

loadrunner other
客户端环境配置:
a、IE浏览器配置推荐(IE9)
浏览器是用来录脚本,我本人习惯用IE8,IE9和火狐也可以,IE9选择32位的,就是win7系统有两个IE9,选择32的,x86
b、退出360等各种管家软件
360软件管家会影响脚本的录制
c、保证网络正常
d、保证LR正常
单独提交如何编写脚本,把详细过程以及注意事项都写出来:
a、分析协议
协议可以理解为一个约定,就是对数据包发送格式的统一约定,如果你按约定来就能识别你,也能发成功,如果你不按约定来就不认你,当前最主流的协议是WEB(HTTP/HTML),只有选对了协议才能正常的录制脚本,协议选择不对录制的脚本可能为空
b、录制脚本
使用LoadRunner性能测试工具录制脚本
c、优化脚本(去掉无用的东西)
有时录制的脚本里有一些无用的东西,要把这些东西删掉
d、强化脚本
可以在脚本里插入事务,检查点,参数化,加入一些判断条件等,让脚本更健壮
e、调试脚本(多次迭代通过才行)
脚本强化完之后还要对脚本进行调试,一定要多次迭代运行脚本
场景设计策略:
a、快增长
秒杀使用快增长策略,瞬间用户数就上来了
b、慢增长
适用于所有场景
c、用户数执行完停止场景
这种场景用的比较少
一般情况下场景设计的步骤如下:
---添加脚本
---添加压力机
---设置run time setting
---设置Schedule
性能测试场景类型:
单场景(某个页面、某个接口的单点性能):用的比较多,登录,达到开发的要求,还要压出极限值,避免上线以后背锅
混合场景:多个业务混合在一起,如发帖,回帖等,排除数据库死锁或线程死锁
稳定性场景:N*12,长时间跑看是否有内存泄漏,24小时只允许有一次full gc
Controller里Global Schedule设置,按照下图的配置即可:
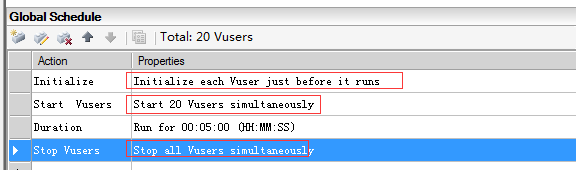
选择组模式可以跑多个脚本的时候设置时间间隔,第一个脚本选择Start immediately after the scenario begins,第二个脚本是在上一个场景开始后多长时间开始,可以设置时间
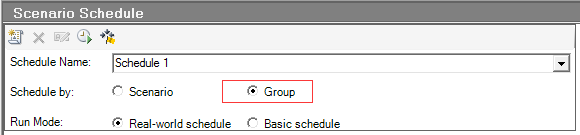
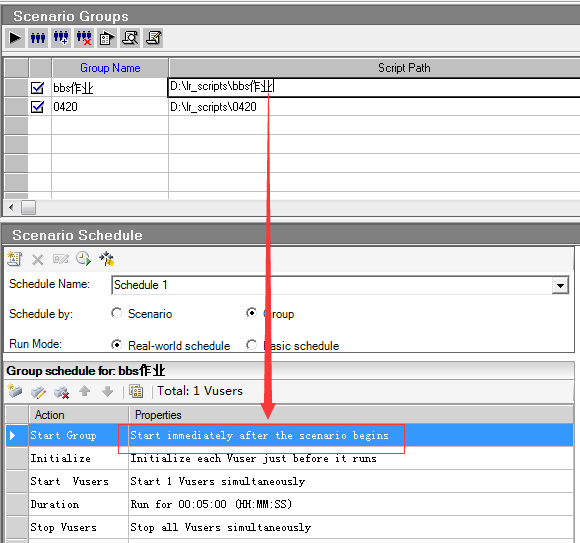
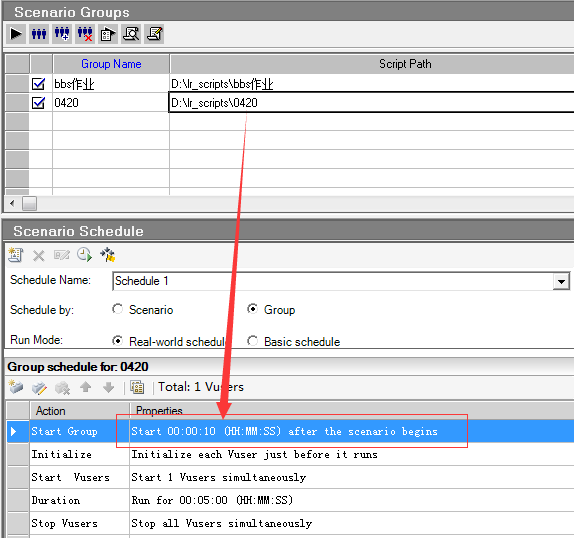
百分比模式集合点置灰,而且百分比模式不能添加虚拟用户,虚拟用户组模式可以看到集合点,可以添加vuser
递增模式:能找到最佳用户数和最大并发数
多一次跳转,多一次请求损耗,多入口也会影响性能
压力机:增加压力的机器,可以指定多个压力机对系统进行加压
监控用户最高的那个时间段,有这个数据是最好的,如果没人提供这个,建议压15-20分钟
添加压力机的一般步骤:
a、保证要联合的机器上装了LR agent,并启用了(状态栏那里会有一个小卫星)
b、本地系统的RPC服务开启(改为自动)
c、请从你的Controller的机子上登录下要联合的机子
d、关闭防火墙+杀毒+360等,拥有权限,并在同一个网段内
A地点压B地点(机房)的机器,要求很大的并发,选择压力机的原则是在机房选择压力机,能避免带宽瓶颈
Loadrunner工作原理:
LoadRunner启动以后,在任务栏会有一个Agent进程,通过Agent进程,监视各种协议的Client与Server端的通讯,使用自带的一套C语言函数将录制下来的用户操作转化为脚本,LoadRunner调用这些脚本向服务器发出请求,并接收服务器的响应,至于服务器内部如何处理,它并不关心
EXTRARES中的图片是放在静态服务器上的,对测试的影响不是很大,静态文件浪费带宽,真正有瓶颈的是动态的,如果你是想做系统的性能预估,那么可以保留EXTRARES中的内容,但是如果这里的内容是与系统毫无关系的建议删除掉
html录制的脚本比较简洁直观,每个录制出来的请求只包含web_submit_data,web_url这两个函数,能把隐藏域中的数据抓出来,非常容易理解和维护, 在回放时,html脚本积极地解析返回的信息来获得要下载的资源,缺点是脚本回放需要更多的cpu和内存,web_url的请求方式是GET请求方式,拿页面数据的,web_submit_data函数是提交数据的,是POST请求方式,web_submit_data()函数能把隐藏域中的数据抓出来,而web_submit_form()不能
接口类型:
HTTP接口:通过GET或POST来获取数据,在数据处理上效率比较高,get请求的body里为空,post请求参数值可以放在ITEMDATA里,也可以放在Body里
webservice接口:通过soap协议来获取数据,比起HTTP来说能处理更加复杂的数据类型,对于移动、电信使用webservice接口
