Linux实战监控分析

cpu进程等待会引起内存开销增加,内存开销增加会导致虚拟内存增加,虚拟内存增加会导致磁盘IO开销增加
cpu优化效率是最快的,磁盘这花的时间比较长,性能提升也比较慢,内存比较平均,分析方向:cpu->内存->磁盘->数据,cpu能显著的提升系统性能,内存比磁盘快
brk就是内存不够的时候,会通过它来申请内存
实时查看tomcat并发连接数
netstat -na | grep ESTAB | grep 8080 | wc -l
实时查看apache并发连接数
netstat -na | grep ESTAB | grep 80 | wc -l
用netstat来看当前的连接数
netstat -ant |grep ":80" | wc -l
实时检测httpd连接数
watch -n 1 -d "pgrep httpd |wc -l"
计算httpd进程占用内存的平均数
ps aux|grep -v grep|awk '/httpd/{sum+=$6};END{print sum/n}'
查看物理cpu的个数命令:
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
查看核数命令:每个物理cpu中core的个数(即核数)
cat /proc/cpuinfo | grep "cpu cores" | uniq
每个物理cpu中逻辑cpu的个数(以下两条命令都可以)
cat /proc/cpuinfo | grep "processor" | wc -l
cat /proc/cpuinfo | grep "siblings" | uniq(以上命令""或''都可以)
物理CPU:实际Server中插槽上的CPU个数,物理CPU数量,可以数不重复的physical id有几个
逻辑cpu数量=物理cpu数量*cpu cores,备注一下:Linux下top查看的CPU也是逻辑CPU个数
windows上看cpu多核命令是systeminfo,
安装sar命令是yum -y install sysstat

例如,每2秒采样一次,连续采样2次,观察CPU 的使用情况,并将采样结果以二进制形式存入当前目录下的文件ee.txt中,需键入如下命令:sar -u -o ee.txt 2(采集间隔) 2(采集次数)
监控概述:
cpu
在虚机里输入top命令,紧接着输入1,看到变成cpu0了,如图,只虚出一个核对于多核cpu来说,cpu0是相当关键的,cpu0相当于cpu中的leader,因为cpu各核间的调度都通过cpu0完成,如果cpu0的负载高,调度cpu就比较困难,就会影响其他核的性能
top命令可以看到load average后面有三个值,分别代表过去的1分钟,5分钟和15分钟的负载
Tasks是进程的状态,zombie是僵尸进程,即不受控制的进程,不退出也叫不醒
cpu包括us和sy,用户cpu就是用户进程在运行时消耗的cpu,系统cpu是系统内核消耗的cpu,id代表空闲的,wa代表等待的,等待io占用的cpu很少,ni是nice,代表优先级高的,是综合体,一般是在系统态进行,hi是硬中断,si是软中断,st是虚拟设备所消耗的cpu
top命令看到的用户态cpu不能超过100%,每个进程的cpu不能超过核数*100%,系统态cpu也不能超过100%,系统态cpu比较高,会导致iowait比较高
shift+p按照CPU进行排序,从高到低,shift+m按照内存进行排序,从高到低

