单调栈及其应用
单调栈
简介
单调栈,是一种特殊的栈,在栈的「先进后出」规则基础上,要求从栈顶到栈底的元素是单调递增(或者单调递减)。
这里,我们统一约定,满足从栈底到栈顶的元素是单调递增的栈,叫做单调递增栈;满足从栈底到栈顶的元素是单调递减的栈,叫做单调递减栈。
例如,栈中自顶向下的元素为 \(\{0,11,45,81\}\):
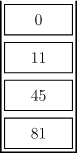
这是一个单调递减栈,在往栈中插入元素 \(14\) 时,为了保证单调性需要先依次弹出元素 \(0,11\):
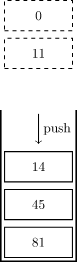
操作后栈中的元素变为 \(\{14,45,81\}\)。
伪代码
insert x
while !stack.empty() && stack.top() < x
stack.pop()
stack.push(x)
应用
这里,我们挑选了力扣上部分典型的单调栈相关的题目,来介绍单调栈的应用。相关的题目如下:
| 序号 | 题目 | 难度 | 备注 |
|---|---|---|---|
| 1 | 496. 下一个更大元素 I | 简单 | |
| 2 | 503. 下一个更大元素 II | 中等 | |
| 3 | 2454. 下一个更大元素 IV | 困难 | |
| 4 | 739. 每日温度 | 中等 | |
| 5 | 316. 去除重复字母 | 中等 | |
| 6 | 901. 股票价格跨度 | 中等 | |
| 7 | 402. 移掉 K 位数字 | 中等 | |
| 8 | 581. 最短无序连续子数组 | 中等 | |
| 9 | 42. 接雨水 | 困难 | |
| 10 | 84. 柱状图中最大的矩形 | 困难 | |
| 11 | 321. 拼接最大数 | 困难 |
应用1:Leetcode.496
题目
分析
我们可以维护一个 hash 表 \(map\) ,用于记录 \(nums2\) 中每一个元素的下一个更大的元素。
查找 \(nums2\) 中的每个元素的右侧下一个更大的元素,可以使用维护一个单调递减栈 \(stack\),然后,倒序遍历 \(nums2\) 中的元素,每个新的元素入栈前,先依次弹出栈顶小于等于该元素的值的元素,这样,栈顶的元素就是下一个更大的元素。
然后,再遍历 \(nums1\) 中的元素,以其作为 key,得到每个元素的下一个更大元素。
注意:因为我们需要寻找 \(nums2\) 右侧更大的元素,因此,我们需要倒序遍历,以保证当前元素右侧的元素先于当前元素入栈。
代码实现
【Java 实现】
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Map<Integer, Integer> map = new HashMap<>();
Deque<Integer> stack = new ArrayDeque<>();
// 维护一个单调栈,记录每个元素右侧第一个大于当前元素的值
for (int i = nums2.length - 1; i >= 0; i--) {
while (!stack.isEmpty() && nums2[i] >= stack.peek()) {
stack.pop();
}
map.put(nums2[i], stack.isEmpty() ? -1: stack.peek());
stack.push(nums2[i]);
}
int [] result = new int[nums1.length];
for (int i = 0; i < nums1.length; i++) {
result[i] = map.get(nums1[i]);
}
return result;
}
}
【Python 实现】
class Solution:
def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[int]:
result = {}
stack = []
for num in reversed(nums2):
while stack and num >= stack[-1]:
stack.pop()
result[num] = stack[-1] if stack else -1
stack.append(num)
return [result[num] for num in nums1]
复杂度分析
我们假设 \(nums1\) 的长度为 \(m\), \(nums2\) 的长度为 \(n\),那么:
- 时间复杂度:\(O(m + n)\);
- 空间复杂度:\(O(n)\)。
应用2:Leetcode.503
题目
分析
对于循环数组,比较朴素的做法是将长度为 \(n\) 的数组直接复制为长度为 \(2n\) 的数组,即:
对于这个新的数组,我们直接对其倒序遍历,维护一个单调递减栈 \(stack\),保证右侧的元素始终先于当前元素进入栈底。
我们用一个长度为 \(n\) 的数组 \(result\),记录原数组的每个位置对应的下一个更大元素。
需要注意的是,遍历过程中,当元素序号大于 \(n - 1\) 时,记录结果的时候,需要对 \(n\) 取模。
这样,相当于对原始的数组倒序遍历了两次,保证每个元素在查找下一个右侧的最大元素的时候,所有的元素都参与了比较。
