Linux 中的 I/O 模型
I/O模型种类
概念
同步与异步
-
同步:就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。
也就是必须一件一件事做,等前一件做完了才能做下一件事。
-
异步:就是当一个异步过程调用发出后,调用者不能立刻得到结果,调用者不用等待这件事完成,可以继续做其他的事情。
实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。(回调通知)
阻塞与非阻塞
-
阻塞调用:是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,CPU不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。
-
非阻塞调用:是指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
区别
同步和异步的概念描述的是:用户线程与内核的交互方式。
-
同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作完成后才能继续执行;
-
而异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞的概念描述的是:用户线程调用内核IO操作的方式。
-
阻塞是指IO操作需要彻底完成后才返回到用户空间;
-
而非阻塞是指IO操作被调用后立即返回给用户一个状态值,无需等到IO操作彻底完成。
同步与异步是 两个对象之间的关系,而阻塞与非阻塞是 一个对象的状态。
I/O 模型分类
在 Linux 中一共有 5 种 I/O 模型,分别如下:
-
阻塞 I/O(blocking I/O)
-
非阻塞 I/O(nonblocking I/O)
-
I/O 多路复用(I/O multiplexing)
-
信号驱动 I/O(signal driven I/O )
-
异步 I/O(asynchronous I/O)
其中,较为成熟且高效、稳定的是 I/O 多路复用模型,因此,当前众多网络服务程序几乎都是采用这种 I/O 操作策略。
当一个应用程序读写(以读为例)某端口数据时,选择不同IO模型的应用程序,其执行流程也将不同。
下面,我们以一个典型的应用程序代码示例入手,进而对这 5 种不同 I/O 模型时的程序的执行过程进行分析,以便了解使用 I/O 复用模型的运行情况和性能优势。
阻塞 I/O 模型(BIO)
最流行的 IO 模型是阻塞 IO(Blocking IO)模型,几乎所有刚开始学习 IO 操作的人员都是使用这个模型,虽然它存在一定的性能缺陷,但是它的确很简单。
一个典型的读写的操作,流程如下:

从上面的时序图,可以看出一个阻塞 I/O 操作,即一次读操作或者写操作,通常会发生两次上下文切换(用户态和内核态切换)、两次数据拷贝。
磁盘文件的 I/O 比较特殊,内核采用缓冲区 cache 加速磁盘 I/O 请求,因而一旦请求的数据到达内核缓冲区 cache,对磁盘的 write() 操作立即返回,而不用等待将数据写入磁盘后再返回,除非在打开文件时指定了O_SYNC标志。
实际上,上面的阻塞 I/O 在文件读写时,不会带来太大的资源浪费,因为 Kernel 从磁盘中读取数据这过程瞬间就能完成,但是,在发起读操作的系统调用期间,如果读取的数据不能立即就绪,此时,进程就会被休眠,导致进程阻塞,直到内核将数据拷贝到用户空间为止。
因为,磁盘文件并不像网络 I/O 那样,需要等待远程传输数据,所以,实际上在磁盘 I/O 中,等待阶段是不存在的。
例如,对于一个网络套接字上的输入操作:
-
第一步,进程发起系统调用,用户态切换到内核态,当前的进程会进入睡眠,并等待数据从网络中到达,当所有等待分组到达时,数据被复制到内核中的某个缓冲区;
-
第二步,将数据从内核缓冲区复制到应用进程缓冲区,系统将会产生中断,唤醒在缓冲区上等待相应事件的进程继续执行。
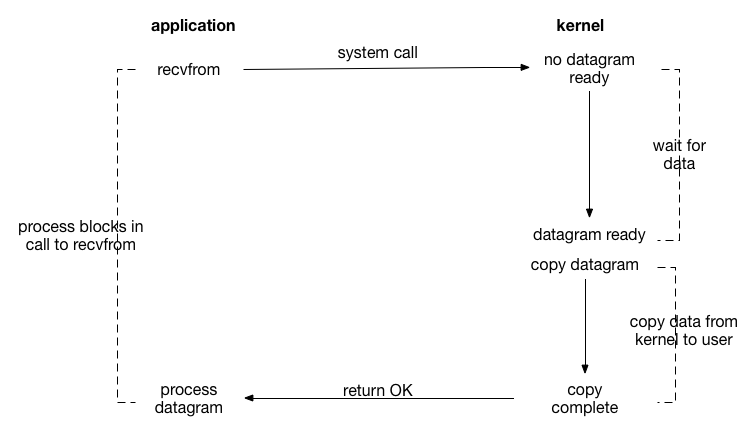
注:
read()和recvfrom()的区别是:前者从文件系统读取数据,后者从socket接收数据。
如上图所示,阻塞 I/O 发起系统调用 recvfrom() 时,进程将一直阻塞,直到另一端 Socket 的数据就绪。
通过阻塞IO系统调用进行IO操作时,以 read 为例,在内核将数据拷贝到用户程序完成之前,Linux 内核会对当前 read 请求操作的缓冲区(内存中的特殊区域)进行加锁,并且会将调用 read 的进程的状态设置为 “uninterruptible wait”状态(不可中断等待状态),处于该状态的进程将无法参与进程调度。
能够参与进程调度的进程的状态必须是处于 running 状态的进程或者有信号到达的处于 interruptible wait 状态(可中断等待状态)的进程。
当read操作完成时,内核会将对应的缓冲块解锁,然后发出中断请求,内核中的中断服务程序会将阻塞在该缓冲块上的进程的状态修改为 running 状态以使其重新具备参与进程调度的能力。
优缺点
除非特别指定,几乎所有的 I/O 接口都是阻塞型的,即系统调用时不返回调用结果,只有当该系统调用获得结果或者超时出错才返回。这样的机制给网络编程带来了较大的影响,当线程因处理数据而处于阻塞状态时,线程将无法执行任何运算或者相应任何网络请求。
阻塞 I/O 优缺点都非常明显:
-
优点:简单易用,对于本地I/O而言性能很高;
-
缺点:处理网络I/O时,造成进程阻塞空等,浪费资源。
改进方案
多线程/多进程
在服务器端使用阻塞 I/O 模型时,结合多进程/多线程技术,让每一个连接都拥有独立的进程/线程,任何一个连接的阻塞都不会影响到其他连接。
选择多进程还是多线程,并无统一标准,可以视具体场景而定:
进程的开销远大于线程,所以,在连接数较大的情况下,推荐使用多线程。
进程相较于线程具有更高的安全性,所以,如果单个服务执行体需要消耗较多的CPU资源,例如,需要进行大规模或长时间的数据运算或文件访问,推荐使用多进程。
线程池/连接池
当连接数规模继续增大,无论使用多线程,还是多进程,都会严重占据系统资源,降低系统对外界的响应效率,线程或者进程本身也更容易陷入假死。
