Kafka入门
1. kafka简介
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,具有自己独特的设计。
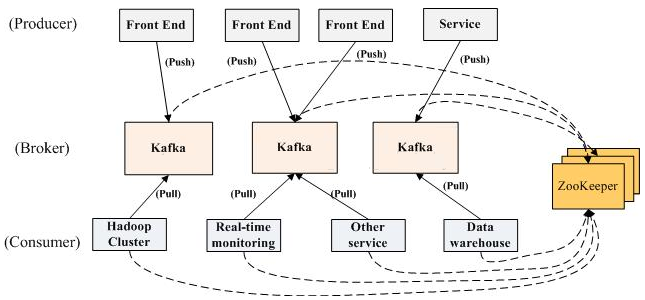
1.1 Topics 和partition
对每个topic,Kafka 对它的日志进行了分区(partition),如下图所示:

每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
1.2 主从同步和容错
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。
创建副本的单位是topic的分区,每个分区都有一个leader和零或多个followers.所有的读写操作都由leader处理,一般分区的数量都比broker的数量多的多,各分区的leader均匀的分布在brokers中。所有的followers都复制leader的日志,日志中的消息和顺序都和leader中的一致。flowers向普通的consumer那样从leader那里拉取消息并保存在自己的日志文件中。
Leader会追踪所有“同步中”的节点,一旦一个down掉了,或是卡住了,或是延时太久,leader就会把它移除。至于延时多久算是“太久”,是由参数replica.lag.max.messages决定的,怎样算是卡住了,怎是由参数replica.lag.time.max.ms决定的。
只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。Producer也可以选择是否等待消息被提交的通知,这个是由参数request.required.acks决定的。
Kafka保证只要有一个“同步中”的节点,“committed”的消息就不会丢失。
Kafka的架构拓扑图:

1.3 消息模式
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。

相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
2. 安装和使用
kafka自身只提供bin目录下的命令行工具,在config目录下有相关的配置文件,所有安装启动等操作基本都是都由自带的命令行工具指定配置文件来完成。
2.1 启动Zookeeper
Kafka依赖zk,可以使用自带的zk也可以使用现成的zk集群。
测试时可以使用Kafka附带的Zookeeper:
启动命令:./bin/zookeeper-server-start.sh config/zookeeper.properties & ,config/zookeeper.properties是Zookeeper的配置文件。
结束命令: ./bin/zookeeper-server-stop.sh
不过最好自己搭建一个Zookeeper集群,提高可用性和可靠性。
2.2 启动Kafka服务器
2.2.1 配置文件
配置config/server.properties文件,一般需要配置如下字段,其他按默认即可:
broker.id:每一个broker在集群中的唯一表示,要求是正数
advertised.listeners(效果同之前的版本的host.name及port):注意绑定host.name,否则可能出现莫名其妙的错误如consumer找不到broker。这个host.name是Kafka的server的机器名字,会注册到Zookeeper中
log.dirs:kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能
log.retention.hours: 数据文件保留多长时间, 存储的最大时间超过这个时间会根据log.cleanup.policy设置数据清除策略
zookeeper.connect:指定ZooKeeper的connect string,以hostname:port的形式,可有多个以逗号分隔,如hostname1:port1,hostname2:port2,hostname3:port3,还可有路径,如:hostname1:port1,hostname2:port2,hostname3:port3/kafka,注意要事先在zk中创建/kafka节点,否则会报出错误:java.lang.IllegalArgumentException: Path length must be > 0
所有参数的含义及配置可参考:https://blog.csdn.net/lizhitao/article/details/25667831
2.2.2 命令
启动命令: bin/kafka-server-start.sh config/server.properties ,生产环境最好以守护程序启动:nohup &
结束命令: bin/kafka-server-stop.sh
2.3 使用
2.3.1 命令行客户端
kafka的功能都是通过自带的命令行脚本实现
创建topic: bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
列出所有topic: bin/kafka-topics.sh --list --zookeeper localhost:2181
查看topic信息(包括分区、副本情况等): kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic ,会列出分区数、副本数、副本leader节点、副本节点、活着的副本节点
往某topic生产消息: bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
从某topic消费消息: bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning (默认用一个线程消费指定topic的所有分区的数据)
删除某个Kafka groupid:连接Zookeeper后用rmr命令,如删除名为JSI的消费组: rmr /consumers/JSI
查看消费进度:
./bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group test-mirror-consumer-zsm --zkconnect ec2-12345.cn-north-1.compute.amazonaws.com.cn:2181/kafka/blink/0822 --topic GPS2
各参数:
--group指MirrorMaker消费源集群时指定的group.id
-zkconnect指源集群的zookeeper地址
--topic指定查的topic,没指定则返回所有topic的消费情况
2.3.2 java客户端
新版本的javaAPI都是通过kafka客户端的jar包提供的
通过在pom文件中添加依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
</dependency>
来引入kafka客户端
生产者demo示例