注意:新数组的最后一个元素的下标索引是 \(2n - 1\)。
代码实现
【Java实现】
class Solution {
public int[] nextGreaterElements(int[] nums) {
Deque<Integer> stack = new ArrayDeque<>();
int n = nums.length;
int [] result = new int[n];
for (int i = n * 2 - 1; i >= 0; i--) {
while ( (!stack.isEmpty()) && stack.peek() <= nums[i % n]) {
stack.pop();
}
if (stack.isEmpty()) {
result[i % n] = -1;
} else {
result[i % n] = stack.peek();
}
stack.push(nums[i % n]);
}
return result;
}
}
class Solution:
def nextGreaterElements(self, nums: List[int]) -> List[int]:
stack = list()
n = len(nums)
result = [-1] * n
for i in range(2 * n - 1, -1, -1):
while stack and stack[-1] <= nums[i % n]:
stack.pop()
if stack:
result[i % n] = stack[-1]
else:
result[i % n] = -1
stack.append(nums[i % n])
return result
应用4:Leetcode.2454
题目
分析
题目中第二大的整数,表示大于当前元素,且小于当前元素右侧第一大的整数。
对于数组中的每一个元素,依次正序遍历,通过维护一个单调递减栈 \(stack\),栈里面保存还没有找到更大元素的数字的下标。
同时,维护一个优先级队列 \(heap\),堆中存放所有已经找到下一个更大元素的元素及其下标,即 \((nums[i], \ i)\),因此,当堆顶的元素再遇到一个大于它的元素时,该元素就是它的第二大的整数。
算法步骤:
- 正序遍历数组 \(nums\) ,对于当前元素 \(nums[i]\),如果它大于堆顶的元素,则将堆顶的元素弹出,并将\(nums[i]\)设置为它的第二大元素;
- 如果当前元素大于栈顶的元素,则将栈顶的元素弹出,并将弹出的元素压入堆中;
- 将当前元素的下标入栈;
代码实现
【Java实现】
class Solution {
public int[] secondGreaterElement(int[] nums) {
int[] result = new int[nums.length];
Arrays.fill(result, -1);
// 维护一个单调递增栈
Deque<Integer> stack = new ArrayDeque<>();
// 维护一个堆,用于保存单调栈弹出的元素
PriorityQueue<int []> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
// 顺序遍历数组
for (int i = 0; i < nums.length; i++) {
// 如果堆顶元素小于当前元素,说明堆顶的元素又遇到一个大于它的元素了
while (!pq.isEmpty() && pq.peek()[0] < nums[i]) {
result[pq.poll()[1]] = nums[i];
}
// 单调递增栈:如果栈顶的元素小于当前元素,就将其弹出,并放入堆中
while (!stack.isEmpty() && nums[stack.peek()] < nums[i]) {
// 此时,堆中的元素已经有一个更大的元素
pq.offer(new int[]{nums[stack.peek()], stack.peek()});
stack.pop();
}
stack.push(i);
}
return result;
}
}
【Python实现】
import heapq
from typing import List
class Solution:
def secondGreaterElement(self, nums: List[int]) -> List[int]:
stack, heap = [], []
result = [-1] * len(nums)
for i, num in enumerate(nums):
while heap and heap[0][0] < num:
_, index = heapq.heappop(heap)
result[index] = num
while stack and nums[stack[-1]] < num:
index = stack.pop()
heapq.heappush(heap, (nums[index], index))
stack.append(i)
return result
应用4:Leetcode.739
题目
分析
由于题目是要找天数,也就是序号之差,所以我们使用单调栈来保存序号。如果是求温度差值,就用单调栈保存温度的值。