此时,可以采用“线程池”或“连接池”,来降低创建和销毁进程/线程的频率,减少系统开销。
非阻塞IO模型(NIO)
在有些时候并不希望进程在IO操作未完成时睡眠,而是希望系统调用能够立刻返回一个错误,以报告这一情况,然后进程可以根据需要在适当的时候,再次重新执行这个 IO 操作,这就是所谓的非阻塞IO模型。
与阻塞I/O 不同的是,非阻塞I/O 每隔一段时间,就再次发起系统调用,判断数据是否就绪。
如下图所示:
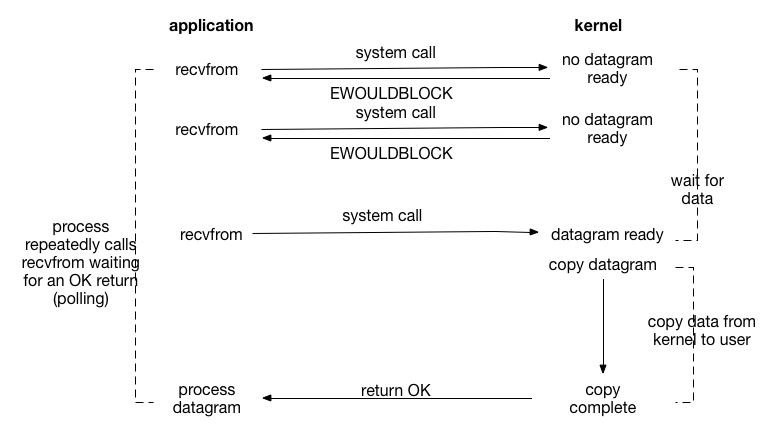
上述过程中,前几次 read 系统调用时,都没有数据可供返回,此时,内核立即返回一个 EAGAIN 错误代码,程序并不睡眠而是继续调用read。
当第四次调用 read 时,数据准备就绪了,于是执行数据从内核到用户空间的复制操作并成功返回,应用程序接着处理数据。
这种对一个非阻塞 IO 端口反复调用 read 进行数据读取的动作称为轮询,即应用程序持续轮询内核数据是否就绪。
这里的持续轮询操作将导致耗费大量 的CPU 时间,因此该模型并不推荐使用。
但这种I/O模型有一个明显的缺陷:
-
首先,非阻塞IO过程中的持续轮询操作,将导致消耗大量的 CPU 时间;
-
其次,轮询过程中,会多次发起系统调用,而系统调用是比较耗时的操作。
IO多路复用模型
I/O 多路复用(也叫做事件驱动I/O)通过系统调用select()、poll()、或者epoll()实现进程同时检查多个文件描述符,以找出其中任何一个是否可执行I/O操作。
IO 多路复用模型就是在异步 IO 之上的改进,它的好处在于:使得应用程序可以同时对多个 IO 端口进行监控,以判断其上的操作是否可以顺利(无阻塞地)完成,达到时间复用的目的。
进程阻塞在类似于select、poll或epoll这样的系统调用上,而不是阻塞在真正的IO系统调用上,也就是说,在这些 select、poll 或者 epoll 函数内部会代替我们做非阻塞地轮询。
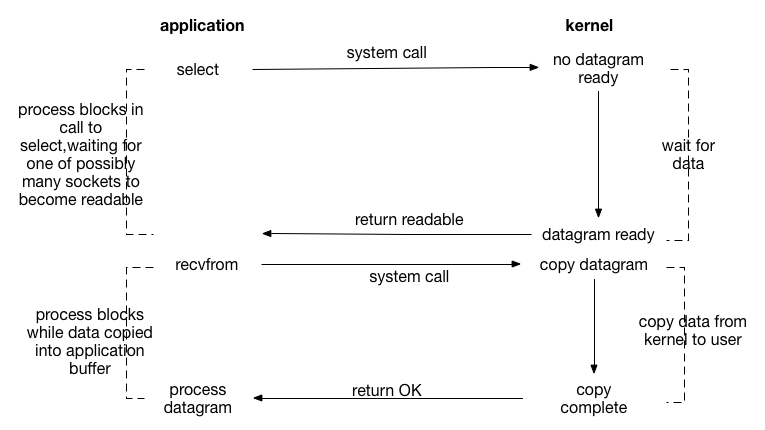
通过上图可以看出I/O多路复用与阻塞I/O模型差别并不大,事实上还要差一些,因为,这里使用了两个系统调用,而阻塞 I/O 只是用了一个系统调用。但是,I/O多路复用的优势是其可以同时处理多个连接。因此,如果处理的连接数不是特别多的情况下,使用I/O多路复用模型的web server,不一定比使用多线程技术的阻塞I/O模型好。
IO多路复用模型主要有3种实现形式,select、poll、epoll。
select() 和 poll() 的原理基本相同:
-
注册待侦听的 fd (这里的fd创建时最好使用非阻塞)
-
每次调用都去检查这些 fd 的状态,当有一个或者多个fd就绪的时候返回
-
返回结果中包括已就绪和未就绪的fd
select
函数原型
select 的函数定义:
int select(int nfds, // 集合中所有文件描述符的范围,即所有文件描述符的最大值+1
fd_set *restrict readfds, // 指向文件描述符集合的指针,检测输入的fds
fd_set *restrict writefds, // 指向文件描述符集合的指针,检测输出的fds
fd_set *restrict exceptfds, // 指向文件描述符集合的指针,异常fds
struct timeval *restrict timeout); // 超时时间
pselect 的函数定义:
int pselect(int nfds, // 最大文件描述符fd+1
fd_set *restrict readfds, // 等待读取的fds
fd_set *restrict writefds, // 等待写入的fds
fd_set *restrict exceptfds, // 异常fds
const struct timespec *restrict timeout, // 超时时间
const sigset_t *restrict sigmask); // 信号掩码
其中,对于 timeval 和 timespec 数据结构:
struct timeval {
long tv_sec;
long tv_usec;
};
struct timespec {
long tv_sec;
long tv_nsec;
};
-
如果结构体中的两个字段均为 0,则表示 select 立即返回;
-
如果结构体中的的任意一个字段不为 0,则表示 select 轮询时经过指定的时间后会返回;
-
如果参数为NULL,则表示 select 会阻塞到有事件就绪才返回;
I/O 事件就绪:此刻执行对应的 I/O 操作,可以无阻塞地完成。例如,读事件就绪,表明一定有数据到达,或者已经读取到了数据的结束位置EOF。
返回值:
-
返回 -1,表示出错
-
返回 0,表示超时,此时每个文件描述符集合都会被清空
-
返回正整数,表示准备就绪的文件描述符个数,如果同一个文件描述符在返回的描述符集中出现多次,select会将其统计多次。
所有关于文件描述符集合的操作,都是通过以下四个宏完成:
void FD_ZERO(fd_set *fdset); // 将fdset所指集合初始化为空
void FD_SET(int fd, fd_set *fdset); // 将文件描述符fd添加到由fdset指向的集合中
void FD_CLR(int fd, fd_set *fdset); // 将文件描述符fd从fdset所指集合中移出
void FD_ISSET(int fd, fd_set *fdset); // 检测fd是否是fdset所指集合成员
当程序发起system call select时流程如下
-
程序阻塞等待kernel返回;
-
kernel发现有 fd 就绪,返回数量;
-
程序轮询 3 个 fd_set 寻找就绪的fd;
-
发起真正的 I/O 操作,如:read、recvfrom等。
select 和 pselect 的差异
| 类别 | select | pselect | 备注 |
|---|---|---|---|
| 超时时间精度 | 微秒级 | 纳秒级 | |
| 是否更新timeout的值 | 更新为剩余轮询时间 | 不会修改 | 从可移植性上考虑,在每次重新调用 select 函数前,最好都再次对参数timeout初始化 |
