hadoop学习笔记(十一):MapReduce数据类型
一、序列化
1 hadoop自定义了数据类型,在hadoop中,所有的key/value类型必须实现Writable接口。有两个方法,一个是write,一个是readFileds。分别用于读(反序列化操作)和写(序列化操作)。
2 所有的key必须实现Comparable接口,在MapReduce过程中需要对key/value对进行反复的排序,默认情况下依据key进行排序,要实现compareTo()方法,所以通过key既要实现Writable接口又要实现Comparable接口。
3 因此,hadoop中提供了一个公共的接口WritableComparable接口,这个接口继承了Writable和Comaprable接口。
4 由于需要序列化和反序列化和比较,需要对java对象重写一下几个方法:
1、equlas()方法。
2、hashcode()方法。
3、toString()方法。
4、数据类型必须有一个默认的无参的构造方法,为了方便反射,进行创建对象。
序列化的概念:
所谓序列化(serialization),是指将结构化对象转化为字节流,以便在网络上传输或写到磁盘进行永久存储。
在分布式数据里的两大领域里,序列化经常出现,进程间通信和永久存储。
在hadoop中,系统多个节点上进程间的通信是通过“远程过程调用”(remote procedure call,RPC)实现的。RPC协议将消息序列化成二进制流后发送到远程节点,远程节点接着将二进制流反序列化为原始消息。
hadoop使用自己的序列化格式(Writable),它格式紧凑、速度快,但很难用Java以外的语言进行扩展或使用。因为Writable是hadoop核心(大多数MapReduce程序都会以键和值使用它)。
反序列化的概念:
反序列化是指将字节流转回结构化对象的过程。
二、数据类型
数据类型都实现了Writable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储。
基本数据类型:
| Java基本数据类型 | 名称 | 类型 | 序列化大小 |
| boolean | BooleanWritable | 标准布尔类型数值 | 1 |
| byte | ByteWritable | 单字节数值 | 1 |
| double | DoubleWritable | 双字节数值 | 8 |
| float | FloatWritable | 浮点数 | 4 |
| int | IntWritable | 整型数 | 4 |
| VintWritable | 可变长度整型数 | 1~5 | |
| long | LongWritable | 长整型数 | 8 |
| VlongWritable | 可变长度长整型数 | 1~9 | |
| Text | 使用UTF-8格式存储文本 | ||
| NullWritable | 当<key,value>中的key或value为空时使用 |
注意:在自定义数据类型中,建议使用java原生的数据类型,最好不要使用hadoop封装的数据类型。
三、比较器(Comparable)
当数据写入磁盘时,如果要进行排序的话, 需要首先从磁盘读取数据,进行反序列化成对象,然后在内存中对反序列化的对象进行比较。为什么不直接在内存中就直接进行比较呢?
如果要实现上述功能,hadoop数据类型需要实现一个接口RawComparator接口。
RawComarator
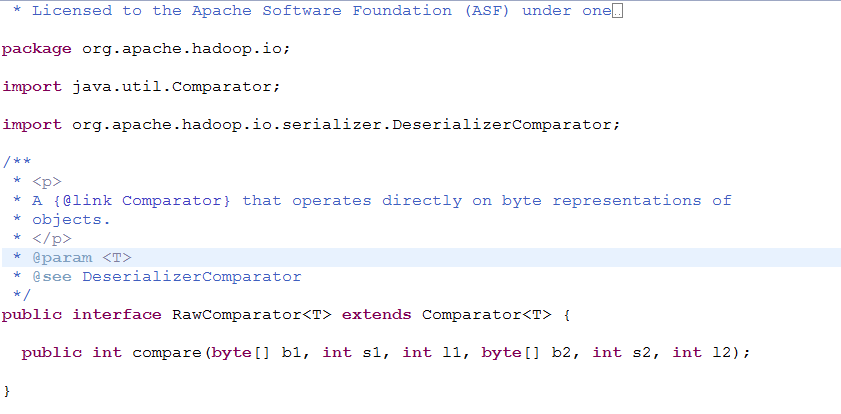
对MapReduce来说,类型的比较是非常重要的,因为中间有一个基于键的排序阶段。hadoop提供的一个优化接口是继承自Java Comparator的RawComparator接口。
该接口允许其实现直接比较数据流中的记录,无须先把数据反序列化为对象,这样便避免了新建对象的额外开销。例如,我们根据IntWritable接口实现的comparator实现了comare()方法,该方法可以从每个字节数组b1和b2中读取给定起始位置(s1和s2)以及长度(l1和l2)的一个整数进而直接进行比较。
WritableComarator是对继承自WritableComparable类的RawComaparator类的一个通用实现,它提供两个主要功能。
第一、它提供了对原始compare()方法的一个默认实现,该方法能够反序列化在流中进行比较的对象,并调用对象的compare()方法。
第二、它充当的是RawComparator实例的工厂(已注册Writable的实现)。例如,为了获得IntWritable的comparator,我们直接如下调用:

这个comparator可以用于比较两个IntWritable对象;

或其序列化表示:

四、NullWritable
NullWritable是Writable的一个特殊类型,它的序列化长度为0.它并不从数据流中读取数据,也不写入数据。它充当占位符;例如,在MapReduce中,如果你不需要使用键或值,就可以将键或值声明为NullWritable。结果是存储常量空值。如果希望存储一系列数值,与键值对相对,NullWritable也可以用作在SequenceFile中的键。它是一个不可变的单实例类型:通过调用NullWritable.get()方法可以获取这个实例。
五、ObjectWritable && GenericWritable
ObjectWitable是对Java基本类型(String,enum,Writable,null或这些类型组成的数组)的一个通用封装,它在hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。
当一个字段中包含多个类型时,ObjectWritable是非常有用的:例如,如果SequenceFile中的值包含多个类型,就可以将值类型声明为ObjectWritable,并将每个类型封装在一个ObjectWritable中。作为一个通用机制,每次序列化都写封装类型的名字,这非常浪费空间。如果封装的类型数量比较少并且能够提前知道,那么可以通过使用静态类型的数组,并使用对序列化后的类型的引用加入位置索引提高性能。这是GenericWritable类采取的方法,并且你可以在继承的子类中指定需要支持的类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号