

自然语言处理----词袋模型
词袋模型是一种表征文本数据的方法,可以从文本数据中提取出特征并用向量表示.词袋模型主要包括两件事
- 构建词汇表
- 确定度量单词出现的方法
词袋模型不考虑单词在文本中出现的顺序,只考虑单词是否出现.
具体以"双城记"开头为例
- 收集数据
It was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness,
- 构建词汇表
对于上面四个句子,我们要用词袋模型把它转化为向量表示,这四个句子形成的词表(不去停用词)为:
“it”
“was”
“the”
“best”
“of”
“times”
“worst”
“age”
“wisdom”
“foolishness”
- 创建向量
这一步的目的是把文本数据转化成向量表示. 我们构建的字典中一共有10个单词,因此我们可以用一个固定长度为10的向量表示一句话,向量的每一个位置表达了文本中出现的某一个词, 向量每个位置的值有多种选择.最简单的是使用binary特征, 即如果该词在句子中出现了设为1,不出现就为0.这也就是one-hot编码.以第一句为例,该句的bianry向量为
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
剩下三句的编码为
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
"it was the age of foolishness" = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
管理词典
假设我们有非常大的语料库,比如说几千本书,那么此时的构建的向量长度可能长达数万,而且对于每本书而言可能只包含词典中很少的词,这样对每本书构建的向量中就会含有大量的0.这样的向量成为稀疏向量或者说稀疏表示.因此我们要考虑如何减小词典的大小. 最简单的我们可以做一些文本清洗
- 全部转换为小写或者全部转为大写
- 去掉停用词
- 修改拼写错误的词
- 对于英文单词还可以做词干提取
更高级的方法是构建包含词组的词典,这既能减少词典的大小也能让词袋模型从文本中学习到一些东西.在该方法中每个单词或者说字符成为gram, 创建一个包含两个单词对的词典称为bigram,注意只有出现在语料库中的bigram才能添加到词典里
一个N-gram是一个N字符的单词序列:一个2-gram(通常称为bigram)是一个两个单词的单词序列,例如“ please turn”,“ turn your”或“ our your work”, 3-gram(通常称为trigram)是由三个词组成的单词序列,例如““please turn your”, 或者 “turn your homework”.
例如我们给的例子中第一句的bigram就是
“it was”
“was the”
“the best”
“best of”
“of times”
由三个单词序列构成的词典称为3-gram,更一般的由n个单词序列构成的词典称为n-gram
对每个单词打分
构建完词典后,我们需要对出现在文档中的词进行打分,在刚刚给出的例子中我们使用的是bianry的方法,出现为1, 不出现为0. 此外我们还可以用单词在文档中出现的次数或者词频, TF-IDF对其打分.
词频,即一个单词或者词组在一篇文档中出现的频率. 如果某个单词或词组在文章中出现次数很多,但是它包含的信息并不多,这时候只用词频度量单词或词组就会产生偏差. 一种方法就是利用该单词或词组在所有文档中出现的次数来对词频进行缩放. 这就是TF-IDF.
TF-IDF
TF:是对词在当前文档中频率, 其有多种取值形式,最简单的是直接使用单词出现的次数,也可以使用
- 布尔频率,单词出现为1,否则为0
- 进行"词频"标准化, 单词出现的数目/文档的长度
- 对数缩放, log(1+单词出现的次数)
- 增强频率,以防止偏向较长的文档,例如 单词出现的次数除以文档中最常出现的单词的次数:
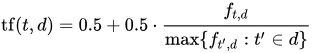
f_(t,d)是单词出现的次数
IDF:是逆文档频率,是一个词语普遍重要性的度量,它的大小与一个词的常见程度成反比
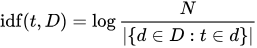
N是语料库中所有文档的数目.分母部分是包含单词t的文档的数目. 一个单词越频繁的出现在不同文档中,逆文档频率就越低
最后

字词的重要性随着它在文件中出现的次数成正比增加 ,但同时会 随着它在语料库中出现的频率成反比下降 。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
词袋模型的局限
- 词典: 在设计词典的时候要重点关注词典的大小, 过大的词典会导致文本表示稀疏化
- 稀疏化: 出于计算原因(空间和时间复杂度)以及信息原因,很难对稀疏表示进行建模. 难点主要在于在非常大的表示空间中模型能利用的信息非常少
- 含义:丢弃单词顺序会忽略上下文,从而忽略文档中单词的含义(语义)。 上下文和语义可以为模型提供很多帮助,例如可以帮助模型区分由相同单词构成的不同序列间的差异(“this is interesting” 和 “is this interesting”),同义词(“旧自行车”与“二手自行车”),等等。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端