从逆序遍历 \(temperatures\) 中所有的元素,使用单调递增栈 \(stack\) 来保存遍历过的元素的序号,保持栈顶元素的序号所对应的温度值始终大于当前元素,否则就将其弹出。
代码实现
【Java实现】
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int[] result = new int[temperatures.length];
Deque<Integer> stack = new ArrayDeque<Integer>();
for (int i = temperatures.length - 1; i >= 0; i--) {
while (!stack.isEmpty() && temperatures[stack.peek()] <= temperatures[i]) {
stack.pop();
}
if (!stack.isEmpty()) {
result[i] = stack.peek() - i;
}
stack.push(i);
}
return result;
}
}
【Python实现】
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
result = [0 for _ in range(len(temperatures))]
stack = list()
# 从右往左遍历,对每一个元素,找到第一个大于它的序号
for i in range(len(temperatures) - 1, -1, -1):
# 如果当前元素大于栈顶的元素,则将其序号出栈
while stack and temperatures[i] >= temperatures[stack[-1]]:
stack.pop()
# 保存第一个大于当前元素的序号
result[i] = stack[-1] - i if stack else 0
# 将当前元素入栈
stack.append(i)
return result
应用5:Leetcode.316
题目
分析
题目的要求是,去掉重复元素的同时,同时要维持原有的字符的顺序,并且,还要保证结果是最小字典序。
我们可以先对目标字符串预处理,记录下所有元素出现的次数,保证遍历过程中字符不会丢失。
那么,我们可以遍历目标字符串,在遍历时,依次对当前元素的出现次数递减,同时维护栈,栈顶的元素是否弹出,取决于:
- 如果栈顶的元素大于当前字符,并且,后续还会出现,那么就就可以弹出;
- 如果栈顶的元素大于当前字符,但是,后续不会出现了,那么就不能弹出;
注意:我们维护的并不是一个单调栈,例如,输入"bcac",结果是"bac"。
代码实现
【Java实现】
class Solution {
public String removeDuplicateLetters(String s) {
// 维护一个栈来记录结果
Deque<Character> stack = new ArrayDeque<>();
// 记录字符是否出现过
Set<Character> visit = new HashSet<>();
// 记录字符出现的次数
int [] count = new int[26];
for (int i = 0; i < s.length(); i++) {
count[s.charAt(i) - 'a']++;
}
for (int i = 0; i < s.length(); i++) {
// 遍历一个字符次数就减一
char ch = s.charAt(i);
count[ch - 'a']--;
// 如果该字符已经访问过,就不处理了
if (visit.contains(ch)) {
continue;
}
// 如果栈不为空,并且栈顶的元素比当前元素大,就出栈
while (!stack.isEmpty() && stack.peek() > ch) {
if (count[stack.peek() - 'a'] == 0) {
break;
}
char candidate = stack.pop();
visit.remove(candidate);
}
// 将当前元素入栈
stack.push(ch);
visit.add(ch);
}
// 栈里面元素顺序是反的,需要做一次倒序
StringBuilder sb = new StringBuilder();
while(!stack.isEmpty()) {
sb.append(stack.pop());
}
return sb.reverse().toString();
}
}
【Python实现】
from collections import defaultdict
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
# 维护一个单调栈来记录结果
stack = list()
visit = set()
# 记录字符出现的次数
count = defaultdict(int)
for char in s:
count[char] = count.get(char, 0) + 1
for char in s:
# 1.遍历一个字符,就减1
count[char] -= 1
# 2.如果该字符已经访问过,就不处理了
if char in visit:
