

dump内存和线程栈
为什么要调整线程池?
线程池太小会造成请求在线程池这排队,导致响应时间太长,太大的线程池会造成资源浪费,线程占内存,响应时间太慢需要调整线程池
502和503错误需要调整线程池配置
第一进行调整中间件最快入手的是线程池或进程池的配置
第二进行调整的是timeout时间、keepalive和maxkeepalive
第三个需要调整的是前端,gzip压缩,对哪些文件开启gzip压缩,压缩的比例或等级有多大
第四个改下http请求头,body,修改buffer(这个做不了)
JVM内存管理之道
Java比C的优点是Java的jvm自动管理分配内存,不需要手动释放
New出来和数组的实例化都放在堆里面,oom看堆,gc看堆
main()方法和全局变量放在栈区
method放在方法区
永久区主要包括栈、方法、程序计数器、全局变量和常量,栈是实时变化的,cpu高、磁盘高看栈里的方法
重点堆内存,栈区和方法区属于非堆
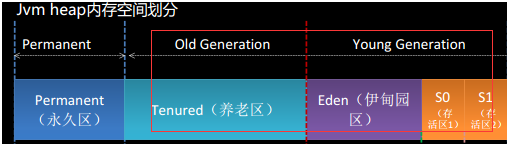
3/8堆内存=young generation
5/8堆内存=old generation
eden和存活区的比例是8:1:1
重点讲年轻代和老年代
第一次young gc
入口只有一个在eden,eden区满了,没法继续new对象,应用程序暂停运行,判断eden区内的对象是否有引用指向它,如果没有引用指向它,就视为垃圾对象,就会被young gc回收,剩下的有引用指向的对象放到s1区,young gc回收垃圾的时候会暂停所有线程,暂停时间长了用户会感觉响应时间慢了,这是第一次young gc,第一次young gc的时候s2区是空的,eden区满了会触发young gc,young gc只会发生在eden区,不会在存活区触发
第二次young gc
eden区和s1区都满了判断是否有引用指向它,如果有引用指向它,eden区的对象会直接放到s2区,同时s1区有引用指向它的对象也会直接放到s2区,没有引用对象指向的被回收掉了,s1是空的,位置互换,在这个过程中一直有一个存活区,这是第二次young gc,第二次young gc的范围变大,也会判断s1里面的对象是否有引用指向
第三次young gc
对象一直在eden区循环,s1->s2,年龄+1,s2->s1, 年龄+1,在老年代设置年龄为15,等到存活区中的对象年龄到达15时,就会直接进入老年代,eden区的对象比较大放不进去直接进入old generation,最终都放到老年代,老年代对象满了触发full gc,对整个堆内存进行垃圾回收,判断是否有引用对象指向,没有引用对象的直接被干掉,这个时候eden区该干什么还是干什么,有引用对象的继续保留,随着时间的进行,由于代码写的不合理可能会导致内存泄露(OOM),回收时间比较长,回收会暂停线程
为什么要划分为young和old区,以及在young区划分为eden区和存活区的原因,如果不划区垃圾回收的时候会全部回收,会影响效率,为了让垃圾尽量在年轻代里面存活的周期更长一些,尽量在年轻代里面进行回收,减少对象进入老年代的频率,减少full gc的频率
New出来的对象优先放到eden区,大对象直接进入老年代,长期存活的对象(age默认=15)进入老年代,class、常量等信息jvm加载进入持久代,持久代在非堆内存,对象的动态分配原则进入老年代:存活区里相同的age对象,大小之和 >=1/2 s0,>=age的对象挪入老年代,a(1),b(2),c(3),d(4),e(2),f(6),h(2),k(9),如果b.mem+e.mem+h.mem>=1/2 s0,age大于等于2的对象都进入老年代,如果age等于2的只有一个,就看age3,以此类推,空间担保原则:每个young gc会把对象往老年代里放,在进行young gc时会预估这次放到老年代的对象是否能放得下,如果预估放进去的对象大于老年代剩余空间,放不进去,不进行young gc,直接进行full gc,空间担保原则会触发full gc

