
Java简单模拟登陆和爬虫实例---博客园老牛大讲堂
鉴于有人说讲的不清楚,我这里再详细补充一下:更新日期:2017-11-23
本片文章适合初学者,只简单说了一下爬虫怎么用,和一个简单的小实例。不适合你的就可以不看了。----博客园老牛大讲堂
1、什么是爬虫?
个人推荐:什么是网络爬虫
个人解释:网路爬虫其实就是拷贝网页源代码。
例如:我写了个网站:http://www.qe14053716.icoc.me/,你想获取里面的数据咋办?java的话肯定是把网站的源代码全部拿过来,把想要的数据给分析出来就完事了!
百度爬虫:百度是个搜索引擎,它的工作是什么呢?其实就是不断的把你的源代码拿过去,之后你的数据就泄漏了。
例如:我的博客园老牛大讲堂,这篇文章百度会每隔一段时间爬取一下,这样大家就能通过百度搜索到我的文章了。
例如:现在出了不仅仅是博客园,还有其他的:新浪,博客等,还有一下不知名的博客园之类的,因为他们没有用户,没有人发文章咋办?
所以就爬取别人的网站,来发表到自己的内容上。
防爬虫:怎么防止爬虫,像这种公开的博客园,无法防止爬虫,因为博客园需要爬虫来做推广!所以我加了防伪标志-----博客园老牛大讲堂,
不管这篇文章被爬虫了多少遍,我的博客园老牛大讲堂永远都会在,你们可以查看我的原文章了!
常见的爬虫技术:
现在网路上出了很多爬虫技术:八爪鱼、神箭手,这些都做的比较成熟了,好像是免费的。可以使用(我没用过,不介绍了)
我介绍的是爬虫常见的技术之一:jsoup爬虫
2、jsoup爬虫优缺点?---博客园老牛大讲堂
缺点:1,抓网页有点慢,2、抓静态网页比较好。如果里面涉及到一些动态的网页,可能抓不出来。
缺点太多了,现在主流一般不用jsoup,因为现在动态网页居多,jsoup爬取动态网页效果太差。所以不用
如果使用,也一般jsoup技术和其他技术一块来用,方便爬取网页。
3、怎么爬虫?---博客园老牛大讲堂
例子:这里用了jsoup爬虫。这里的用户名,密码因为涉及到其他的,所以你懂的。
这里的例子需要一个jar包:jsoup-1.8.1 自己下。里面用的是jsoup爬虫
1)爬取网页----博客园老牛大讲堂
不需要登陆就能获取的网页数据。
public class A { // 返会一个网页的所有代码 public String getjsoup() {//返回一个网页的所有代码,get获取内容的方式。
Document doc = Jsoup .connect("http://www.baidu.com") .timeout(1000).get();
return doc.text(); }
public static void main(string[] args){
System.out.println(getjsoup());
}
}
2)模拟登陆----博客园老牛大讲堂
需要登陆的网页,获取后面的内容
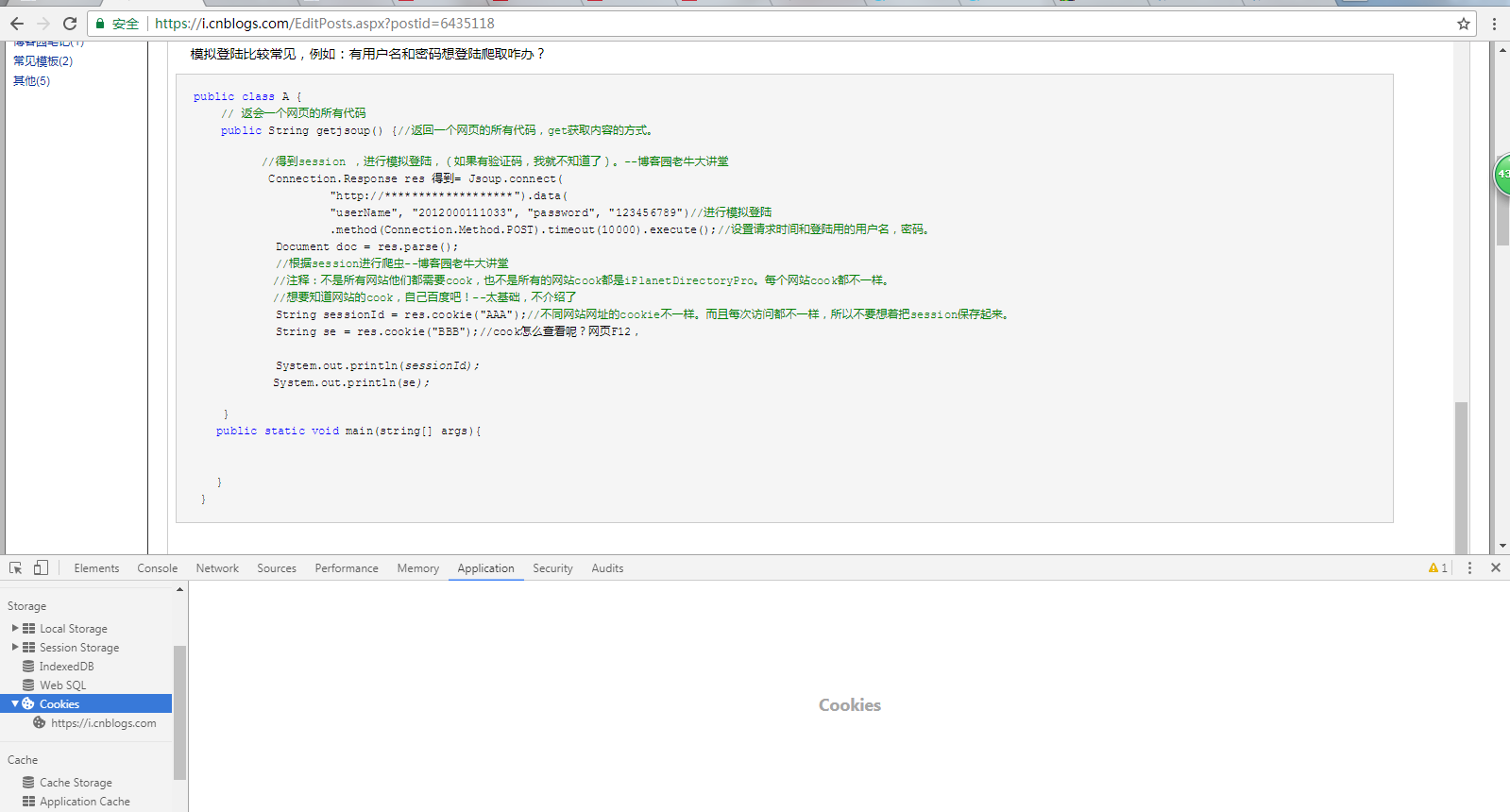
模拟登陆比较常见,例如:有用户名和密码想登陆爬取咋办?