continue
# 3.如果栈不为空,并且栈顶的元素比当前元素大,就出栈
while stack and stack[-1] > char:
if count[stack[-1]] == 0:
break
candidate = stack.pop()
visit.remove(candidate)
# 4.将当前元素入栈
stack.append(char)
visit.add(char)
return "".join(stack)
应用6:Leetcode.901
题目
分析
我们可以考虑使用一个单调递减栈来保存每天的股票价格及其日期序号,当某一天的股票价格大于栈顶的元素,则将栈里小于它的所有元素弹出,股票的梯度就是当前的序号与栈顶元素序号的差值。
需要注意的是,如果栈里面所有的元素都被弹出,则表示当天的价格为历史最高价格,此时,因为天数要包含当天的价格,所以,我们将栈顶元素的序号置为 \(-1\)。
代码实现
【Java实现】
class StockSpanner {
private Deque<int[]> stack;
private int index = -1;
public StockSpanner() {
stack = new ArrayDeque<>();
}
public int next(int price) {
index++;
while (!stack.isEmpty() && stack.peek()[0] <= price) {
stack.pop();
}
int result;
if (!stack.isEmpty()) {
result = index - stack.peek()[1];
} else {
result = index + 1 ;
}
stack.push(new int[]{price, index});
return result;
}
}
【Python实现】
import heapq
class StockSpanner:
def __init__(self):
self.stack = list()
self.index = -1 # 记录天数
def next(self, price: int) -> int:
self.index += 1 # 更新天数
# 弹出栈顶小于当前价格的元素
while self.stack and self.stack[-1][0] <= price:
self.stack.pop()
# 如果栈为空,则表示前面连续n-1天都小于当前价格
if not self.stack:
last_day = -1
else:
last_day = self.stack[-1][1]
self.stack.append((price, self.index))
return self.index - last_day
应用7:Leetcode.402
题目
分析
方法:贪心策略 + 单调栈
假设有两个数字,\(A=4axxx\),\(B=4bxxx\),容易看出,如果 \(a \gt b\),则 \(A \gt B\)。
因此,我们可以得出一个简单的结论:如果两个相同长度的数字序列,最左边的不同数字决定了两个数字的大小。
这里,我们使用贪心的思想,要使删除一个数字后,使得剩下的序列尽可能小,那么,就要保证靠前的数字尽可能小。
我们假设 \(num\) 的长度为 \(n\),我们可以从高位到低位遍历数字序列,同时,维护一个单调递增栈 \(stack\)(并非严格递增),对于该数字序列每一个元素,如果栈顶的元素大于当前元素,则说明栈顶的元素需要删除,将其从栈顶弹出,即保留较小的元素。
删除 \(k\) 次后,栈底的 \(n -k\) 个元素,就是剩余数字。
代码实现
class Solution:
def removeKdigits(self, num: str, k: int) -> str:
stack = list()
remain = len(num) - k
for digit in num:
while k and stack and stack[-1] > digit:
stack.pop()
k -= 1
stack.append(digit)
result = "".join(stack[:remain]).lstrip("0")
return result or "0"
应用8:Leetcode.581
题目
分析
代码实现
应用9:Leetcode.42
题目
方法一:动态规划
分析
比较朴素的做法是找到每一根柱子左右两侧最高的柱子,那么每根柱子能盛水的体积,就是左右两侧最高的柱子的最小值与当前柱子之差。
对数组中的所有元素进行一次预处理:
- 先从右往左遍历,找到每一根柱子右侧最高的柱子;
- 再从左往右遍历,找到每一根柱子左侧最高的柱子。
因此,对于每一根柱子,能接住雨水的量,就是左右两侧最高柱子的最小值与当前柱子的高度的差值,最后,将所有的柱子能接住的雨水量相加即可。
代码实现
class Solution:
def trap(self, height: List[int]) -> int:
n = len(height)
right = [0] * n
right_max = 0
for i in range(n - 1, -1, -1):
right_max = max(right_max, height[i])
