

在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果。
一 .环境
1.操作系统:Ubuntu 12.04 LTS 64位
2.Java版本:openjdk-7-jdk
3.Hadoop版本:2.6.0
4.结点信息:
|
机器名 |
IP |
hostname |
作用 |
|
master |
10.13.14.83 |
rdcdz140395 |
NameNode and JobTracker |
|
slave-1 |
10.13.14.110 |
rdjdz110716 |
DataNode and TaskTracker |
|
slave-2 |
10.13.14.127 |
rdjdz120312 |
DataNode and TaskTracker |
5.我在每台机器上创建了群组hadoop和用户hduser,并将hduser加入到hadoop群组中,方便管理。
二.安装
1.在这3台电脑上都安装 jdk,ssh,maven
sudo apt-get update sudo apt-get install openjdk-7-jdk sudo apt-get install ssh sudo apt-get install rsync sudo apt-get install maven sudo apt-get update
2.在这3台电脑上都添加Hadoop用户组和用户hduser
sudo addgroup hadoop sudo adduser --ingroup hadoop hduser sudo adduser hduser sudo
然后切换到hduser账户,进行下面的操作。
su - hduser
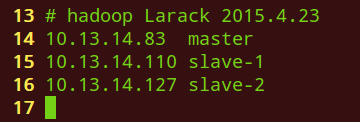
3.修改集群中所有机器的/etc/hosts
10.13.14.83 master 10.13.14.110 slave-1 10.13.14.127 slave-2
如下图所示
4.建立SSH无密码登录
在Hadoop启动以后,namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,这就需要在节点之间执行指令的时候是不需要输入密码的方式,故我们需要配置SSH使用无密码公钥认证的方式。
使用下面的命令会在~/.ssh/目录下生成 id_dsa.pub文件,如果我们希望master 结点不需要密码就能使用ssh连接到slave结点,我们需要将master结点上的~/.ssh/id_dsa.pub的内容,添加到slave结点的~/.ssh,并将id_dsa.pub重命名为authorized_keys
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa scp -r /home/hduser/.ssh/id_dsa.pub hduser@10.13.14.110:/home/hduser/.ssh/authorized_keys scp -r /home/hduser/.ssh/id_dsa.pub hduser@10.13.14.127:/home/hduser/.ssh/authorized_keys

5.下载&安装Hadoop
下载Hadoop 解压到master服务器的/home/hduser目录下(配置好master结点后再将其复制到其它的服务器上,一般来说,群集中所有的hadoop都安装在同一目录下)
cd ~ wget http://www.trieuvan.com/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz sudo tar -xzvf hadoop-2.6.0.tar.gz -C /usr/local cd /usr/local sudo mv hadoop-2.6.0 hadoop sudo chown -R hduser:hadoop hadoop
6.配置Hadoop环境
(1)修改.bashrc
vim ~/.bashrc
将下面的内容复制到.bashrc最后一行
## Hadoop variables ,start of paste export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL ###end of paste
7.配置Hadoop
(1)修改 hadoop-env.sh
cd /usr/local/hadoop/etc/hadoop vim hadoop-env.sh
将下面的三行加入到hadoop-env.sh中,删除原来的 "export JAVA_HOME"那行
# begin of paste export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/ export HADOOP_COMMON_LIB_NATIVE_DIR="/usr/local/hadoop/lib/native/" export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/lib/" ### end of paste
(2)修改 core-site.xml
vim core-site.xml
将下面的内容复制到 <configuration> 标签内
<property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
(3)修改 yarn-site.xml
vim yarn-site.xml
将下面的内容复制到 <configuration> 标签内
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
(4)修改 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml
将下面的内容复制到 <configuration> 标签内
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
(5)修改 hdfs-site.xml
mkdir -p ~/mydata/hdfs/namenode mkdir -p ~/mydata/hdfs/datanode vim hdfs-site.xml
将下面的内容复制到 <configuration> 标签内
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hduser/mydata/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hduser/mydata/hdfs/datanode</value> </property>
8.安装 protobuf-2.5.0 or later
curl -# -O https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz tar -xzvf protobuf-2.5.0.tar.gz cd protobuf-2.5.0 ./configure --prefix=/usr make sudo make install cd .. mvn package -Pdist,native -DskipTests -Dtar
三.启动
1.格式化 namenode
hdfs namenode -format
2.启动服务
start-dfs.sh && start-yarn.sh
3.使用jps查看服务
jps
4.在浏览器上查看
Cluster status: http://localhost:8088
HDFS status: http://localhost:50070
Secondary NameNode status: http://localhost:50090
参考文档:http://blog.csdn.net/feixia586/article/details/24950111

 浙公网安备 33010602011771号
浙公网安备 33010602011771号