生产者配置

消费者demo

消费者配置文件

2.3.3 与spring集成
spring提供了kafka与spring直接集成的组件Spring for Apache Kafka,使用起来更加方便,这方面没有什么可说的spring-kafka的官网有相关api介绍:http://spring.io/projects/spring-kafka#learn
代码可以参考https://www.cnblogs.com/wangb0402/p/6187796.html
3. 优缺点分析
Kafka给我最大的一个感觉就是简洁高效,重剑无锋,大巧不工
3.1 优点
1.Kafka最大的优点就是在简单的场景下吞吐量高,性能非常优秀:
根据官方的说法卡夫卡单机写入TPS约在百万条/秒,消息大小10个字节
对比RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
这里可以直接引用阿里中间件团队博客的测试数据: http://jm.taobao.org/2016/04/01/kafka-vs-rabbitmq-vs-rocketmq-message-send-performance/

2.消息顺序写入文件可靠性高,消息堆积能力强:
Kafka的存储结构是topic_partition对应一个日志文件,Producer对该日志文件进行“顺序写”,Consumer对该文件进行“顺序读”。
在大多数的消息系统中,数据持久化的机制往往是为每个cosumer提供一个B树或者其他的随机读写的数据结构。B树当然是很棒的,但是也带了一些代价:比如B树的复杂度是O(log N),O(log N)通常被认为就是常量复杂度了,但对于硬盘操作来说并非如此。磁盘进行一次搜索需要10ms,每个硬盘在同一时间只能进行一次搜索,这样并发处理就成了问题。虽然存储系统使用缓存进行了大量优化,但是对于树结构的性能的观察结果却表明,它的性能往往随着数据的增长而线性下降,数据增长一倍,速度就会降低一倍。
直观的讲,kafka的数据的持久化可以简单的认为是将数据追加到文件中实现,读的时候从文件中读就好了。这样做的好处是读和写都是 O(1) 的,并且读操作不会阻塞写操作和其他操作。这样带来的性能优势是很明显的,因为性能和数据的大小没有关系了。
因而只要磁盘空间足够的话kafka的理论消息堆积能力是无限的。
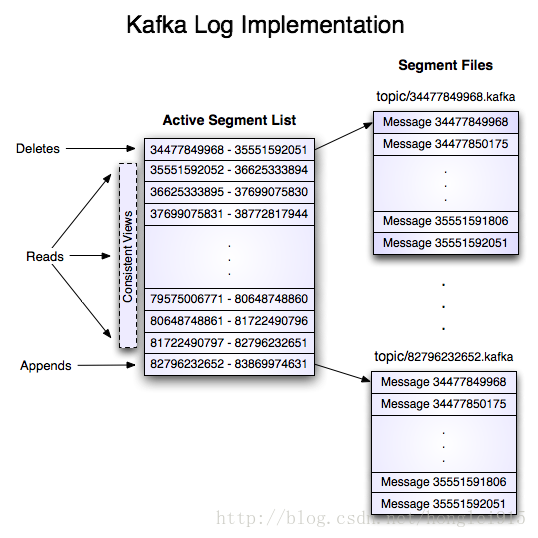
3.结构简单,自身不维护节点和消息的状态:
由于Kafka是按照offset进行读取的,给定一个起始offset后续不停的get就可以顺序读取了,没有消费确认的概念,Kafka也不会维护每个消息、每个Consumer的状态,完全依赖zk解决负载均衡分布式一致性问题。它大量利用了zookeeper做服务发现和offset存储,对应producer和consumer的状态保存也都是通过zookeeper完成的。因此kafka的消息体本身十分简洁轻便,减提高了网络传输的效率和存储效率。
启动Zookeeper和Kafka,命令行连接Zookeeper后,用 get / 命令可发现有 consumers、config、controller、admin、brokers、zookeeper、controller_epoch 这几个目录。
其结构如下:

4.使用简便:
这点可以在前面的安装使用中看的出来,kafka本身的包非常小,解压缩即可使用安装部署也非常方便,在命令行下直接通过一行命令行启动即可。 而且由于kafka自身的消费模型简单,模式也很单一,不提供一些针对特定业务场景的复杂功能,没有特别多需要配置的地方,因此使用起来也非常方便。在命令行下可以直接通过命令启动生产者和消费者。甚至可以直接在命令行中把文件动态的通过流的形式发到broker,这对于日志的收集是十分简便的,
例如,将 apache 或者 nginx 或者 tomcat 等产生的日志 push 到 kafka,只需要执行下面代码即可:
$ tail -n 0 -f /var/log/nginx/access.log | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
3.2 缺点
1.对于多Partions或多topic的复杂业务环境下性能下降明显:
这点可以结合优点2看。
在Kafka中,是每个topic_partition一个文件。虽然每个文件是顺序IO,但topic或者partition过多,每个文件的顺序IO,表现到磁盘上,还是随机IO。
关于这个,阿里中间件团队,专门写了一篇博客,测试这个。结论是:在topic比较少的情况下 kafka优于的性能优于RocketMQ,topic数量增加到一定程度,kafka性能急剧下降。
而partition官方有一个说明。分区数的确定与硬件、软件、负载情况等都有关,要视具体情况而定,不过依然可以遵循一定的步骤来尝试确定分区数:创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)。
因此kafka更加适用于只支持topic较少,partition较少的场景