right[i] = right_max
left = [0] * n
left_max = 0
for i in range(n):
left_max = max(left_max, height[i])
left[i] = left_max
total = 0
for i in range(n):
total += min(left[i], right[i]) - height[i]
return total
方法二:单调栈
分析
我们维护一个单调递减栈,栈里保存元素的下标,如果栈中的元素大于等于 \(2\) ,在遇到下一个大于栈顶元素的元素时,这个元素与栈顶的两个元素组成的区域就能接住雨水,能接住雨水的量就是这三个元素围成的区域面积。
下面,我们以 \(height = [0,1,0,2,1,0,1,3,2,1,2,1]\) 为例,来说明算法的计算过程。
当某个时刻栈里面的元素是 \(stack = [3,4,5]\) 时,下一个大于栈顶的元素是 \(height[6]=1\),即

此时,由于栈里的元素是单调递减的,那么栈顶的第二个元素一定大于栈顶的元素,那么,一定有
所以,由这三个元素 \(height[4]\),\(height[5]\),\(height[6]\) 围成的区域一定能接住雨水,能接住的雨水的高度取决于两侧高度的最小值与栈顶元素的差值,长度为两侧元素的序号之差,即上图黄色的区域。
用同样的方法,继续向后查找,会遇到下一个大于栈顶元素\(height[7]=3\),此时,栈里面的元素是 \(stack = [3, 4, 6]\),由于\(height[4]=height[6]\),能接住的雨水量为零,弹出栈顶元素后,剩下的元素为\(stack = [3, 4]\),即

能接住雨水的区域就是上图黄色的区域。
代码实现
class Solution:
def trap(self, height: List[int]) -> int:
result = 0
stack = list()
n = len(height)
for i, h in enumerate(height):
while stack and h > height[stack[-1]]:
top = stack.pop()
if not stack:
break
left = stack[-1]
current_width = i - left - 1
current_height = min(height[left], height[i]) - height[top]
result += current_height * current_width
stack.append(i)
return result
总结
方法一和方法二用了两种不同的思路计算,方法一相当于竖着计算每个能接住雨水的区域,方法二相当于横着计算每个能接住雨水的区域。
应用10:Leetcode.84
题目
分析
我们以 \(heights = [1,3,5,4,3,2,1]\) 为例,如图所示,假设我们要找到以 \(height[4]=3\) 为高度的最大矩形。

对于 \(height[4]=3\) 已经得到高度,那么,剩下就只需需要找到它的最大宽度即可。
显然,我们只需要找到 \(height[4]\) 左右两侧第一个小于它的柱子,即 \(height[0]\) 、\(height[5]\),它们所围成的区域,就是这个矩形的宽度,即 \(width = 5 - 0 - 1 = 5\)。
因此,以 \(height[4]=3\) 为高度的最大矩形区域的面积就是 \(S=5 \times 3 = 15\)。
综上,我们可以得出一个思路:维护两个单调栈,通过两个单调栈分别记录每一根柱子左、右两侧第一个小于当前柱子高度的元素,那么当前柱子所在的区域能得到的最大的矩形面积,就是两侧柱子的序号的差值与当前柱子高度的乘积。
通过计算出每一根子能围成的最大矩形区域,最后,我们选择最大的一个矩形区域即可。
这里,需要边界条件的处理,我们假设数组长度为 \(n\),当左侧没有柱子时,我们将最左侧的柱子的序号设置为 -1;当最右侧没有柱子时,我们最右侧的柱子的序号设置为 \(n\)。
代码实现
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
if not heights:
return 0
n = len(heights)
# 记录每一个元素左侧第一个小于当前元素的序号
left = [0 for _ in range(n)]
# 记录每一个元素右侧第一个小于当前元素的序号
right = [0 for _ in range(n)]
stack = list()
for i in range(n):
while stack and heights[stack[-1]] >= heights[i]:
stack.pop()
left[i] = stack[-1] if stack else -1
stack.append(i)
stack = list()
for i in range(n - 1, -1, -1):
while stack and heights[stack[-1]] >= heights[i]:
stack.pop()
right[i] = stack[-1] if stack else n