| 信号掩码 | 无法指定 | 允许指定 | 如果 pselect 第6个参数不为 NULL,则用其先替换当前的信号掩码,然后执行与 select 相同的操作,返回时再还原之前的信号掩码,sigmask参数为null时,两者行为时一致的 |
| 监控的文件描述符数量 | 1024 | 1024 | 在select函数返回时,其保存有指示哪些描述符已经进入就绪状态(此时其对应bit被设置为1,其他未就绪描述符对应bit设置为0),从而程序可以使用宏FD_ISSET来测试描述符集中的就绪描述符。因此,在每次重新调用select函数前都得再次把所有描述符集中关注的fd对应的bit设置为1 |
注意,由于 select 函数监控的最大描述符受到
FD_SETSIZE宏的限制,最多能够监视 1024 个描述符,在高并发情景中,select 是难以胜任的。
select 的优缺点
系统调用 select 的优缺点:
| select | 对比 |
|---|---|
| 优点 |
|
| 缺点 |
|
poll
函数原型
poll 的函数定义:
#include <poll.h>
int poll(struct pollfd *fds, // 待监视的fd构成的pollfd数组:fds[]
nfds_t nfds, // 数组fds[]中元素数量
int timeout); // 轮询时等待的最大超时时间
struct pollfd {
int fd; // 待监视的fd
short events; // 请求监视的事件
short revents; // 实际收到的事件
};
event 类型
每个pollfd结构体指定了一个被监视的文件描述符,可以传递多个结构体,指示poll()监视多个文件描述符。每个结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域的属性。revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域,并且events中请求的任何事件都可能在revents中返回。
pollfd 中可指定的 event 类型包括:
| event类型 | 作用 |
|---|---|
| POLLIN | 普通数据读取 |
| POLLPRI | 紧急数据读取 |
| POLLOUT | 普通数据可写 |
| POLLRDHUP | 面向流的 socket,对端 socket 关闭连接或者关闭了写半连接 |
| POLLERR | 错误 |
| POLLHUP | 挂起 |
| POLLNVAL | 无效请求,fd没有打开 |
如果打开了条件编译宏 _XOPEN_SOURCE,pollfd 中还可以额外指定的 event 类型包括:
| event类型 | 作用 |
|---|---|
| POLLRDNORM | 与 POLLIN 等效 |
| POLLRDBAND | 优先级带数据可读,在 Linux 上通常是无用的; |
| POLLWRNORM | 与 POLLOUT 等效; |
| POLLWRBAND | 优先级数据可写 |
timeout
| timeout参数 | 作用 |
|---|---|
| 值等于-1 | 永远等待,直到监视的 fds 中有一个描述符达到就绪状态 |
| 值大于零 | 等待指定的超时时间后,无论 I/O 是否就绪,都会返回 |
| 值等于零 | poll 不会阻塞,只执行一次检查,看看哪个文件描述符已经就绪 |
select 和 poll 对比
API 设计层面:
| 系统调用 | select | poll |
|---|---|---|
| 超时精度 | 微秒(高) | 毫秒 |
| 超时参数 | 返回时是未定义的,每当下一次调用 select() 之前,需要重新初始化超时参数 | |
| 文件描述符数量 | 不超过1024 | 不限制,通过第二个参数 nfd s来指定 |
| 文件描述符集 | 每当下一次调用 select() 之前,需要重新初始化 fd_set | 通过两个独立的字段 event s和 revents 将监控的输入输出分开,允许被监控的文件数组被复用而不需要重新初始化。 |
性能层面:
-
待检查文件描述符范围较小,或者有大量文件描述符待检查,但是其分布比较密集时,poll() 和select() 性能相似;
-
被检查文件描述符集合很稀疏是,poll() 要优于 select()。
select 和 pol 的不足
-
I/O 效率随着文件描述符的数量增加而线性下降
每次调用 select() 或 poll()是,内核都要检查所有的被指定的文件描述符的状态,但是实际上只有部分的文件描述符会是活跃的,当有文件描述符集合增大时,I/O 的效率也随之下降。
-
当检查大量文件描述符时,用户空间和内核空间消息传递速度较慢
每次调用 select() 或 poll() 时,程序都必须传递一个表示所有需要被检查的文件描述符的数据结构到内核,在内核完成检查之后,修个这个数据结构并返回给程序,此外,select() 每次调用之前,还需要初始化该数据结构。
对于 poll() 调用,需要将用户传入的 pollfd 数组拷贝到内核空间,这是一个复杂度为 \(O(n)\) 的操作。当事件发生后,poll() 将获得的数据传送到用户空间,并执行释放内存和剥离等待队列等,同样复杂度为 \(O(n)\) 的操作,因此随着文件描述符的增加消息传递速度会逐步下降。
-
select() 或 poll() 调用完成之后,程序必须检查返回的数据结构中每个元素,已确定那个文件描述符处于就绪态。
-
select() 对一个进程打开的文件描述符数目有较少
epoll
epoll是一种 I/O 事件通知机制,linux kernel 2.5.44 开始提供这个功能,用于取代 select 和 poll。
epoll 内部结构用红黑树实现,用于监听程序注册的fd,相比于 select 实现的多路复用IO模型,epoll 的最大好处在于:它不会随着监控描述符数目的增长而使效率急剧下降。
函数原型
epoll提供了三种系统调用,如下所示。
#include <sys/poll.h>
// 创建一个 epfd,最多监视 size 个文件描述符