首先获取网页的cook是多少才行。
public class A { // 返会一个网页的所有代码 public String getjsoup() {//返回一个网页的所有代码,get获取内容的方式。
//得到session ,进行模拟登陆,(如果有验证码,我就不知道了)。--博客园老牛大讲堂 Connection.Response res 得到= Jsoup.connect( "http://*******************").data( "userName", "2012000111033", "password", "123456789")//进行模拟登陆 .method(Connection.Method.POST).timeout(10000).execute();//设置请求时间和登陆用的用户名,密码。 Document doc = res.parse(); //根据session进行爬虫--博客园老牛大讲堂
//注释:不是所有网站他们都需要cook,也不是所有的网站cook都是iPlanetDirectoryPro。每个网站cook都不一样。
//想要知道网站的cook,自己百度吧!--太基础,不介绍了 String sessionId = res.cookie("AAA");//不同网站网址的cookie不一样。而且每次访问都不一样,所以不要想着把session保存起来。 String se = res.cookie("BBB");//cook怎么查看呢?看下面
System.out.println(sessionId);
System.out.println(se);
Document objectDoc = Jsoup.connect(
"http://www.****.com").cookie(//里面的网址(就是你想要爬取的网页)
"AAA", sessionId).cookie("BBB", se)
.timeout(10000).post();//设置请求的时间(这里设置的请求时间是10秒)
return objectDoc .text();
}
public static void main(string[] args){
System.out.println(getjsoup());
}
}cook的查看:F12-》application——》cookies查看。----博客园老牛大讲堂
3)假设你已经在控制台输出了自己想要的网页,那么下面就看具体网页的分析了
属性太多,根据不同的网站,获取方式也多种多样,之后就能得到想要的数据了
例如:
Element htmlElement = objectDoc.getElementsByClass("table_kc").get(0);//得到class为table_kc的第一个对象
Elements trElements = htmlElement.getElementsByTag("tr");//得到tr标签的所有对象
Elements divElments = trElements.get(i) .getElementsByAttributeValue("align", "left");//得到第i个标签的style为:align:left的元素,根据class进行得到对象。
4)我获取的一个网页数据(一个网页下表格里面的数据)----博客园老牛大讲堂
网页数据不同,获取方式也不同。
public class A { // 返会一个list对象 public List<String> getPersonInfo() {//返回一个list对象 List<String> list = new ArrayList<String>(); try {
//得到session ,进行模拟登陆,(如果有验证码,我就不知道了)。--博客园老牛大讲堂 Connection.Response res 得到= Jsoup.connect( "http://**********").data( "userName", "2012000111033", "password", "123456789")//进行模拟登陆 .method(Connection.Method.POST).timeout(10000).execute();//设置请求时间和登陆用的用户名,密码。 Document doc = res.parse(); //根据session进行爬虫--博客园老牛大讲堂
//注释:不是所有网站他们都需要cook,也不是所有的网站cook都是iPlanetDirectoryPro。每个网站cook都不一样。
//想要知道网站的cook,自己百度吧!--太基础,不介绍了 String sessionId = res.cookie("AAA");//不同网站网址的cookie不一样。而且每次访问都不一样,所以不要想着把session保存起来。 String se = res.cookie("BBB"); Document objectDoc = Jsoup.connect( "http://www.****.com").cookie(//里面的网址(就是你想要爬取的网页) "AAA", sessionId).cookie("BBB", se) .timeout(10000).post();//设置请求的时间(这里设置的请求时间是10秒) Element htmlElement = objectDoc.getElementsByClass("table_kc").get(0);//得到class为table_kc的第一个对象 Elements trElements = htmlElement.getElementsByTag("tr");//得到tr标签的对象 System.out.println(trElements.size());//输出多少个tr标签 for (int i = 1; i < trElements.size(); i++) { Elements divElments = trElements.get(i) .getElementsByAttributeValue("align", "left");//根据class进行得到对象。 for (int j = 0; j < trElements.size(); j++) { Element d = divElments.get(j);//获取每一个对象 list.add(d.text());//得到这个对象对应的值 } } } catch (IOException e) { e.printStackTrace(); } return list; }
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号