jstat -gcutil pid
看gc的大小,次数,间隔时间,相当于看java堆内存的命令,输出列从左到右依次是第一个存活区,第二个存活区,eden区,老年代,持久代,YGC是young gc的执行次数,YGCT是young gc的持续时间,FGC是full gc的执行次数,FGCT是full gc的持续时间,GCT=YGCT+FGCT,26.17是百分比
用这个命令也可以:jstat -gcutil 2173 1000(毫秒) 3(次数),正常没有问题是young gc比full gc少,jstat是看gc活动情况的命令
波谷持续上升,没有回收的对象越来越多,要内存泄露了
JVM垃圾调优的核心思想是:尽可能减少full gc的次数或延长full gc的间隔时间,减少young gc的持续时间
要么老年代,要么永久区(永久区属于非堆)会满,这两个区会发生OOM,eden区满没关系,直接进行young gc就可以,OOM会发生在老年代和持久代,老年代、持久代、System.gc()、Runtime.getRuntime().gc()和jmap -dump会触发full gc(发现内存下降了出现问题不要惊讶),这五种方式都会触发full gc,full gc会对整个堆进行回收,造成应用暂停,因此应该尽可能减少full gc的次数
war包tomcat会自动解压,启动tomcat,找到webapps下面test1文件夹里的init1.jsp这个文件,在浏览器里输入http://192.168.2.199:8080/test1/init1.jsp,出现SIZE和counter就对了,然后用webbench压这个链接,如果在页面或日志里出现OOM就可以了
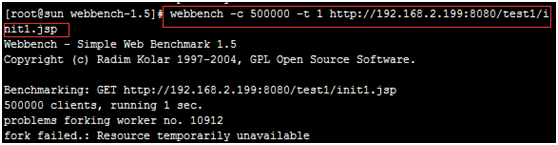
然后在浏览器里就出现了下面的OOM页面,内存泄漏是过程,内存溢出是结果
在tomcat的webapps/test1目录下,运行jmap命令
ps -ef | grep java
ps -ef | grep tomcat
jps -v:查看pid的命令
这三个命令都会查出pid,目前本机应用程序的pid是2224
jmap 2224会查看调用了哪些库,以及库的大小,没什么用
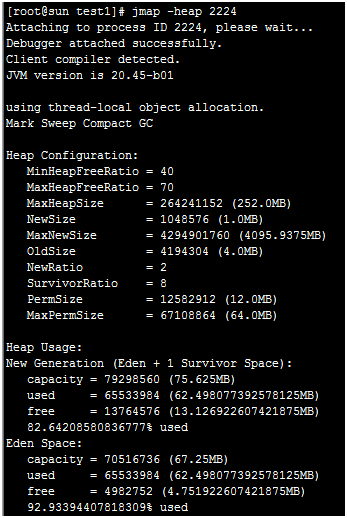
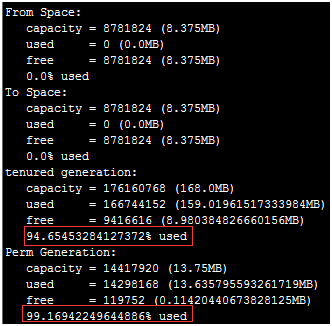
jmap -heap 2224这个命令也没什么用,都是动态变化的
最终定位是jmap -histo 2224这个命令,jmap -histo 2224 > 20150411.txt,堆内存的快照太多了,把它重定向在20150411.txt这个文件里

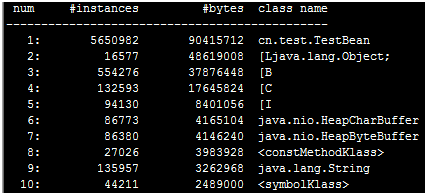
只截取了前10行,按照bytes字节大小降序进行排序的,instances是实例的个数,3、4和5行分别是bit、char和int类型的,第9行是string类型的,排在程序第一个的是test项目,cn.test是包名,TestBean是方法,这个有问题(/usr/local/tomcat7/webapps/test1/WEB-INF/classes/cn/test,test路径下有TestBean.class和TestMain.class),vi init1.jsp,打开文件,发现body体里面有10000次for循环
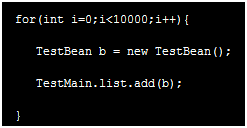
