一句话: BP算法是基于梯度下降算法的迭代算法,用来优化模型参数, 作用相当于梯度下降算法
感知器:x {\bf{x}} x f ( x ) f(x) f ( x ) f ( x ) = { 1 if w ⋅ x + b > 0 0 else f(x)=\left\{\begin{array}{ll}{1} & {\text { if } w \cdot x+b>0} \\ {0} & {\text { else }}\end{array}\right. f ( x ) = { 1 0 if w ⋅ x + b > 0 else
感知器
误差逆传播算法 (error BackPropagation,简称 BP)
符号表示 :
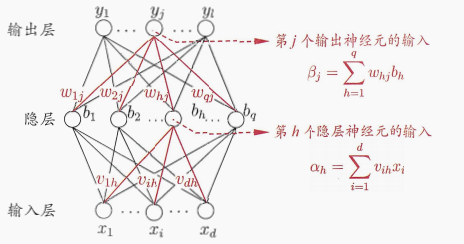
给定训练集 D ,上图神经网络含有d d d l l l q q q θ j θ_j θ j j j j γ h \gamma_h γ h h h h w h j w_{hj} w h j h h h j j j v i h v_{ih} v i h i i i h h h
隐层第 h h h α = ∑ i = 1 d v i h x i \alpha =\sum_{i=1}^dv_{ih}x_i α = ∑ i = 1 d v i h x i j j j β j = ∑ h = 1 q w h j b h \beta_j=\sum_{h=1}^qw_{hj}b_h β j = ∑ h = 1 q w h j b h b h b_h b h h h h f f f
神经网络的输出 y ^ = ( y ^ 1 k , y ^ 2 k , . . . , y ^ l k ) {\bf{\hat{y}}}=(\hat{y}^k_1, \hat{y}^k_2, ..., \hat{y}^k_l) y ^ = ( y ^ 1 k , y ^ 2 k , . . . , y ^ l k ) y ^ j k = f ( β j − θ j ) (5.3)
\hat{y}^k_j=f(\beta_j-\theta_j)\tag{5.3}
y ^ j k = f ( β j − θ j ) ( 5 . 3 ) j 为阈值。
网络在(xk ,yk )上的均方误差为E k = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 (5.4)
E_k=\frac12\sum_{j=1}^l(\hat{y}_j^k-y_j^k)^2\tag{5.4}
E k = 2 1 j = 1 ∑ l ( y ^ j k − y j k ) 2 ( 5 . 4 ) BP 是一个迭代学习算法,它基于梯度下降 策略,以目标的负梯度方向对参数进行调整.对式 (5.4) 的误差 Ek ,给定学习率 η ,有Δ w h j = − η ∂ E k ∂ w h j = − η ∂ E k ∂ y ^ j k ⋅ ∂ y ^ j k ∂ β j ⋅ ∂ β j ∂ w h j (5.5)
\begin{aligned}
\Delta w_{hj} &= -η\frac{\partial E_k}{\partial w_{hj}}\\ &= -η \frac{\partial E_k}{\partial \hat{y}^k_j }\cdot \frac{\partial \hat{y}^k_j}{\partial \beta _j }\cdot\frac{\partial \beta _j}{\partial w_{hj}}\tag{5.5}
\end{aligned}
Δ w h j = − η ∂ w h j ∂ E k = − η ∂ y ^ j k ∂ E k ⋅ ∂ β j ∂ y ^ j k ⋅ ∂ w h j ∂ β j ( 5 . 5 ) f ′ ( x ) = f ( x ) ⋅ ( 1 − f ( x ) ) (5.6)
f'(x)=f(x)\cdot (1-f(x))\tag{5.6}
f ′ ( x ) = f ( x ) ⋅ ( 1 − f ( x ) ) ( 5 . 6 ) g j = − ∂ E k ∂ y ^ j k ⋅ ∂ y ^ j k ∂ β j = − ( y j k ^ − y j k ) f ′ ( β j − θ j ) = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) (5.7)
\begin{aligned}
g_j&=- \frac{\partial E_k}{\partial \hat{y}^k_j }\cdot \frac{\partial \hat{y}^k_j}{\partial \beta _j } \\&= -(\hat{y_j^k}-y_j^k)f'(\beta _j-\theta_j)\\&=\hat{y}_j^k(1-\hat{y}_j^k)(y_j^k-\hat{y}_j^k)\tag{5.7}
\end{aligned}
g j = − ∂ y ^ j k ∂ E k ⋅ ∂ β j ∂ y ^ j k = − ( y j k ^ − y j k ) f ′ ( β j − θ j ) = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) ( 5 . 7 ) j 的定义,显然有∂ β j ∂ w h j = b h (5.8)
\frac{\partial \beta_j}{\partial w_{hj}}=b_h\tag{5.8}
∂ w h j ∂ β j = b h ( 5 . 8 ) Δ w h j = n g j b h (5.9)
\Delta w_{hj}=ng_jb_h\tag{5.9}
Δ w h j = n g j b h ( 5 . 9 ) Δ θ j = − η g j (5.10)
\Delta \theta_j=-ηg_j\tag{5.10} Δ θ j = − η g j ( 5 . 1 0 ) Δ v i h = η e h x i (5.11)
\\ \Delta v_{ih}=ηe_hx_i\tag{5.11}
Δ v i h = η e h x i ( 5 . 1 1 ) Δ γ h = − η e h (5.12)
\Delta \gamma_h =-ηe_h\tag{5.12}
Δ γ h = − η e h ( 5 . 1 2 ) 工作流程 。对每个训练样例, BP 算法执行以下操作:先将输入实例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果;然后计算输出层的误差(第4-5行),再将误差逆向传播至隐层神经元(第6行),最后根据隐层神经元的误差来对连接权和阈值进行调整(第7行)。该迭代过程循环进行,直到达到某些停止条件为止。
输入 :训练集 D={(x k ,y k )}k = 1 m _{k=1}^m k = 1 m 过程 :repeat for all (x k ,y k ) ∈ \in ∈ do y ^ k \hat{y}_k y ^ k g j g_j g j e h e_h e h w h j , v i h w_{hj},v_{ih} w h j , v i h θ j , γ h \theta_j,\gamma_h θ j , γ h end for until 达到停止条件输出 :连接权与阈值确定的多层前馈神经网络
以下为吴恩达课程中的表述:训练神经网络:1. 参数的随机初始化
参考:周志华《机器学习》