int epoll_create(int size);
int epoll_ctl(int epfd, // epfd
int op, // 操作类型(注册、取消注册)
int fd, // 待监视的fd
struct epoll_event *event); // 待监视的fd上的io事件
int epoll_wait(int epfd, // epfd
struct epoll_event *events, // 最终返回的就绪事件
int maxevents, // 期望的就绪事件数量
int timeout); // 超时时间
int epoll_wait(int epfd, // epfd
struct epoll_event *events, // 接收返回的就绪事件
int maxevents, // 期望的就绪事件数量
int timeout, // 超时时间
const sigset_t *sigmask); // 信号掩码
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; // epoll events
epoll_data_t data; // user data variable
};
事件类型
epoll中可以关注的事件主要有:
| event类型 | 作用 |
|---|---|
| EPOLLIN | 数据可读事件 |
| EPOLLOUT | 数据可写事件 |
| EPOLLRDHUP | 流socket对端关闭连接或者关闭了写半连接 |
| EPOLLPRI | 紧急数据读取事件 |
| EPOLLERR | 错误事件 |
| EPOLLHUP | 挂起事件,epoll总是会等待该事件,不需要显示设置 |
| EPOLLET | 设置epoll以边缘触发模式工作(不指定该选项则使用级别触发Level Trigger模式) |
| EPOLLONESHOT | 设置epoll针对某个fd上的事件只通知一次,一旦epoll通知了某个事件,该fd上后续到达的事件将不会再发送通知,除非重新通过epoll_ctl EPOLL_CTL_MOD更新其关注的事件) |
事件模式
水平触发(Level Triggered)
水平触发(Level Triggered,LT,或级别触发),是 epoll 默认的工作方式,在这种模式下,当描述符从未就绪状态变为就绪状态时,内核会通知使用者哪些文件描述符已经就绪,之后就可以对这些已就绪的文件描述符进行IO操作了。如果进程一直不对这个就绪状态做出任何操作,内核会继续通知使用者,直到事件处理完成
以水平触发方式调用的epoll接口,就相当于一个速度比较快的poll模型。
水平模式的特点:
-
读事件:如果文件描述符对应的读缓冲区还有数据,读事件就会被触发,epoll_wait()解除阻塞
-
当读事件被触发,epoll_wait()解除阻塞,之后就可以接收数据了
-
如果接收数据的buf很小,不能全部将缓冲区数据读出,那么读事件会继续被触发,直到数据被全部读出,如果接收数据的内存相对较大,读数据的效率也会相对较高(减少了读数据的次数)
-
因为读数据是被动的,必须要通过读事件才能知道有数据到达了,因此对于读事件的检测是必须的
-
-
写事件:如果文件描述符对应的写缓冲区可写,写事件就会被触发,epoll_wait()解除阻塞
-
当写事件被触发,epoll_wait()解除阻塞,之后就可以将数据写入到写缓冲区了
-
写事件的触发发生在写数据之前而不是之后,被写入到写缓冲区中的数据是由内核自动发送出去的
-
如果写缓冲区没有被写满,写事件会一直被触发
-
因为写数据是主动的,并且写缓冲区一般情况下都是可写的(缓冲区不满),因此对于写事件的检测不是必须的
-
边缘触发(Edge Triggered)
边缘触发(Edge Triggered,ET),是 epoll 的高速工作方式,只支持非阻塞 socket,在这种工作方式下,当描述符从未就绪状态变为就绪状态时,内核通过epoll告诉进程该描述符有事件发生,之后如果进程一直不对这个就绪状态做出任何操作,内核也不会再发送更多地通知。也就是说,内核仅在该描述符事件到达的那个突变边缘,对进程做出一次通知。
如果我们对这个文件描述符做 I/O 操作,从而导致它再次变成未就绪,当这个未就绪的文件描述符再次变成就绪状态,内核会再次进行通知,并且还是只通知一次。
ET 模式在很大程度上,减少了 epoll 事件被重复触发的次数,因此,其效率要比 LT 模式高。
边沿模式的特点:
-
读事件:当读缓冲区有新的数据进入,读事件被触发一次,没有新数据不会触发该事件
-
如果有新数据进入到读缓冲区,读事件被触发,epoll_wait()解除阻塞
-
读事件被触发,可以通过调用read()/recv()函数将缓冲区数据读出
-
如果数据没有被全部读走,并且没有新数据进入,读事件不会再次触发,只通知一次
-
如果数据被全部读走或者只读走一部分,此时有新数据进入,读事件被触发,并且只通知一次
-
-
-
写事件:当写缓冲区状态可写,写事件只会触发一次
-
如果写缓冲区被检测到可写,写事件被触发,epoll_wait()解除阻塞
-
写事件被触发,就可以通过调用write()/send()函数,将数据写入到写缓冲区中
-
写缓冲区从不满到被写满,期间写事件只会被触发一次
-
写缓冲区从满到不满,状态变为可写,写事件只会被触发一次
-
优缺点
与 select、poll 相比,epoll 具有如下优点:
-
epoll 每次只返回有事件发生的文件描述符信息,这样调用者不用遍历整个文件描述符队列;
-
使用 epoll 使得系统不用从内核向用户空间复制数据,因为它是利用 mmap 使内核和用户空间贡献一块内存;
-
另外 epoll 可以设置不同的事件触发方式,包括边缘触发和级别触发两种,为用户使用epoll提供了灵活性。
epoll 是一种性能很高的同步 I/O 方案。现在 linux 中的高性能网络框架(tomcat、netty等)都有 epoll 的实现。缺点是只有 linux 支持 epoll ,BSD内核的 kqueue 类似于 epoll。
实时信号驱动 IO 模型
