
应用程序需要向 Selector 对象注册需要它关注的 Channel,以及具体的某一个 Channel 会对哪些 IO 事件感兴趣。Selector 中也会维护一个“已经注册的 Channel”的容器。
轮询代理
应用程序不再通过阻塞模式或者非阻塞模式直接询问操作系统“事件有没有发生”,而是由 Selector 代其询问。
多路复用 IO 的优缺点
-
不用再使用多线程来进行 IO 处理了(包括操作系统内核 IO 管理模块和应用程序进程而言)。
当然实际业务的处理中,应用程序进程还是可以引入线程池技术的
-
同一个端口可以处理多种协议
例如,使用 ServerSocketChannel 的服务器端口监听,既可以处理 TCP 协议,又可以处理 UDP 协议。
-
操作系统级别的优化
多路复用 IO 技术可以是操作系统级别在一个端口上,能够同时接受多个客户端的 IO 事件。同时,具有之前我们讲到的阻塞式同步 IO 和非阻塞式同步 IO 的所有特点。
Selector 的一部分作用更相当于“轮询代理器”。
-
都是同步 IO
目前我们介绍的 阻塞式 IO、非阻塞式 IO、多路复用 IO,这些都是基于操作系统级别对“同步IO”的实现。
附录
Reactor 事件驱动模型示例
Reactor
public class Reactor implements Runnable {
private final Selector selector;
private final ServerSocketChannel serverSocket;
public Reactor(int port) throws IOException {
serverSocket = ServerSocketChannel.open(); // 创建服务端的ServerSocketChannel
serverSocket.configureBlocking(false); // 设置为非阻塞模式
selector = Selector.open(); // 创建一个Selector多路复用器
SelectionKey key = serverSocket.register(selector, SelectionKey.OP_ACCEPT);
serverSocket.bind(new InetSocketAddress(port)); // 绑定服务端端口
key.attach(new Acceptor(serverSocket)); // 为服务端Channel绑定一个Acceptor
}
@Override
public void run() {
try {
while (!Thread.interrupted()) {
selector.select(); // 服务端使用一个线程不断等待客户端的连接到达
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
dispatch(iterator.next()); // 监听到客户端连接事件后将其分发给Acceptor
iterator.remove();
}
selector.selectNow();
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void dispatch(SelectionKey key) throws IOException {
// 这里的attachement也即前面为服务端Channel绑定的Acceptor,调用其run()方法进行
// 客户端连接的获取,并且进行分发
Runnable attachment = (Runnable) key.attachment();
attachment.run();
}
}
Acceptor
public class Acceptor implements Runnable {
private final ExecutorService executor = Executors.newFixedThreadPool(20);
private final ServerSocketChannel serverSocket;
public Acceptor(ServerSocketChannel serverSocket) {
this.serverSocket = serverSocket;
}
@Override
public void run() {
try {
SocketChannel channel = serverSocket.accept(); // 获取客户端连接
if (null != channel) {
executor.execute(new Handler(channel)); // 将客户端连接交由线程池处理
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Handler
public class Handler implements Runnable {
private volatile static Selector selector;
private final SocketChannel channel;
private SelectionKey key;
private volatile ByteBuffer input = ByteBuffer.allocate(1024);
private volatile ByteBuffer output = ByteBuffer.allocate(1024);
public Handler(SocketChannel channel) throws IOException {
this.channel = channel;
channel.configureBlocking(false); // 设置客户端连接为非阻塞模式
selector = Selector.open(); // 为客户端创建一个新的多路复用器
key = channel.register(selector, SelectionKey.OP_READ); // 注册客户端Channel的读事件
}
@Override
public void run() {
try {
while (selector.isOpen() && channel.isOpen()) {
Set<SelectionKey> keys = select(); // 等待客户端事件发生
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// 如果当前是读事件,则读取数据
if (key.isReadable()) {
read(key);
} else if (key.isWritable()) {
// 如果当前是写事件,则写入数据
write(key);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 这里处理的主要目的是处理Jdk的一个bug,该bug会导致Selector被意外触发,但是实际上没有任何事件到达,
// 此时的处理方式是新建一个Selector,然后重新将当前Channel注册到该Selector上
private Set<SelectionKey> select() throws IOException {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
if (keys.isEmpty()) {
int interestOps = key.interestOps();
selector = Selector.open();
key = channel.register(selector, interestOps);
return select();
}
return keys;
}
// 读取客户端发送的数据
private void read(SelectionKey key) throws IOException {
channel.read(input);
if (input.position() == 0) {
return;
}
input.flip();
process(); // 对读取的数据进行业务处理
input.clear();
