hadoop学习笔记(八):MapReduce
一、MapReduce编程模型
一种分布式计算框架,解决海量数据的计算问题。
MapReduce将整个并行计算过程抽象到两个函数:
Map(映射):对一些独立元素组成的列表的每一个元素进行制定的操作,可以高度并行。
Reduce(化简):对一个列表的元素进行合并。
一个简单的MapReduce程序只需要指定Map()、reduce()、input和output,剩下的事情由框架完成。
二、Map过程(以wordcount为例):
1 一行一行读,每一行都解析成key/value形式。每一个键值对,都调用一次Map函数。
假设有一个文件的内容是:
hello hadoop!
hello world!
那么Map的读取过程为:
| key | value | operate |
| 0 | hello hadoop! | --> hello:1 hadoop!:1 |
| 13 | hello world! | --> hello:1 world!:1 |
2 写自己的逻辑,对输入的key/value处理,转换成新的key/value输出。
| key | value |
| hello | 1 |
| hadoop! | 1 |
| hello | 1 |
| world! | 1 |
3 对输出的key/value进行分区。
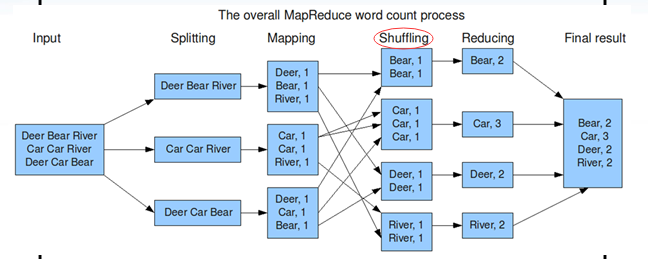
注意:Shuffling囊括了:partition和sort。
4 对不同分区的数据,按照key进行排序、分组。把相同的key的value放到一个集合中。
| key | list<value> |
| hello | 2 |
| hadoop! | 1 |
| world! | 1 |
5 (可选)分组后的数据进行归约。
三、Reduce过程:
1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key/value处理,转换成新的key/value输出。
3 把reduce的输出保存到文件中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号