stack.append(i)
result = 0
for i in range(n):
result = max((right[i] - left[i] - 1) * heights[i], result)
return result
应用11:Leetcode.321
题目
分析
假设数组 \(nums1\) 的长度为 \(m\) ,数组 \(nums2\) 的长度为 \(n\) ,分别从两个数组中选出长度为 \(x\)、\(y\) 的子序列。
那么 \(x\)、\(y\) 需要满足:
由于需要子序列需要保持原有的相对顺序,比较朴素的思想是枚举所有的 \((x, y)\) 的子序列组合,从两个数组中找到所有的子序列组合,并将其分别合并成一个新的序列,最后选择最大的一个序列。
这里,我们可以将上述等式变形,得到:\(y = k - x\),将其带入上述两个不等式,可以得到 \(x\) 的范围:
即
因此,\(x\) 的范围确定后,\(y\) 的范围也确定了,进而就得到了枚举 \((x, y)\) 的组合方法。
在合并子序列的时候,需要注意,不能简单地使用双指针的方式合并(参考并归排序),当子序列的左侧出现相等的元素时,双指针无法判断应该选择哪一个子序列。
例如,假设两个待合并的子序列分别是:\(subsequence1=[6, 7]\), \(subsequence2=[6, 0, 4]\)。
如果使用双指针合并,得到的结果就是: \([6,6,7,0,4]\),但是,我们期望的结果却是:\([6,7,6,0,4]\)。
可以看出简单使用双指针,当元素相等时,对序列中后续的元素的大小无法影响双指针的判断。
所以,我们需要单独定一个比较方法,用于在合并子序列时,判断应该优先从哪一个子序列中选择元素,比较子序列的策略如下:
- 当子序列的元素相等时,继续比较后续元素的大小,后续元素大的序列,即为权重更高的序列;
- 长度不为零的序列权重高于权重为零的序列。
算法步骤
那么,我们就可以得出算法的步骤:
- 依次从两个数组 \(nums1\)、\(nums2\) 中选择子序列组合,选择子序列的过程可以使用单调栈实现;
- 将两个子序列合并为一个新序列;
- 从所有的新序列中,找到权重最大的一个序列;
代码实现
class Solution:
def maxNumber(self, nums1: List[int], nums2: List[int], k: int) -> List[int]:
m, n = len(nums1), len(nums2)
subsequence = [0] * k
# 枚举所有的子序列,并将其拼接
start, end = max(0, k - n), min(k, m)
for i in range(start, end + 1):
subsequence1 = self.get_max_subsequence(nums1, i)
subsequence2 = self.get_max_subsequence(nums2, k - i)
total = self.merge(subsequence1, subsequence2)
if self.compare(total, subsequence) > 0:
subsequence = total
return subsequence
def get_max_subsequence(self, nums: List[int], k: int):
""" 通过单调栈从数组nums中选择最大的子序列 """
stack = list()
remain = len(nums) - k
for digit in nums:
while stack and remain and stack[-1] < digit:
stack.pop()
remain -= 1
stack.append(digit)
return stack[:k]
def merge(self, nums1: List[int], nums2: List[int]) -> List[int]:
"""合并两个数组"""
m, n = len(nums1), len(nums2)
if m == 0:
return nums2
if n == 0:
return nums1
result = list()
length = m + n
i, j = 0, 0
for _ in range(length):
if self.compare(nums1[i:], nums2[j:]) > 0:
result.append(nums1[i])
i += 1
else:
result.append(nums2[j])
j += 1
return result
def compare(self, nums1: List[int], nums2: List[int]) -> int:
"""比较两个数组的权重"""
m, n = len(nums1), len(nums2)
i, j = 0, 0
while i < m and j < n:
diff = nums1[i] - nums2[j]
if diff != 0:
return diff
i += 1
j += 1
return (m - i) - (n - j)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号