new了一个TestBean对象,并且把b放到了TestMain.list.add这个方法里了,如果没有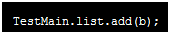 就不会出现内存溢出,会自动回收垃圾,方法有问题,new无所谓,没有引用指向它,new之后就是垃圾,但是因为
就不会出现内存溢出,会自动回收垃圾,方法有问题,new无所谓,没有引用指向它,new之后就是垃圾,但是因为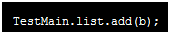 ,把
,把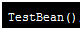 加到了那个方法里,不会释放,一直有指向它,一直在堆内存里不释放,刷一次页面生成10000个对象,造成内存满了,也不会回收,导致内存泄露,
加到了那个方法里,不会释放,一直有指向它,一直在堆内存里不释放,刷一次页面生成10000个对象,造成内存满了,也不会回收,导致内存泄露, 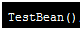 方法有问题,内存溢出只有重启服务程序才能正常运行
方法有问题,内存溢出只有重启服务程序才能正常运行
top 10看里面的方法,哪个方法导致内存泄露
解决方法:让开发在使用完这个方法之后设置为null,rbo=new ReallyBigObject(); rbo=null;
面试:
性能测试过程中发现OOM,即内存溢出的问题,排名前三的方法里是我场景正在调用的方法,然后我看代码,发现开发在调用过这个方法后没有及时的设置为null,导致内存溢出,我跟开发反映这个问题,让开发使用完代码后,将对象及时的设置为null
jmap -histo可以快速定位到前20里有自己公司的package导致的内存溢出,如果前20里只有bit,char,string,object,apache等,只能用jmap -dump生成.bin文件,用jhat或mat分析,mat建议下载v1.5版本的
在当前路径下会生成一个20150411.bin文件,jmap -dump会触发一次full gc,用jstat -gcutil pid可以发现full gc增加一次,没有MAT之前用jhat定位内存溢出的原因
jhat 20150411.bin会启动一个服务,端口是7000,访问会报oom,jhat -J-mx2048m 20150411.bin,-J后面指定的内存要小于JVM内存的大小
端口7000,在浏览器输入http://192.168.2.199:7000/
dump堆内存,分析堆内存,用MAT定位内存溢出的原因,MAT是eclipse内存分析工具,基于java heap dumps进行分析,可以发现内存溢出和减少内存消耗,功能强大
在发生内存泄露或内存使用不合理的时候才会dump堆内存,用jmap -histo ,jprofiler、jvisualvm这三款工具或dump一次用MAT分析出来,一眼就能分析出来引起内存异常或内存使用不合理的具体原因的时候,dump一次就够了,如果好多次都没有看出引起内存异常的原因的时候,多次对堆内存进行dump,从不同的dump堆内存的使用情况分析是哪些方法或内存一直没有释放或持续增加,它就有可能是造成内存泄露的原因,这是分析内存泄漏的基本原则
cpu热点分析有三种方法:分析线程和线程栈(top 20),jvisualvm抽样和jprofiler分析热点
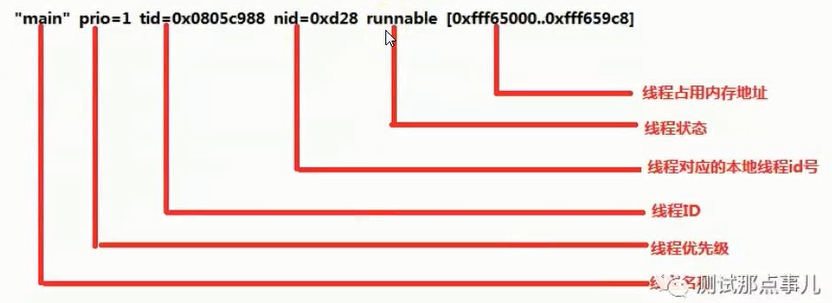
线程堆栈也称线程调用堆栈,是虚拟机中线程(包括锁)状态的一个瞬间状态的快照,即系统在某一个时刻所有线程的运行状态,包括每一个线程的调用堆栈,锁的持有情况。虽然不同的虚拟机打印出来的格式有些不同,但是线程堆栈的信息都包含:
1、线程名字,id,线程的数量等
2、线程的运行状态,锁的状态(锁被哪个线程持有,哪个线程在等待锁等)