信号驱动 I/O 并不常用,它是一种半异步的 I/O 模型。在使用信号驱动 I/O 时,当数据准备就绪后,内核通过发送一个 SIGIO 信号通知应用进程,应用进程就可以开始读取数据了。
使用信号驱动式I/O模型的主要优点是在等待数据到达期间,进程不会被阻塞。实时信号驱动IO完全不是在select/poll基础上的修改,而是对传统信号驱动IO的完善,因此它是完全不同于前面介绍的几种解决方案的事件驱动IO机制。
实时信号驱动 IO 模型,使得应用程序不需要阻塞在某一个或多个IO端口上,它先利用系统调用 sigaction 来安装某个端口的事件信号处理函数,该系统调用 sigaction 执行成功后立即返回,进程继续往下工作而不被阻塞,当某个 IO 端口上可进行数据操作时,内核就为该进程产生一个 SIGIO 信号,进程收到该信号后,相应地在信号处理函数里进行 IO 操作。
因此,这种机制使得程序能够在一个更合适的时间点被通知到,进而去执行 IO 事件处理,之所以说是通知的时间点更好,是因为此时进行 IO 需要的数据已就绪,IO 处理可以保证无阻塞地完成。
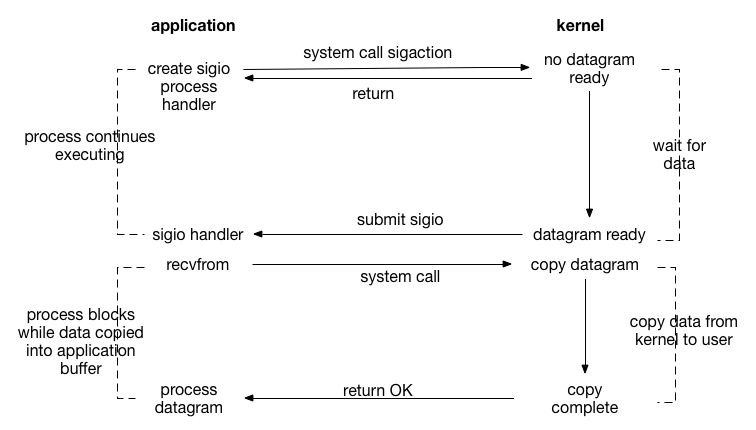
信号驱动 I/O 中,当文件描述符上可执行 I/O 操作时,进程请求内核为自己发送一个信号,之后进程可以执行其他任务直到 I/O 就绪为止,此时内核会发送信号给进程。
建立一个针对套接字的信号驱动 式I/O 需要进程执行以下三个步骤:
-
建立 SIGIO 信号处理函数
-
设置该套接字的属主,通常使用 fcntl 的F_SETOWN 命令设置
-
开启该套接字的信号驱动式 I/O,通常通过使用 fcnt 的 F_SETFL 命令打开 O_ASYNC 标志完成
信号驱动式I/O的应用
信号驱动式I/O 在 UDP 上的应用
对于UDP上的使用比较简单,SIGIO 信号只有在数据报到达套接字或者套接字发生异步错误时产生。
因此,当捕获对于某个 UD P套接字的 SIGIO 信号时,我们调用recvfrom或者读入到达的数据报或者获取发生的异步错误。
信号驱动式I/O 在 TCP 上的应用
信号驱动式 I/O 对于TCP套接字几乎无用,主要原因是SIGIO信号产生会过于频繁,并且其出现并没有告知我们发生了什么事件。
比如,当一个进程既读又写一个 TCP 套接字时,当有数据到达或者当前写出的数据得到确认时,SIGIO信号都会产生,而信号处理函数无法区分这两种情况。
应该只考虑对监听TCP套接字使用SIGIO,因为对于监听TCP套接字产生SIGIO的唯一条件是某个新连接的完成。
实际上,I/O 多路复用、信号驱动 I/O 以及 epoll 都是用来实现同一个目标的技术:同时检查多个文件描述符是否准备好执行I/O操作,准确的说是看I/O系统调用是否可以非阻塞地执行。
文件描述符就绪状态的转化,是通过一些 I/O 事件来触发的,如输入数据到达、套接字连接建立完成,或者是之前满载的套接字发送缓冲区,在TCP将队列中的数据传送到对端之后有了剩余空间。但是以上这三种技术都不会实际执行 I/O 操作,只会告诉我们某个文件描述符已经处于就绪状态,此时,我们还需要调用其他系统调用来实际完成 I/O 操作。
异步 IO 模型
异步 I/O 最重要的一点是从内核缓冲区拷贝数据到用户态缓冲区的过程也是由系统异步完成,应用进程只需要在指定的数组中引用数据即可。
异步 I/O 与信号驱动 I/O 这种半异步模式的主要区别:信号驱动 I/O 由内核通知何时可以开始一个 I/O 操作,而异步 I/O 由内核通知 I/O 操作何时已经完成。
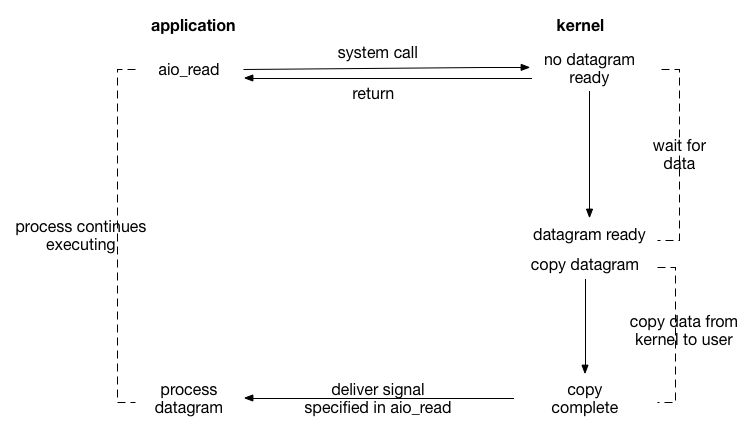
Linux AIO 可选的方案:
-
使用线程池封装同步 IO 线程
优点:这适用于较多场景,并且可能更容易编程。与 AIO 不同的是,所有函数都可以通过线程池并行化。
缺点:由于上下文切换带来的 CPU 和内存带宽使用方面的线程开销,线程池无法正常工作,对于高性能存储设备上的小随机读取,这是一个特别大的问题。
-
POSIX AIO
它是 glibc 中的 AIO 实现,然而,为了可移植性,glibc 内部使用了线程池实现。对于可以接受的情况,建议使用自己的线程池实现。
-
Linux AIO system call
内核实现的 Linux asynchronous I/O 系统调用。
POSIX AIO API
POSIX AIO 接口允许应用程序发起一个或者多个IO操作,这些IO操作是异步执行的,即相比于当前发起IO操作的线程来说这些实际的IO操作是在“后台”运行的。IO操作完成时,可以选择多种方式来通知应用程序完成这一事件,例如:
-
传递一个信号给应用程序通知其IO操作完成;
-
在应用程序中额外实例化一个线程来对IO完成操作进行后处理;
-
也可能根本不会通知应用程序。
前面提到的 rtsig driven io 也可以算是异步的,也可以称其为AIO(Asynchronous IO),但是,这里所提到的 AIO 主要指的是 POSIX 规范里面定义的 POSIX AIO API。
POSIX AIO API
POSIX AIO 接口由以下函数组成:
| POSIX AIO interface | 作用 |
|---|---|
| aio_read(3) | 入队一个 read 请求,它是 read() 的异步操作版本 |
| aio_write(3) | 入队一个 write 请求,它是 write() 的异步操作版本 |
| aio_fsync(3) | 入队一个 sync 请求,它是 fsync() 和 fdatasync() 的异步版本 |
| aio_error(3) | 获取一个已入队的 IO 请求的错误状态信息 |
| aio_return(3) | 获取一个已完成的 IO 请求的返回状态信息 |
| aio_suspend(3) | 挂起 IO 请求的发起者,直到指定的一个或多个 I O事件完成 |
| aio_cancel(3) | 尝试取消已经发起的某个特定 fd 上的未完成的 IO 请求 |
| lio_listio(3) | 通过一次函数调用,入队多个 IO 请求 |
其中,上述 API 后面括号中的数字的含义:
- 2 System calls: Functions which wrap operations performed by the kernel.
