第三篇 深度优先和广度优先

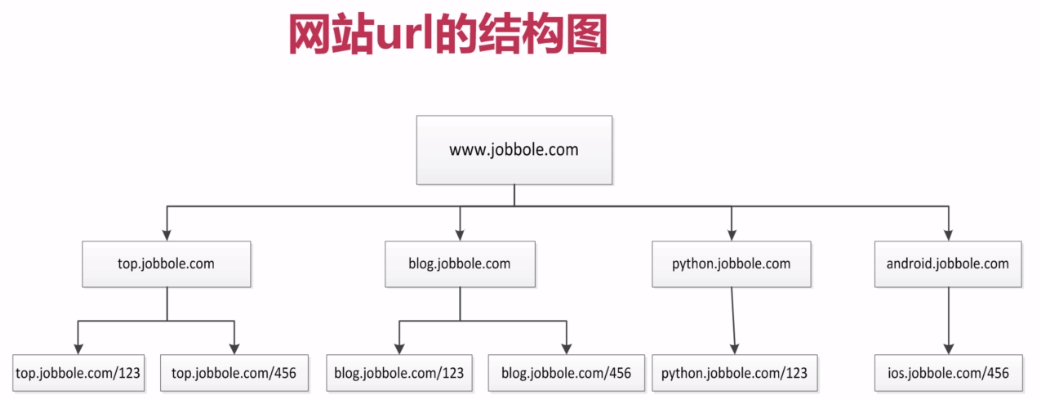
PS:一个网站下除了主域名,还会有多个子域名 需要通过遍历把所有域名取到

深度优先的算法,根据上面的截图,爬取url的顺序是A--B--D--E--I---C--F-G--H,实际上深度优先算法是通过递归算法来实现的
而广度优先和深度优先区分开来,会分层爬取,把同一层级的兄弟节点爬取完后,才会继续爬下一层

深度优先算法:
(1)访问初始顶点v并标记顶点v已访问。
(2)查找顶点v的第一个邻接顶点w。
(3)若顶点v的邻接顶点w存在,则继续执行;否则回溯到v,再找v的另外一个未访问过的邻接点。
(4)若顶点w尚未被访问,则访问顶点w并标记顶点w为已访问。
(5)继续查找顶点w的下一个邻接顶点wi,如果v取值wi转到步骤(3)。直到连通图中所有顶点全部访问过为止。
广度优先算法:
(1)顶点v入队列。
(2)当队列非空时则继续执行,否则算法结束。
(3)出队列取得队头顶点v;访问顶点v并标记顶点v已被访问。
(4)查找顶点v的第一个邻接顶点col。
(5)若v的邻接顶点col未被访问过的,则col入队列。
(6)继续查找顶点v的另一个新的邻接顶点col,转到步骤(5)。直到顶点v的所有未被访问过的邻接点处理完。转到步骤(2)。
#深度优先过程 def depth_tree(tree_node): if tree_node is not None: print(tree_node._data) if tree_node._left is not None: return depth_tree(tree_node._left) if tree_node._right is not None: return depth_tree(tree_node._right) #广度优先过程 def level_queue(root): """ 利用队列实现树的广度优先遍历 :param root: :return: """ if root is None: return my_queue = [] node = root my_queue.append(node) while my_queue: node my_queue.pop(0) print(node.elem) if node.lchild is not None: my_queue.append(node.lchild) if node.rchild is not None: my_queue.append(node.rchild)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号