3、调用堆栈(即函数的调用层次关系)调用堆栈包含完整的类名,所执行的方法,源代码的行数
jstack pid > 20150422.txt重定向,然后vi 20150422.txt,在20150422.txt里可以看到下面的内容,写的很详细,at后面应该还有个包名.类名

因为线程栈是瞬间快照包含线程状态以及调用关系,所以借助堆栈信息可以帮助分析很多问题,一般线程栈能分析如下性能问题:
1、系统无缘无故的cpu过高(系统态cpu高)
2、系统挂起,无响应
3、系统运行越来越慢
4、线程死锁,死循环等
5、由于线程数量太多导致的内存溢出(如无法创建新的线程栈等)
线程的状态:
1、NEW(堆栈信息里看不到),初始化状态
2、RUNNABLE(从RUNNABLE到RUNNING),等待cpu的时间片输入RUNNABLE状态,可能消耗cpu也可能不消耗cpu
3、BLOCKED,阻塞状态,互相等待,产生死锁
4、WAITING(无限等待),处于WAITING状态的线程不会消耗cpu
5、TIMED_WAITING(有超时时间,过了超时时间就变成RUNNABLE),处于挂起(parking)状态,处于TIMED_WAITING状态的线程不会消耗cpu
6、TERMINATED(堆栈信息里看不到),线程终止
监控某一个线程:
ps xH:可以查看所有存在的线程
ps -mp 12:查看PID为12的线程当前状态
多dump几次,比对线程栈有什么问题,dump线程栈用jstack,内存也是一样,多dump几次,dump内存用jmap
cpu高怎么分析?
哪种cpu占比比较高,是系统态还是用户态,如果系统态比较高,系统内核调用比较高,一般是IO读写比较高导致,一是用iostat分析是否IO队列比较长,看IO读写操作,看IOwait,二是用nmon看disk busy那页,磁盘繁忙程度超过20%,再看系统态cpu是否稍微升高,说明磁盘这有瓶颈,看是日志写的比较多,还是内存使用不合理
如果user态比较高,首先要定位到哪个系统进程,cpu用c进行排序,内存用m进行排序,可以定位到消耗cpu高的进程是哪个,一般是java进程,用这个命令top -p pid,然后按H键,可以看到Show threads off和 Show threads on进行切换,找到进程下面线程消耗的cpu比较高的pid,然后dump线程栈,从线程栈里找到对应消耗cpu高的线程在干什么事,让开发去解决哪种cpu占比较高
jstack 2113(进程pid) > 20150422.txt重定向到这个文件里面,然后vi 20150422.txt,看到线程的pid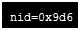 是16进制的,需要把对应的线程转换成16进制,printf "%x\n" pid,将十进制pid转成16进制的pid,按照转成16进制的线程id搜索,看到造成cpu高的原因是GC还是哪个方法导致的
是16进制的,需要把对应的线程转换成16进制,printf "%x\n" pid,将十进制pid转成16进制的pid,按照转成16进制的线程id搜索,看到造成cpu高的原因是GC还是哪个方法导致的
jstack 2113(进程pid) | grep 841(线程pid),2113是进程的pid,841是线程转码之后的pid,cat 20150422.txt | grep 841,20150422.txt是之前用这个命令dump下来的20150422.txt,也可以用ps -mp pid -o THREAD,tid,time这个命令看,如下图: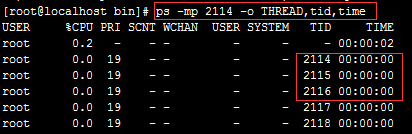
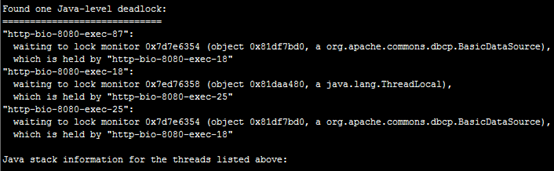
线程死锁
为什么要最小堆内存大小和最大堆内存大小一样呢?