- 3 Library calls: All library functions excluding the system call wrappers(Most of the libc functions).
注意,上述几个函数都是用户态的 libc 库函数,而不是系统调用。
Linux AIO 系统调用
前面提到的用户态 POSIX AIO API 主要是基于 Linux asynchronous I/O 系统调用来实现的,分别是:
io_setup
io_setup(2) 函数原型:
int io_setup(unsigned nr_events, aio_context_t *ctx_idp)
该函数在内核中为进程创建一个 AIO Context,AIO Context 是多个数据结构的集合,用于支持内核的AIO操作。
每一个进程可以拥有多个AIO Context,每一个AIO Context都有一个唯一的标识符,AIO Context类型 aio_context_t 变量作为 io_setup 的第二个参数,内核会设置其对应的值,实际上这个aio_context_t类型仅仅是一个unsigned long类型,io_setup的第一个参数表示aio_context_t变量要支持的同时发起的IO请求的数量。
io_destroy
io_destroy(2) 函数原型:
int io_destroy(aio_context_t ctx_id)
该函数用于销毁AIO Context变量,销毁之前有两个操作:
-
首先,取消基于该 aio_context_t 发起的未完成的AIO请求;
-
然后,对于无法取消的 AIO 请求就阻塞当前进程等待其执行完成,最后销毁 AIO Context。
io_submit
io_submit(2) 函数原型:
int io_submit(aio_context_t ctx_id, long nr, struct iocb **iocbpp)
该函数将向 aio_context_t ctx_id 上提交 nr 个 IO 请求,每个 IO 请求是由一个 aio control block 来指示的,第三个参数 iocbpp 是一个 aio 控制块的指针数组。
io_getevents
io_getevents(2) 函数原型:
int io_getevents(aio_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout)
等待 aio_context_t ctx_id 关联的 aio 请求已完成队列中返回最少 min_nr 个事件,最多 nr 个事件,如果指定了 timeout 则最多等待该指定的时间,如果 timeout 为 NULL,则至少等待 min_nr 个事件返回。
io_cancel(2)
io_cancel(2) 函数原型:
int io_cancel(aio_context_t ctx_id, struct iocb *iocb, struct io_event *result)
该函数取消之前提交到 aio_context_t ctx_id 的一个 AIO 请求,这个请求由 iocb 标识,如果这个 AIO 请求成功取消了,对应的事件将被拷贝到第三个参数 result 指向的内存中,而不是将其放在已完成队列中。
AIO 的应用场景
Kernel AIO 才是真正的异步 IO,而 glibc 中的 AIO 是在用户态中实现的,它是利用多线程来模拟的异步通知,但是,这个线程里面的 io 操作并不是真正的异步。Kernel AIO 更多的被应用于 file io,而不是 socket io。
Blocking during io_submit on ext4, on buffered operations, network access, pipes, etc. Some operations are not well-represented by the AIO interface. With completely unsupported operations like buffered reads, operations on a socket or pipes, the entire operation will be performed during the io_submit syscall, with the completion available immediately for access with io_getevents.
--摘自 github linux-aio
由于 Asynchronous IO 模型比事件驱动的 IO 模型要晚,AIO 并不适合在网络 IO 场景下使用,现在,几乎大部分网络服务器都是基于 POSIX 事件驱动模型,而且,事件驱动的 IO 模型已经非常成熟、稳定,借助于 kqueue、epoll、/dev/poll 等,已经可以实现非常高效的 socket io 操作了。
因此,如果要基于 socket 开发高性能 server,应该首先考虑事件驱动的 IO 模型,如,Linux 下的 epoll,Mac OS X下的 kqueue,Solaris 下的/dev/poll。
无缓冲 Disk Direct IO
通常情况下,磁盘写入一般会使用缓冲机制,磁盘读取一般会使用预取机制。
例如,在 linux 中,磁盘写操作通常都会被 kernel 进行缓冲,将写的数据存在缓冲块中,然后,在后面适当的时机,将缓冲区的数据,全部 flush 到磁盘,这通常由一个额外的进程来完成,linux 0.11 中是由 pid = 2 的 update 进程来负责同步缓冲块数据到磁盘。flush 的时机,可以由内核进行选择,以获得最优的效率、最少的代价刷新到磁盘,例如,当磁盘的读写磁头,经过某一个磁盘写请求对应的磁盘块时,内核可能就会将这个块对应的缓冲块的数据同步回磁盘。
AIO 最适用的场景就是 Disk Direct IO 这种不带缓冲形式的操作,而 Disk Direct IO 仅仅被用于事务数据库,或是那些趋向于自己编写线程或者进程来管理disk io的情景。
本文总结
以上对阻塞IO、非阻塞IO、IO多路复用、实时信号驱动IO、异步IO这5种模型的执行流程、使用方式做了最基本的介绍。如果时间充足,后面会参考Linux内核中的相应实现进一步介绍以上IO模型的实现细节。
附录
代码示例
select 示例
【select 代码示例】
// 可读、可写、异常3种文件描述符集的声明和初始化
fd_set readfds, writefds, exceptfds;
FD_ZERO(&readfds);
FD_ZERO(&writefds);
FD_ZERO(&exceptfds);
int max_fd;
// socket配置和监听
int sock = socket(...);
bind(sock, ...);
listen(sock, ...);
// 对socket描述符上关心的事件进行注册,select不要求fd非阻塞
FD_SET(sock, &readfds);
max_fd = sock;
while(1) {
int i;
fd_set r, w, e;
// 为了重复使用readfds、writefds、exceptionfds,将他们复制到临时变量内
memcpy(&r, &readfds, sizeof(fd_set));
memcpy(&w, &writefds, sizeof(fd_set));
memcpy(&e, &exceptfds, sizeof(fd_set));
// 利用临时变量调用select阻塞等待,等待时间为永远等待直到事件发生
select(max_fd+1, &r, &w, &e, NULL);
// 测试是否有客户端发起连接请求,如果有则接受并把新建的描述符加入监控
if(FD_ISSET(sock, &r)) {
new_sock = accept(sock, ...);
FD_SET(new_sock, &readfds);
FD_SET(new_sock, &writefds);
max_fd = MAX(max_fd, new_sock);
}
// 对其他描述符上发生的事件进行适当处理
// 描述符依次递增,各系统的最大值可能有所不同,一般可以通过ulimit -n进行设置
for(i=sock+1; i<max_fd+1; ++i) {
if(FD_ISSET(i, &r)) {
doReadAction(i);
}
if(FD_ISSET(i, &w)) {
doWriteAction(i);
}
}
}
poll 代码示例
【poll 代码示例】
// 新建并初始化文件描述符集
struct pollfd fds[MAX_NUM_FDS];
int max_fd;
// socket配置和监听
sock = socket(...);
bind(sock, ...);
listen(sock, ...);
// 对socket描述符上关心的事件进行注册
fds[0].fd = sock;
fds[0].events = POLLIN;
max_fd = 1;
while(1) {
int i;
// 调用poll阻塞等待,等待时间为永远等待直到事件发生
poll(fds, max_fd, -1);
// 测试是否有客户端发起连接请求,如果有则接受并把新建的描述符加入监控
if(fds[0].revents & POLLIN) {
new_sock = accept(sock, ...);
fds[max_fd].fd = new_sock;
fds[max_fd].events = POLLIN | POLLOUT;
++ max_fd;
}
// 对其他描述符发生的事件进行适当处理
for(i=1; i<max_fd+1; ++i) {
if(fds[i].revents & POLLIN) {
doReadAction(i);
}