PID是进程id,要是输入H,就是线程id了
USER就是属于哪个用户
PR就是优先级的级别
NI就是优先级顺序
VIRT是物理内存+共享内存+虚拟内存之和,RES是物理内存,SHR是共享内存,共享内存一般会乘以几,S是状态
TIME+运行了多长时间
如果要监控某个进程就用top -p 进程的pid,监控线程就再加上H,监控哪个线程消耗的cpu高看cpu的百分比或TIME+,TIME+是占用cpu时间片的情况
中断包括内部和外部中断,等待磁盘的io,应用程序无法继续运行,这是内部中断,等待外部设备的交换,这是外部中断
load average
负载是指一段时间内cpu正在处理+等待io的进程数之和的统计信息,即cpu使用队列的长度的统计信息,越短越好,它包含的信息不是cpu的使用率情况,反应了cpu的使用情况及申请情况,主要还是看15分钟的cpu
如何理解cpu和load
---load低,cpu使用率高
有大量的运算的时候,cpu就会很高,就一个进程,负载就是1,不高
---load高,cpu使用率低
有大量io等待进程,第三方进程,拉高了负载,系统刚启动,没消耗什么cpu
起了一个进程,会读磁盘和写磁盘,写日志是系统态还是用户态?
内核进程消耗系统的磁盘,内核去操作磁盘,就是系统态,用户不能操作磁盘,避免大量的磁盘读写,系统态占用的cpu多,用户态cpu就少,导致系统调度差,系统卡
看cpu是否有问题首先看负载,如果load average高,用vmstat看r,b,看cpu使用率,如果cpu使用率不高,看cpu使用率(主要关注us和sy),如果us高,程序消耗cpu高,找到消耗cpu高的进程,top->shift+p,top -p pid H,然后找到进程下面消耗cpu比较高的线程id,看看消耗cpu高的线程在干什么,定位到方法;如果sy高,看是否是io导致的,看读和写操作,如果是读导致的,内存不够了,从应用程序这看是有大量的从磁盘读数据,从数据库这看是否有全表扫描,大量的数据从磁盘放到内存,如果是写导致的,往磁盘写日志,写数据库,文件之间的同步,如果是中断导致的,vmstat看上下文切换高不高,如果都不是用终极命令strace
memory
在虚机里敲vmstat 1是一直监控的意思,如果vmstat 2 3就是每隔2s监控一次,一共监控3次
r:等待cpu调度的进程,已经准备好了,但cpu还未执行,如果r是0,负载就是0
b:block,等待io的进程
swpd:虚拟内存使用情况
free:空闲的内存
buff:被用来作为设备缓存的内存数,往磁盘写的文件
cache:被用来作为高速缓存,缓存是读操作,从内存到磁盘,频繁操作这块区域,缓存起来
si(从磁盘到内存),so(从内存到磁盘),s是swap,一般情况下si,so都是0,这两列表示内存交换的频繁程度,如果值过大表示内存不够
bi列表示由块设备读入数据的总量,即读磁盘,bo列表示写到块设备数据的总量,即写磁盘,b是block,如果bi+bo值过大,且wa值较大,则表示系统磁盘IO瓶颈
system下有in和cs,in是中断,cs是上下文切换,一般看cs就行,2核不超过4000就行,如果sy,hi,si比较高看cs
java程序不用关注内存使用率,因为在初始化的时候开辟一块内存供应用程序使用,最小堆内存和最大堆内存都是8G,一开机内存使用率就达到66.6%了,非java程序关注内存使用率
内存溢出是内存爆了,内存占满不能往里面丢东西了,内存泄漏是内存一滴一滴的泄漏,内存越来越小
io
在虚机里输入iostat
avg-cpu:总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值
Device:各磁盘设备的IO统计信息
tps:每秒IO次数
iostat -k(以KB为单位显示) 5(统计间隔为5秒) 2(共统计两次)
iostat -x显示更加详细的信息,监控io尽量用这个命令
r/s:每秒读取请求数(rio),w/s:每秒写入请求数(wio),每秒总的IO操作次数
avgqu -sz:平均I/O队列长度,越短越好,大于1磁盘有问题
await:平均每次设备I/O操作的处理时间,await=等待时间+svctm,单位:毫秒
svctm:平均每次设备I/O操作的服务时间(毫秒),svctm越接近于await说明等待时间少
%util:表示空闲比例
r_await:读的操作时间
w_await:写的操作时间
读操作是内存里没有这个数据,从磁盘里读出来,读操作多一般是内存不够了,频繁的从磁盘里读,select操作,从磁盘读到内存里
写操作包括写日志,数据库操作(insert,update,delete)也会往磁盘里写,以及同步(数据库主从同步,通过文件同步)
如果磁盘比较繁忙是写操作导致的就减少写操作,同理读也一样
如果有nmon直接在disk里看Busy那列就行,如果超过30%,再用iostat -x看队列,看await和svctm,如果队列长,await和svctm时间长,就是io问题,看读和写操作,如果是读导致的,内存不够了,从应用程序这看是有大量的从磁盘读数据,从数据库这看是否有全表扫描,大量的数据从磁盘放到内存,如果是写导致的,往磁盘写日志,写数据库,文件之间的同步,如果是中断导致的,vmstat看上下文切换高不高,如果都不是用终极命令strace
IO瓶颈的症状:
%util很高
await远大于svctm
avgqu -sz比较大
cpu->wa过大(参考值,超过20),通过vmstat 1命令查看
system->bi&bo过大(参考值,超过2000),通过vmstat 1命令查看
一般是由于程序优化的不合理或sql语句优化的不合理导致IO偏高或比较繁忙,IO偏高或比较繁忙不代表IO有瓶颈,有可能是由其他原因导致IO比较忙,比如说内存不够导致和IO频繁交互,IO的瓶颈是现在系统常见的问题,还没有得到良好的解决方案,而且发展也不如cpu和mem,增加cpu和增大内存都是为了变相的减少IO的交互
热点数据放在固态硬盘上,固态硬盘处理速度比机械硬盘高很多,冷点数据放在机械硬盘上