避免频繁的申请创建堆内存和销毁堆内存造成的资源浪费
在jconsole里看到的图表cpu占用率:连接这个java进程的pid的cpu使用率,见下图:
IP和IP之间通信就会用到RMI,一直在内存里监听,New了大量的对象,导致内存自增长


导致自增长的罪魁祸首就是
尽可能用命令监控,如果命令不太会,在用图形化的东西,加速了young gc的执行时间,同时也加速了full gc的频率,图形化东西会影响性能结果
那个 按钮是full gc
按钮是full gc
有锁的线程,点击 按钮,就会把那些有锁的线程栈给检测出来了
按钮,就会把那些有锁的线程栈给检测出来了
出现OOM的时候自动生成堆dump,有参数可以设置一下
jvisualvm里抽样器为什么只能对cpu进行抽样,不能对内存抽样?
cpu既可以对本地,也可以对远程进行抽样,而内存抽样只能针对本地,不针对远程
cpu抽样过程中进行压测,刷页面,获取快照信息,jvisualvm快照里看cpu热点和组合就能分析出问题的原因了
内存泄露的做法
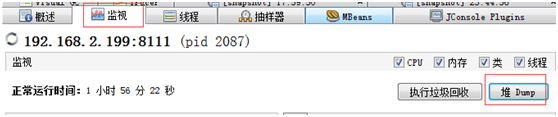 先切换到监视视图,点击堆dump按钮,弹出远程堆Dump对话框
先切换到监视视图,点击堆dump按钮,弹出远程堆Dump对话框
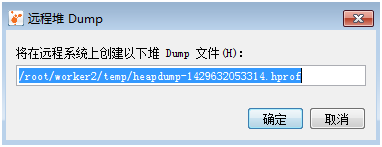
然后点击确定按钮,就会在worker2/temp路径下生成一个文件,如下图:

用sz命令将这个文件下载到本地,如桌面,然后在jvisualvm里点击文件,然后点击装入,文件类型选择
打开就能看到生成的结果了
JAVA_OPTS="$JAVA_OPTS -Xms800m -Xmx800m -Xmn400m -Xss1024K -XX:PermSize=128m -XX:MaxPermSize=128"
栈的大小通过-Xss来设置,当栈中存储数据比较多时,需要适当调大这个值,否则会出现java.lang.StackOverflowError(堆栈溢出)异常,异常的原因是递归没返回,或者循环调用造成的
为什么要配参数?
为了性能,会默认给配置一些参数,最小堆内存大小、最大堆内存大小、年轻代大小、最大持久代和最小持久代大小就可以了,垃圾回收器的配置,几个线程进行垃圾回收,线程栈的大小,配置也是为了监控,用jmap看是否生效
jvm不只在tomcat配置,也可以在resin和apache,jar里也可以配置
java内存=heap(-xmx) + stack(maxpermsize) + direct内存(如果没设置,等于heap(-xmx)),通过这个-XX:MaxDirectMemorySize指定直接内存的大小