if(fds[i].revents & POLLOUT) {
doWriteAction(i);
}
}
}
epoll 代码示例
【epoll 代码示例】
// 创建并初始化文件描述符集
struct epoll_event ev;
struct epoll_event events[MAX_EVENTS];
// 创建epoll句柄epfd
int epfd = epoll_create(MAX_EVENTS);
// 监听socket配置
sock = socket(...);
bind(sock, ...);
listen(sock, ...);
// 对socket描述符上关心的事件进行注册
ev.events = EPOLLIN;
ev.data.fd = sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, sock, &ev);
while(1) {
int i;
// 调用epoll_wait阻塞等待,等待事件未永远等待直到发生事件
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
for(i=0; i<n; ++i) {
// 测试是否有客户端发起连接请求,如果有则接受并把新建的描述符加入监控
if(events[i].data.fd == sock) {
if(events[i].events & EPOLLIN) {
new_sock = accept(sock, ...);
ev.events = EPOLLIN | EPOLLOUT;
ev.data.fd = new_sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, new_sock, &ev);
}
}
else {
// 对于其他描述符上发生的事件进行适当处理
if(events[i].events & EPOLLIN) {
doReadAction(i);
}
if(events[i].events & EPOLLOUT) {
doWriteAction(i);
}
}
}
}
信号驱动 I/O 代码示例
【RTSIG IO 代码示例】
下面给出了一个利用RTSIG IO的编程范例。
// 屏蔽不关心的信号
sigset_t all;
sigfillset(&all);
sigdelset(&all, SIGINT);
sigprocmask(SIG_SETMASK, &all, NULL);
// 新建并初始化关心的信号
sigset_t sigset;
siginfo_t siginfo;
// sigwaitinfo调用时会阻塞,除非收到wait的信号集中的某个信号
sigemptyset(&sigset);
sigaddset(&sigset, SIGRTMIN + 1);
// socket配置和监听
sock = socket(...);
bind(sock, ...);
listen(sock, ...);
// 重新设置描述符可读写时要发送的信号值
fcntl(sock, F_SETSIG, SIGRTMIN + 1);
// 对socket描述符设置所有者
fcntl(sock, F_SETOWN, getpid());
// 启用描述符的信号驱动IO模式
int flags = fcntl(sock, F_GETFL);
fcntl(sock, F_SETFL, flags|O_ASYNC|O_NONBLOCK);
while(1) {
struct timespec ts;
ts.tv_sec = 1;
ts.tv_nsec = 0;
// 调用sigtimedwait阻塞等待,等待事件1s & sigwaitinfo会一直阻塞
// - 通过这种方式可以达到一种类似级别触发的效果,不再是边缘触发;
// - 边缘触发效果,应该通过同一个sighandler进行处理,但是处理起来比较麻烦:
// - 假如不同的连接socket使用相同的信号,那么sighandler里无法区分事件就绪的fd;
// - 假如不同的连接socket使用不同的信号,实时信号数量有限SIGRTMIN~SIGRTMAX大约才32个!
//sigtimedwait(&sigset, &siginfo, &ts);
sigwaitinfo(&sigset, &siginfo);
// 测试是否有客户端发起连接请求
if(siginfo.si_fd == sock) {
new_sock = accept(sock, ...);
fcntl(new_sock, F_SETSIG, SIGRTMIN + 1);
fcntl(new_sock, F_SETOWN, getpid() + 1);
fcntl(new_sock, F_SETFL, O_ASYNC|O_NONBLOCK|O_RDWR);
}
// 对其他描述符上发生的读写事件进行处理
else {
doReadAction(i);
doWriteAction(i);
}
}
Kernel AIO 系统调用
下面是一个基于内核AIO系统调用的一个示例,程序打开一个本地文件,并将一段缓冲区中的数据写入到文件中。
#define _GNU_SOURCE /* syscall() is not POSIX */
#include <stdio.h> /* for perror() */
#include <unistd.h> /* for syscall() */
#include <sys/syscall.h> /* for __NR_* definitions */
#include <linux/aio_abi.h> /* for AIO types and constants */
#include <fcntl.h> /* O_RDWR */
#include <string.h> /* memset() */
#include <inttypes.h> /* uint64_t */
inline int io_setup(unsigned nr, aio_context_t * ctxp)
{
return syscall(__NR_io_setup, nr, ctxp);
}
inline int io_destroy(aio_context_t ctx)
{
return syscall(__NR_io_destroy, ctx);
}
inline int io_submit(aio_context_t ctx, long nr, struct iocb **iocbpp)
{
return syscall(__NR_io_submit, ctx, nr, iocbpp);
}
inline int io_getevents(aio_context_t ctx,
long min_nr, long max_nr,
struct io_event *events,
struct timespec *timeout)
{
return syscall(__NR_io_getevents, ctx, min_nr, max_nr, events, timeout);
}
int main()
{
int fd = open("./testfile", O_RDWR|O_CREAT, S_IRUSR|S_IWUSR);
if (fd < 0) {
perror("open error");
return -1;
}
// init aio context
aio_context_t ctx = 0;
int ret = io_setup(128, &ctx);
if (ret < 0) {
perror("io_setup error");
return -1;
}
// setup I/O control block
struct iocb cb;
memset(&cb, 0, sizeof(cb));
cb.aio_fildes = fd;
cb.aio_lio_opcode = IOCB_CMD_PWRITE;
// command-specific options
char data[4096] = "i love you, dad!\n";
cb.aio_buf = (uint64_t) data;
cb.aio_offset = 0;
cb.aio_nbytes = strlen(data);
struct iocb *cbs[1];
cbs[0] = &cb;
ret = io_submit(ctx, 1, cbs);
if (ret != 1) {
if (ret < 0)
perror("io_submit error");
else
fprintf(stderr, "could not sumbit IOs");
return -1;
}
// get the reply
struct io_event events[1];
ret = io_getevents(ctx, 1, 1, events, NULL);
printf("%d io ops completed\n", ret);
ret = io_destroy(ctx);
if (ret < 0) {
perror("io_destroy error");
return -1;
}
return 0;
}
POSIX AIO API 代码示例
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <aio.h>
#include <signal.h>
// Size of buffers for read operations
#define BUF_SIZE 20
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); } while (0)
#define errMsg(msg) do { perror(msg); } while (0)