Iface:表示网络设备的接口名称
MTU:表示最大传输单元,单位是字节
RX-OK/TX-OK:表示已经准确无误地接收/发送了多少数据包
RX-ERR/TX-ERR:表示接收/发送数据包时产生了多少错误
RX-DRP/TX-DRP:表示接收/发送数据包时丢弃了多少数据包
RX-OVR/TX-OVR:表示由于误差而丢失了多少数据包
如果网络有问题RX-ERR/TX-ERR、RX-DRP/TX-DRP、RX-OVR/TX-OVR为正数,主要看这个,也可以ping www.baidu.com如果time值大于1s,网络也有问题
strace是一个功能强大的调试,分析诊断工具,主要用来监视系统调用,追踪IO问题,以centOS为例安装,使用strace前需要先在安装它,可使用命令:
yum -y install strace否则会出现:-bash: strace: command not found
安装完之后使用命令strace -f -c -p 进程pid(java进程),然后Ctrl+c,可以看到下面的页面
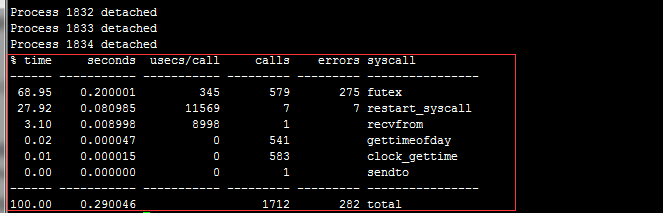
futex内核占用了68.95%的时间片,耗时0.20001秒,主动被调用了345次,被调了579次,产生的错误是275次,如果系统态cpu高的话,一定是futex这个导致的
例如,跟踪28979进程的所有系统调用(-e trace=all),并统计系统调用的花费时间,以及开始时间(并以可视化的时分秒格式显示),最后将记录结果存在output.txt文件里面。strace -o output.txt -T -tt -e trace=all -p 28979
具体参数可以看一下www.cnblogs.com/ggjucheng/archive/2012/01/08/2316692.html
lsof:lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件,所以,lsof的功能很强大。一般root用户才能执行lsof命令,普通用户可以看见/usr/sbin/lsof命令,但是普通用户执行会显示permission denied
lsof abc.txt 显示开启文件abc.txt的进程
lsof 目录名 查找谁在使用文件目录系统
sof -i :22 知道22端口被哪个进程占用
lsof -c abc 显示abc进程现在打开的文件
lsof -g gid 显示归属gid的进程情况
lsof -n 不将IP转换为hostname,缺省是不加上-n参数
lsof -p 12 看进程号为12的进程打开了哪些文件
lsof -u username 查看用户打开哪些文件
lsof -i @192.168.1.111 查看远程已打开的网络连接(连接到192.168.1.111)
具体参数可以看一下http://blog.csdn.net/xifeijian/article/details/9088137
如果压测过程中抛出too many open files,可以用lsof看哪个进程打开了多少文件,ulimit -a是看文件句柄的命令,默认看到open files是1024,可以用ulimit -n num改open files, ,改成65535
,改成65535
如何看负载机瓶颈,如果是上传和下载项目,看网络带宽是否占满,如果不是上传和下载项目,并发时看cpu卡不卡(Windows看cpu使用率用perfmon命令,在资源管理器里也可以看性能)
首先要了解架构图,画出请求业务的数据流,如果还是没有方向就在日志里打印响应时间,根据响应时间去分析问题在哪个环节
rt10s,接口2s,差8s,问题可能出在负载机、网络、web容器连接池排队,主要问题在负载机这,负载机请求一直排队


如果没有这个图就从下面的分析:
1、排查负载机,负载机好排查,看卡不卡,卡就加负载机
2、查看网络,看网络是否丢包,是否有错误率
3、服务器的硬件资源,cpu,内存,io
4、两个池子(中间件线程池和数据库连接池)是否占满,满了就有排队
5、sql执行效率,是否有慢查询,一般是select操作,自己执行一下sql看多长时间
6、gc
7、代码逻辑
1、了解系统架构图并画出
2、根据系统架构图画出被测接口请求的数据流图,并列出可能存在问题的每个点
3、
a:要么从简单的开始排查(负载机、网络、硬件)->(中间件线程池、数据库连接池)->sql执行效率->gc->code
b:要么通过系统日志打印出接口以及sql(或者web容器排队)时间,然后根据时间去判断可能存在问题的点,缩小问题的范围
如果cpu不高,io不高,内存使用不高,网络带宽使用不高,但是系统的性能上不去,啥问题?
1、代码问题
2、网络问题,压力产生没有流向后端,路由规则控制,路由有限制
| 图形界面工具 | linux命令行工具 | |
| 服务器硬件资源监控 | spot on linux、nmon, zabibix |
Top,vmstat,sar,netstat,strace,free,iostat,mpstat,dstat |
| Java监控工具 |
jconsole,jvisualvm,jprofiler,mat |
jmap,jstat,jstack |
| mysql监控工具 | spot on mysql | 慢查询,explain等 |
| 关注指标 | 监控命令 | |
| 内存 | 物理内存是否够用,是否有内存泄漏 | vmstat,jmap(针对java应用) |
| I/O | 磁盘繁忙度,是否有I/O等待 | iostat,vmstat |
| 网络 | 网络是否有阻塞 | ifstat,dstat,ping |
| CPU | cpu使用率,loadaverage | top,vmstat,strace,jstack |