key.interestOps(SelectionKey.OP_WRITE); // 读取完成后监听写入事件
}
private void write(SelectionKey key) throws IOException {
output.flip();
if (channel.isOpen()) {
channel.write(output); // 当有写入事件时,将业务处理的结果写入到客户端Channel中
key.channel();
channel.close();
output.clear();
}
}
// 进行业务处理,并且获取处理结果。本质上,基于Reactor模型,如果这里成为处理瓶颈,
// 则直接将其处理过程放入线程池即可,并且使用一个Future获取处理结果,最后写入客户端Channel
private void process() {
byte[] bytes = new byte[input.remaining()];
input.get(bytes);
String message = new String(bytes);
System.out.println("receive message from client: \n" + message);
output.put("hello client".getBytes());
}
}
基于 NIO 实现的简易聊天室
【示例】socket server
package com.simona.cloud.server;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
public class ChatServer {
private Selector selector;
private ServerSocketChannel serverSocketChannel;
private static final int PORT = 8180;
public ChatServer() {
try {
selector = Selector.open();
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(PORT));
serverSocketChannel.configureBlocking(false);
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("server is bound success with " + PORT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
try {
while (true) {
if (selector.select() > 0) {
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
handleKey(key);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handleKey(SelectionKey key) throws IOException {
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("new client : " + socketChannel.getRemoteAddress() + " connected");
} else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int read = socketChannel.read(buffer);
if (read > 0) {
buffer.flip();
String msg = new String(buffer.array(), 0, read);
System.out.println("msg from client [" + socketChannel.getRemoteAddress() + "] : " + msg);
socketChannel.write(ByteBuffer.wrap(("server reply: " + msg).getBytes()));
}
}
}
public static void main(String[] args) {
new ChatServer().start();
}
}
【示例】socket client
package com.simona.cloud.client;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.SocketChannel;
public class ChatClient {
private Selector selector;
private SocketChannel socketChannel;
private static final String HOST = "localhost";
private static final int PORT = 8180;
public ChatClient() {
try {
selector = Selector.open();
socketChannel = SocketChannel.open(new InetSocketAddress(HOST, PORT));
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("success to connect the server");
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
// 创建一个子线程用来处理selector事件,并处理sever端发送的数据
new Thread(() -> {
try {
while (true) {
if (selector.select() > 0) {
for (SelectionKey key : selector.selectedKeys()) {
selector.selectedKeys().remove(key);
if (key.isReadable()) {
readMessage();
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
// 主线程一直读取标准输入,并写入缓冲区
try (BufferedReader reader = new BufferedReader(new InputStreamReader(System.in))) {
String input;
while ((input = reader.readLine()) != null) {
sendMessage(input);
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void sendMessage(String message) throws IOException {
if (message != null && !message.trim().isEmpty()) {
ByteBuffer buffer = ByteBuffer.wrap(message.getBytes());
socketChannel.write(buffer);
}
}
private void readMessage() throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
int read = socketChannel.read(buffer);
if (read > 0) {
buffer.flip();
String msg = new String(buffer.array(), 0, read);
System.out.println(msg);
}
}
public static void main(String[] args) {
new ChatClient().start();
}
}
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号