
《软件性能测试分析与调优实践之路》第二版-手稿节选-Mysql数据库性能定位与分析
在做MySQL数据的性能定位前,需要先知道MySQL查询时数据库内部的执行过程。只有弄清SQL的执行过程,才能对执行过程中的每一步的性能做定位分析。如图6-2-1所示。
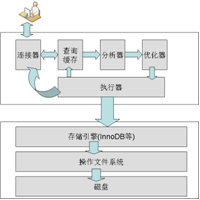
图6-2-1
从图中可以看到,当查询出数据以后,会将数据先返回给执行器,此时执行器先将结果写到查询缓存里面,这样在下次查询相同的数据时,就可以直接从缓存中查询并且返回,同时将结果返回给客户端。分析器会对待查询的SQL语句做执行计划的分析,而优化器会对SQL语句做重新优化,以便SQL的查询性能达到最佳。
6.2.1 慢SQL -> 关注清哥聊技术公众号,了解更多技术文章
每条SQL语句在执行时都需要消耗一定的I/O资源,SQL语句执行的快慢直接决定了硬件资源被占用时长的长短,慢SQL一般指查询很慢的SQL语句。在MySQL数据库中,可以通过慢查询来查看所有执行超时的SQL语句。在默认情况下,一般慢SQL是关闭的,可以通过执行show variables like 'slow_query%' 来查看数据库是否开启了慢查询,如图6-2-2所示。

从图6-2-2中看到slow_query_log的值为OFF表示慢查询未开启,可以通过执行命令“set global slow_query_log=1; ”或者“set global slow_query_log=ON;”来临时开启慢查询,如图6-2-3所示。

如果需要永久开启,就需要修改/etc/my.cnf配置文件,在[mysqld]处加入如下配置,再重启数据库即可生效,如下所示。
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
slow_query_log=ON
slow_query_log_file=/var/lib/mysql/localhost-slow.log
修改完成重启数据库后,再次执行show variables like 'slow_query%',发现慢查询已经被开启,如图6-2-4所示。

通过执行“show variables like 'long_query%';”可以查询慢查询的记录时间,如图6-2-5所示。慢查询的记录时间默认是10秒,可以通过执行“set long_query_time=需要修改的时长;”来修改慢查询的记录时间。

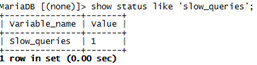
通过执行“show status like 'slow_queries';”可以查看慢查询发生的次数,如图6-2-6所示。
从慢查询日志中,我们也可以看到慢查询发生的详细信息,如图6-2-7所示。慢查询日志中会记录每次慢查询发生的时间、执行查询时的数据库用户、线程id、查询执行的SQL语句等信息。

在获取到慢查询的SQL语句后,就可以借助数据库的执行计划来对慢查询的SQL语句做进一步的分析。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
6.2.2 执行计划
在MySQL中使用explain关键字可以模拟查看数据库是如何执行SQL查询语句,也就是常说的查看一条SQL语句在数据库中的执行计划。图6-2-8所示就是执行EXPLAIN SELECT * FROM test.test 后返回的SELECT * FROM test.test查询的执行计划。