/* Application-defined structure for tracking I/O requests */
struct ioRequest {
int reqNum;
int status;
struct aiocb *aiocbp;
};
// On delivery of SIGQUIT, we attempt to cancel all outstanding I/O requests
static volatile sig_atomic_t gotSIGQUIT = 0;
// Handler for SIGQUIT
static void quitHandler(int sig) { gotSIGQUIT = 1; }
// Signal used to notify I/O completion
#define IO_SIGNAL SIGUSR1
// Handler for I/O completion signal
static void aioSigHandler(int sig, siginfo_t *si, void *ucontext)
{
if (si->si_code == SI_ASYNCIO) {
write(STDOUT_FILENO, "I/O completion signal received\n", 31);
// The corresponding ioRequest structure would be available as:
// struct ioRequest *ioReq = si->si_value.sival_ptr;
//
// and the file descriptor would then be available via:
// int fd = ioReq->aiocbp->aio_fildes;
}
}
int main(int argc, char *argv[])
{
if (argc < 2) {
fprintf(stderr, "Usage: %s <pathname> <pathname>...\n", argv[0]);
exit(EXIT_FAILURE);
}
int numReqs = argc - 1; // Total number of queued I/O requests, i.e, num of files listed on cmdline
/* Allocate our arrays */
struct ioRequest *ioList = calloc(numReqs, sizeof(struct ioRequest));
if (ioList == NULL) errExit("calloc");
struct aiocb *aiocbList = calloc(numReqs, sizeof(struct aiocb));
if (aiocbList == NULL) errExit("calloc");
// Establish handlers for SIGQUIT and the I/O completion signal
// - SIGQUIT
struct sigaction sa;
sa.sa_flags = SA_RESTART;
sigemptyset(&sa.sa_mask);
sa.sa_handler = quitHandler;
if (sigaction(SIGQUIT, &sa, NULL) == -1) errExit("sigaction");
// - IO_SIGNAL, actually it's SIGUSR1
sa.sa_flags = SA_RESTART | SA_SIGINFO;
sa.sa_sigaction = aioSigHandler;
if (sigaction(IO_SIGNAL, &sa, NULL) == -1) errExit("sigaction");
// Open each file specified on the command line, and queue a read request
// on the resulting file descriptor
int j;
for (j = 0; j < numReqs; j++) {
ioList[j].reqNum = j;
ioList[j].status = EINPROGRESS;
ioList[j].aiocbp = &aiocbList[j];
ioList[j].aiocbp->aio_fildes = open(argv[j + 1], O_RDONLY);
if (ioList[j].aiocbp->aio_fildes == -1) errExit("open");
printf("opened %s on descriptor %d\n", argv[j + 1], ioList[j].aiocbp->aio_fildes);
ioList[j].aiocbp->aio_buf = malloc(BUF_SIZE);
if (ioList[j].aiocbp->aio_buf == NULL) errExit("malloc");
ioList[j].aiocbp->aio_nbytes = BUF_SIZE;
ioList[j].aiocbp->aio_reqprio = 0;
ioList[j].aiocbp->aio_offset = 0;
ioList[j].aiocbp->aio_sigevent.sigev_notify = SIGEV_SIGNAL;
ioList[j].aiocbp->aio_sigevent.sigev_signo = IO_SIGNAL;
ioList[j].aiocbp->aio_sigevent.sigev_value.sival_ptr = &ioList[j];
int s = aio_read(ioList[j].aiocbp);
if (s == -1) errExit("aio_read");
}
// Number of requests still in progress
int openReqs = numReqs;
// Loop, monitoring status of I/O requests
while (openReqs > 0) {
sleep(3); /* Delay between each monitoring step */
if (gotSIGQUIT) {
// On receipt of SIGQUIT, attempt to cancel each of the
// outstanding I/O requests, and display status returned from the
// cancellation requests
printf("got SIGQUIT; canceling I/O requests: \n");
for (j = 0; j < numReqs; j++) {
if (ioList[j].status == EINPROGRESS) {
printf("Request %d on descriptor %d:", j, ioList[j].aiocbp->aio_fildes);
int s = aio_cancel(ioList[j].aiocbp->aio_fildes, ioList[j].aiocbp);
if (s == AIO_CANCELED)
printf("I/O canceled\n");
else if (s == AIO_NOTCANCELED)
printf("I/O not canceled\n");
else if (s == AIO_ALLDONE)
printf("I/O all done\n");
else
errMsg("aio_cancel");
}
}
gotSIGQUIT = 0;
}
// Check the status of each I/O request that is still in progress
printf("aio_error():\n");
for (j = 0; j < numReqs; j++) {
if (ioList[j].status == EINPROGRESS) {
printf("for request %d (descriptor %d): ", j, ioList[j].aiocbp->aio_fildes);
ioList[j].status = aio_error(ioList[j].aiocbp);
switch (ioList[j].status) {
case 0:
printf("I/O succeeded\n");
break;
case EINPROGRESS:
printf("In progress\n");
break;
case ECANCELED:
printf("Canceled\n");
break;
default:
errMsg("aio_error");
break;
}
if (ioList[j].status != EINPROGRESS) openReqs--;
}
}
}
printf("All I/O requests completed\n");
// Check status return of all I/O requests
printf("aio_return():\n");
for (j = 0; j < numReqs; j++) {
ssize_t s = aio_return(ioList[j].aiocbp);
printf("for request %d (descriptor %d): %zd\n", j, ioList[j].aiocbp->aio_fildes, s);
}
exit(EXIT_SUCCESS);
}
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号