2默认使用异步刷盘,同步刷盘性能较低:
线性读写的情况下影响磁盘性能问题大约有两个方面:太多的琐碎的I/O操作和太多的字节拷贝。I/O问题发生在客户端和服务端之间,也发生在服务端内部的持久化的操作中。为了避免这些问题,Kafka建立了“消息集(message set)”的概念,将消息组织到一起,作为处理的单位。以消息集为单位处理消息,比以单个的消息为单位处理,会提升不少性能。Producer把消息集一块发送给服务端,而不是一条条的发送;服务端把消息集一次性的追加到日志文件中,这样减少了琐碎的I/O操作。consumer也可以一次性的请求一个消息集。
Kafka本身是没有实现任何同步刷盘机制。但要想做到每一条消息都在落盘后才返回,我们可以通过修改异步刷盘的频率来实现。设置参数log.flush.interval.messages=1,即每条消息都刷一次磁盘。这样的做法,Kafka也不会丢消息了,但是频繁的磁盘读写直接导致性能的下降。因此在需要严格不丢失消息的业务场景下不建议使用Kafkakafka。
3.消费并行度限制:
我们知道,Kafka为了保证每个partition的消息顺序,限制每个partition只能1个consumer消费。Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。
4.没有分布式事务消息和消费失败重试机制:
原理上来说其实都是可以做的,Kafka不处理,而是让消费的业务方去处理,并给出了相应的解决方案。这些针对特定场景的业务功能交给业务方去处理也有它的道理。这点实际上也维护了kafka的简洁和高效。
5.没有自带的监控管理工具
Kafka自带的都是命令行工具,没有一个直观的监控管理的工具,运维起来不是很方便,只能依靠一些第三方的工具实现监控管理
目前Kafka监控方案看似很多,然而并没有一个“大而全”的通用解决方案。各家框架也是各有千秋,以下是我了解到的一些内容:
1)Kafka manager
Github地址: https://github.com/yahoo/kafka-manager。 这款监控框架的好处在于监控内容相对丰富,既能够实现broker级常见的JMX监控(比如出入站流量监控),也能对consumer消费进度进行监控(比如lag等)。另外用户还能在页面上直接对集群进行管理,比如分区重分配或创建topic——当然这是一把双刃剑,好在kafka manager自己提供了只读机制,允许用户禁掉这些管理功能。
2)Kafka Monitor
Github地址:https://github.com/linkedin/kafka-monitor。 这款监控框架更多的是关注对Kafka集群做端到端的整体系统测试,并产出各种系统级的监控指标,比如端到端的延时,整体消息丢失率等。对于新搭建的Kafka线上集群,使用Kafka Monitor做个整体测试有助于你了解该集群整体的一些性能,但若是用于日常监控该框架便有些不便了,需要自己修改webapp/index.html中的监控指标,流程上有些不太友好。不过这款框架的优势是其主要贡献者是LinkedIn的lindong(Kafka 1.0.0版本中正式支持JBOD就是lindong开发的),质量上应该是有保证的。
3)Kafka Offset Monitor
Github地址:https://github.com/quantifind/KafkaOffsetMonitor。 KafkaOffsetMonitor应该算比较早的监控框架了,有着很酷的UI,使用者也是很多。但其比较大的劣势是对新版本consumer和security的支持,另外该项目已经近2年未维护了,其主力开发甚至是另起炉灶,重新写了一个新的KafkaOffsetMonitor来支持新版本consumer——https://github.com/Morningstar/kafka-offset-monitor。不过目前该项目star数很少,应该没有大规模应用,到底是否适用于生产环境需要用户自行判断
4)Burrow
Github地址: https://github.com/linkedin/Burrow。 Burrow是LinkedIn开源的一款专门监控consumer lag的框架。事实上,当初其开源时我对它还是期待挺高的,不过令人遗憾地是后劲不足,发展得非常缓慢,而且这款框架是用Go写的,安装时要求必须有Go运行环境,故Burrow在普及上不如其他框架。Burrow没有UI界面,只开放了很多HTTP endpoint,这对于想偷懒的运维来说更是一个减分项。总之它的功能目前十分有限,普及率和知名度都是比较低的。不过好处是该项目主要贡献者是LinkedIn团队维护Kafka集群的主要负责人,故质量上是很有保证的
5)JMXTrans + InfluxDB + Grafana
这实际上是一套监控框架的组合。有着非常非常炫酷的UI效果,极其适合向领导展示。
总之,目前Kafka的监控并没有“放之四海而皆准”的解决方案,应该说每种框架都有自己独到的地方。用户需要结合自身监控需求选择适合的监控框架
若只需要监控功能,推荐使用KafkaOffsetMonito或Burrow,若偏重Kafka集群管理,推荐使用Kafka Manager。
4. 适用场景
正如我前面所说重剑无锋,大巧不工,Kafka是一个极致追求性能的典范。
Kafka更适用于数据量巨大极度压榨性能且业务不太复杂的场景。日志处理就是这么一个领域。Kafka设计的初衷就是用作日志处理,因此在日志处理领域非常成熟。此外,Kafka在大数据开发中(实时数据处理和分析)也被大量使用。为集成其他系统和解耦应用,经常使用Producer来发送消息到Broker,并使用Consumer来消费Broker中的消息。大数据也是Kafka目前大力发展的一个方向,到0.9版本开始提供了Kafka connect为Kafka连接大数据平台提供了便利,flink与Kafka集成是流处理中非常流行的做法。此外Kafka 0.10又提供了Kafka Steam用于实时处理Kafka中的数据流,自身就可以作为一个类似于Spark Streaming 或者Apache Storm的一个流计算处理框架。

Kafka 为大数据吞吐为王的日志处理而生,具有碾压其它同类产品的高性能,就像是一把锋利的大砍刀,但是应对一些业务处理复杂但是吞吐量并不需要特别大的互联网应用场景则显得有些不太趁手。比如缺点里提到的,多partition或者多topic的情况、需要严格的可靠性的情况等等都不是Kafka所擅长的领域。到这里就不得不提一下RocketMQ了,它和Kafka是如今最流行的2款消息中间件。RocketMQ的前身metamorphosis一开始就是阿里的团队把Kafka移植到java语言上而来,在设计上是基本一致的架构上也十分相近。但是在kafka的基础上RocketMQ针对“电商”的特定业务场景持续优化开发定制了更多的功能,除了缺点4提到的分布式事务消息和消费失败重试机制其他一些针对性更强的的功能诸如“定时消息“,“消息查询”,“消息轨迹”,”按时间的消息回朔“,这些Kafka都是所不具备的。当然由于原理和结构上的相似Kafka也可以去定制实现这些功能,但是Kafka把这些交给了业务方去处理,维护了自身的简洁性。
5.参考资料:
https://www.w3cschool.cn/apache_kafka/apache_kafka_introduction.html
https://blog.csdn.net/tangdong3415/article/details/53432166
https://www.cnblogs.com/skying555/p/7903457.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号