查询结果返回的字段说明如下所示。
(1)id。查询的顺序编号,表示查询中执行的顺序。id的值越大,执行的优先级越高;如果id相同,则从上往下执行。
(2)select_type。查询类型,常见查询类型说明如下:
- SIMPLE:表示简单查询方式。SQL语句中一般不会不使用UNION和子查询等。
- PRIMARY:表示包含子查询的SQL语句的最外层查询语句的查询类型,即当查询中包含子查询时,最外层的查询语句就会显示为PRIMARY。
- UNION:在查询语句中,如果在UNION关键字之后出现了第二个SELECT,则被标记为UNION。
- UNION RESULT:表示查询中有多个查询结果集执行UNION操作。
- DEPENDENT UNION:表示在子查询中存在UNION操作时,从UNION之后的第二个及之后的SELECT语句都是DEPENDENT UNION。
- DEPENDENT SUBQUERY:子查询中UNION 中第一个SELECT查询为DEPENDENT SUBQUERY。
- SUBQUERY:子查询内层查询的第一个SELECT。
- DERIVED:在查询语句中,如果from子句的子查询中出现了union关键字,则外层select查询将被标记为DERIVED。
- MATERIALIZED:表示子查询被物化,物化通过将子查询结果作为一个临时表来加快查询执行速,从而能够使得子查询只执行一次。
- UNCACHEABLE SUBQUERY:表示查询结果集无法缓存的子查询,需要逐次查询。
- UNCACHEABLE UNION:表示子查询不可被物化,需要逐次运行(即需要执行多次) (节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
(3)table。查询涉及的表名或者表的别名。
(4)type。表示表连接的类型,包括的类型说明如下。这些类型的性能从高到低的顺序是null→system→const→eq_ref→ref→fulltext→ref_or_null→index_merge→unique_subquery→index_subquery→range→index→ALL。
- null:表示不访问任何的表。
- system:表示表中只有一条记录,相当于系统表。一般可以认为是const类型的特例。
- const:表示主键或者唯一索引的常量查询,表中最多只有1行记录符合查询要求。通常const使用到主键或者唯一索引进行定值查询、常量查询,查询的速度非常快。
- eq_ref:表示join 查询过程中,关联条件字段使用主键或者唯一索引,出来的行数不止一行。eq_ref是一种查询性能很高的 join 操作。
- ref:表示非聚集索引的常量查询。
- fulltext:表示查询的过程中,使用了fulltext类型的索引。
- ref_or_null:跟ref查询类似,在ref的查询基础上会多加一个null值的条件查询。
- index_ merg:表示索引联合查询。
- unique_ subquery:表示查询使用主键的子查询。
- index_subquery:表示查询使用非聚集索引的子查询。
- range:表示查询通过使用索引范围的查询。一般包括:=、<>、>、>=、<、<=、IS NULL、BETWEEN、IN、<=> 等范围。
- index:表示通过索引进行扫描查询。
- ALL:表示全表扫描,性能最差。
(5)possible_keys。查询时预计可能会使用的索引。这里说的索引只是可能会用到,实际查询不一定会用到。
(6)key。实际查询时真实使用的索引。
(7)key_len。使用的索引长度。
(8)ref 。关联信息。
(9)rows。查询时扫描的数据记录行数。
(10)extra。表示查询特性的使用情况。常用的查询特性如下所示:
- Using index:表示使用了索引(通常也可以叫覆盖索引)。
- Using index condition:表示使用了索引进行过滤。
- Using MRR:表示使用了索引进行内部排序。
- Using where:表示使用了where条件。
- Using temporary:表示使用了临时表。
- Using filesort:表示使用文件排序(一般指无法利用索引来完成的排序)。
6.2.3 MySQL数据库性能定位步骤
MySQL数据库性能定位的常见步骤总结如图6-2-8所示。
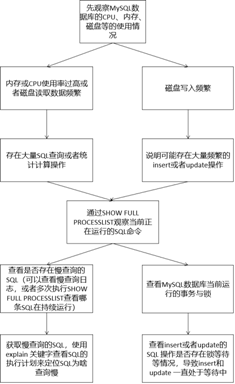
图6-2-8
(1)首先通过本书第2章中服务器的性能监控与分析,找到当前服务器的资源使用情况,重点关注CPU、内存、磁盘等使用率。
(2)根据服务器资源的使用率情况,初步判断当前MySQL数据库可能在执行的操作类型。(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)
- 如果是内存和CPU使用率过高,或者磁盘读取数据频繁,说明可能存在大量SQL查询或者统计计算操作。
- 如果是磁盘写入频繁,说明可能存在大量频繁的insert或者update 操作。
(3)通过在数据库中执行SHOW FULL PROCESSLIST 命令观察当前正在运行的SQL 命令,可以每间隔5~10s 多执行几次该命令,找到哪些SQL操作是持续一直在运行中。
- 如果是insert 或者update 语句,通过查看本书的6.1.2小节中的知识讲解,来查看MySQL数据库当前运行的事务与锁,获取insert 或者update的SQL操作是否存在锁等待等情况,从而导致insert和update 一直处于等待中。
- 如果是查询操作,可以结合慢查询日志一起,找到慢查询的SQL语句,使用explain关键字查看SQL的执行计划来定位SQL为什么查询慢。
(节选自《软件性能测试、分析与调优实践之路》(第2版),作者张永清,转载请注明出处)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号