Python scrapy爬虫-单例模式
Scrapy爬虫框架:
包含如下主要文件:
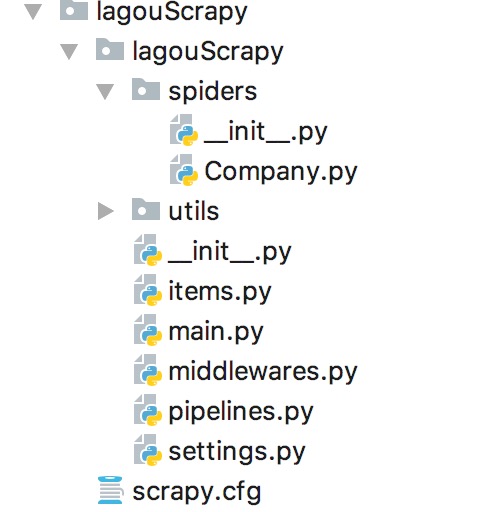
例如爬取XX网站公司信息
当在在终端指定位置创建 爬虫工程,如上文件均都会存在:
scrapy startproject lagouScrapy
----------
scrapy.cfg:
[settings]
default = lagouScrapy.settings
[deploy]
#url = http://localhost:6800/
project = lagouScrapy
配置文件,用来配置整体变量:settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for lagouScrapy project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lagouScrapy'
SPIDER_MODULES = ['lagouScrapy.spiders']
NEWSPIDER_MODULE = 'lagouScrapy.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lagouScrapy (+http://www.yourdomain.com)'
MY_USER_AGENT=["Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"
]
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
HTTPERROR_ALLOWED_CODES = [301]
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'lagouScrapy.middlewares.LagouscrapySpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'lagouScrapy.middlewares.LagouscrapyDownloaderMiddleware': 543,
#}
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
# 'bossScrapy.middlewares.BossscrapyDownloaderMiddleware': 543,
'lagouScrapy.middlewares.MyUserAgentMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'lagouScrapy.pipelines.LagouscrapyPipeline': 300,
#}
ITEM_PIPELINES = {
'lagouScrapy.pipelines.MySQlscrapyPipeline':3
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# mysql
MYSQL_HOST = 服务器名
MYSQL_PORT = 端口号
MYSQL_USER= 用户名
MYSQL_PASSWD= 密码
MYSQL_DB = 服务器下数据库名
管道传输文件,用来传输数据:
pipelines.py :
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from twisted.enterprise import adbapi
from datetime import datetime
class LagouscrapyPipeline(object):
def process_item(self, item, spider):
return item
class MySQlscrapyPipeline(object):
'''
采用异步的方式插入数据
'''
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host=settings["MYSQL_HOST"],
port=settings["MYSQL_PORT"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWD"],
db=settings["MYSQL_DB"],
use_unicode=True,
charset="utf8",
)
dbpool = adbapi.ConnectionPool("pymysql", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
'''
使用twisted将mysql插入变成异步
:param item:
:param spider:
:return:
'''
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error)
def handle_error(self, failure):
# 处理异步插入的异常
print(failure)
def do_insert(self, cursor, item):
insert_sql = "insert into company_info_scrapy(city,firm_name,firm_link,recruit,comment,lastLoginDate,brand,finance_type,firm_size,lats,address,currentDate) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(insert_sql, (item["city"],
item["name"], item["link"], item["recruit"], item["comment"],
item['last_login_Date'], item["brand"], item["firm_type"],
item["firm_size"], item["lats"], item["address"],str(datetime.today())))
下载中间件,可以设置访问模式,同异步模型:middlewares.py:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class LagouscrapySpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class LagouscrapyDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class MyUserAgentMiddleware(UserAgentMiddleware):
'''
设置User-Agent
'''
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent
对象:item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LagouscrapyItem(scrapy.Item):
# define the fields for your item here like:
city = scrapy.Field()
name = scrapy.Field()
# 直聘链接路径
link = scrapy.Field()
# 招募人数
recruit = scrapy.Field()
comment = scrapy.Field()
# 最近登录时间
last_login_Date = scrapy.Field()
# 公司融资情况
brand = scrapy.Field()
# 公司类型
firm_type = scrapy.Field()
# 公司规模
firm_size = scrapy.Field()
# 公司地址
lats = scrapy.Field()
address = scrapy.Field()
爬虫步骤:spider.Company.py
# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy.http import Request
import datetime
from urllib import parse
import time
# from lagouScrapy.lagouScrapy.items import LagouscrapyItem
from lagouScrapy.items import LagouscrapyItem
import json
import sys
# 记载每天爬取失败的公司
base_dir=sys.path[0]+'/utils/company-exception.txt'
f1 = open(base_dir, 'a+')
# 需要实时为何链接,避免访问异常导致链接遗漏
url="https://www.lagou.com/gongsi/"
# 1:链接爬取
Links=[]
fp1=open(sys.path[0]+'/utils/company.txt')
datas=fp1.read()
datas=datas.split('\n')
datas=sorted(datas)
Links=[]
fp1=open(sys.path[0]+'/utils/company-1.txt')
datas=fp1.read()
datas=datas.split('\n')
datas=sorted(datas)
for i in range(100780,151000):
temp = url + str(i) + '.html'
Links.append(temp)
# https://www.lagou.com/gongsi/451.html
class PageSpider(scrapy.Spider):
name = "Company"
allowed_domains = ["www.lagou.com"]
start_urls=[]
start_urls =Links
def parse(self, response):
try:
link = response.url
link_no = re.sub('\D', "",link[29:35])
companyInfoData = response.xpath('//script[@id="companyInfoData"]/text()').extract()
lats = ""
address_list = ""
if companyInfoData!=[]:
dd = json.loads(companyInfoData[0])['addressList']
for it in dd:
sts= it['detailAddress']
if 'lng' in it.keys():
lats = lats + '|' + str(it['lng']) + ',' + str(it['lat'])
address_list = address_list + "|" + sts.replace("\n", "").strip()
company_main = response.xpath('//div[@class="company_info"]')
name = company_main.xpath('//div[@class="company_main"]/h1/a')[0].attrib['title']
info = company_main.xpath('//div[@class="company_data"]/ul/li/strong/text()').extract()
# 招募人数
recruit = info[0].replace("\n", "").strip()
comment = info[3].replace("\n", "").strip()
# 最近登录时间
last_login_Date = info[4].replace("\n", "").strip()
company_basic = response.xpath(
'//div[@id="basic_container"]/div[@class="item_content"]/ul/li/span/text()').extract()
brand = company_basic[0]
firm_type = company_basic[1]
firm_size = company_basic[2]
city = company_basic[3]
item = LagouscrapyItem()
item['city'] = city
item['name'] = name
item['link'] = link
item['recruit'] = recruit
item['comment'] = comment
item['last_login_Date'] = last_login_Date
item['brand'] = brand
item['firm_size'] = firm_size
item['firm_type'] = firm_type
item['lats'] = lats
item['address'] = address_list
yield item
except Exception as e:
# 进行验证码校验,如果验证码校验没有通过,则记载在文件中
f1.write(link_no + "\n")
pass
执行文件:main.py:
from scrapy.cmdline import execute
import sys
import os
base_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(base_dir)
# 根目录,执行命令 启动 spider
execute(["scrapy","crawl","Company"])