缓存产生的原因:通过缓存读取数据要比从磁盘读取快,工人如cpu,车间如内存,仓库如磁盘,车间越大越好
API(Application Programming Interface),就是接口
sprintf函数的作用是把格式化的数据写入某个字符串中然后打印出来
web_add_header("name","value")请求头函数,把值塞到属性里
lr_save_string("192.168.0.99","ip")函数的用法是把第一个值保存到第二个里
lr_output_message(lr_eval_string("{Param_qqCheckOnlineResult}"))
lr_eval_string函数主要是返回脚本的一个参数当前的值,以lr_eval_string("{title_count}")为例,取出title_count的值,lr_eval_string函数一般和文本检查点配合使用,查询文本检查点查询到的文本次数,通过atoi(lr_eval_string("{title_count}"))这样的方式和0进行比较,lr_eval_string函数放在脚本,Action()部分里最后一个web_url()函数的后面,return 0的前面
if(atoi(lr_eval_string("{title_count}"))!=0)
{
lr_output_message("发帖成功");//输出日志,输出来是黑色的
}
else
{
lr_error_message("发帖失败");//输出日志,输出来是红色的
}
web_image_check("imcheck","Src=图片的相对路径",LAST)是图像检查点函数,要放在请求的后面,第一个参数可以随便,叫什么名字都可以,第二个参数是图片的相对地址, 如何查找图片的相对地址呢,首先找到要设置成图片检查点的图片,点击鼠标右键,点击属性按钮,就可以看到图片的地址,去掉登录页面的URL剩下的部分就是图片的相对地址,设置成图片检查点后,还要设置一下,在LR脚本页面点击Vuser按钮,找到Run_Time_Settings,在Preferences标签里找到Checks选项,勾选Enable Image and text check,就是设置图片和文本检查点的前置条件就是勾选上Enable Image and text check,无论是文本检查点还是图片检查点检查的都是源码,HTML的源文件,源码里Src对应的相对路径,如果Src那里填上绝对路径就会查不到,而且还会报错
为什么jmeter比loadrunner测的并发会大一些?
jmeter比loadrunner测的响应时间会短一些,loadrunner比jmeter测的准确一些
loadrunner和jmeter都是完整的接收返回结果,才能发送下一次请求,ab,webbench的响应时间是建立第一次握手,只包括发送时间,只判断服务器状态2X,响应时间短,自然并发就会多一些,不接收服务器返回结果,只握手不挥手,因为测试是面向用户的,要接收返回结果,我是用loadrunner测试的,以我的为准
ab,webbench和cpu的关系,测试并发不一样,cpu越多,发出的请求越多,并发越多
ab、webbench比 loadrunner 、jmeter并发多很多,jmeter比loadrunner测的响应时间会短一些,loadrunner比jmeter测的准确一些,并发过万的话用ab,webbench,他们没有license的限制,并发不到1万的话用哪个工具都行,jmeter性能测试的tps比loadrunner的大10倍,因为jmeter默认勾选了Use KeepAlive,链接不会断开,还使用这个链接通道
在多大并发下的响应时间,在多长响应时间内的并发数,按照开发的角度定义事务,响应时间不包括前端页面的加载
从负载机发起压力,到最终负载机接收到整个数据包结束,end transaction结束,这个过程是loadrunner的响应时间
为什么不用lr自带的linux监控?
第一要在被测的Linux服务器上安装rpc.rstatd rpcinfo -p,并且启动起来才能监控
第二当被监控的机器压力上来之后,Linux会将无关紧要的进程kill掉来释放一些资源,这就是为什么用lr监控到中间就没有了,抓到的数据断掉了
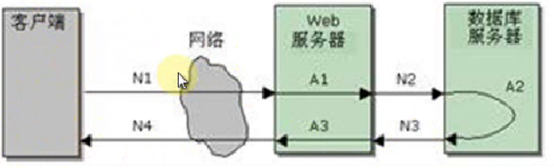
客户端是负载机(Windows或Linux),Web服务器和数据库服务器是操作系统程序,Web服务器下面是Web服务器中间件,中间件下面是应用程序本身,性能测试的数据流转过程就是从发送请求开始到接收到请求结束,就在这个区域里,各个环节都要监控起来,剩下的过程就是一步一步排查

