
推荐算法与推荐系统--1 LR模型
1. LR介绍
逻辑回归(logistics regression)作为广义线性模型的一种,它的假设是因变量y服从伯努利分布。那么在点击率预估这个问题上,“点击”这个事件是否发生就是模型的因变量y。而用户是否点击广告这个问题是一个经典的掷偏心硬币(二分类)问题,因此CTR模型的因变量显然应该服从伯努利分布。所以采用LR作为CTR模型是符合“点击”这一事件的物理意义的。LR模型的主要发展趋势为:
- 2012年之前LR模型占据了计算广告领域的极大部分市场,目前仍广泛应用于大部分推荐系统中。
- 2014年Facebook提出GBDT+LR,利用GBDT(Gradient Boosting Decision Tree)自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型输入。
- 2017年阿里公开了5年前已经在广泛使用的MLR模型,MLR模型首先使用分割函数将数据分成多个子区域,然后针对子区域单独使用LR建模,最后再用函数将多个子区域的模型融合成一个。
LR模型的算法说明可以参考:https://www.cnblogs.com/laojifuli/p/11982764.html
2.系统架构图
逻辑回归算法的线上调用流程图如下所示:
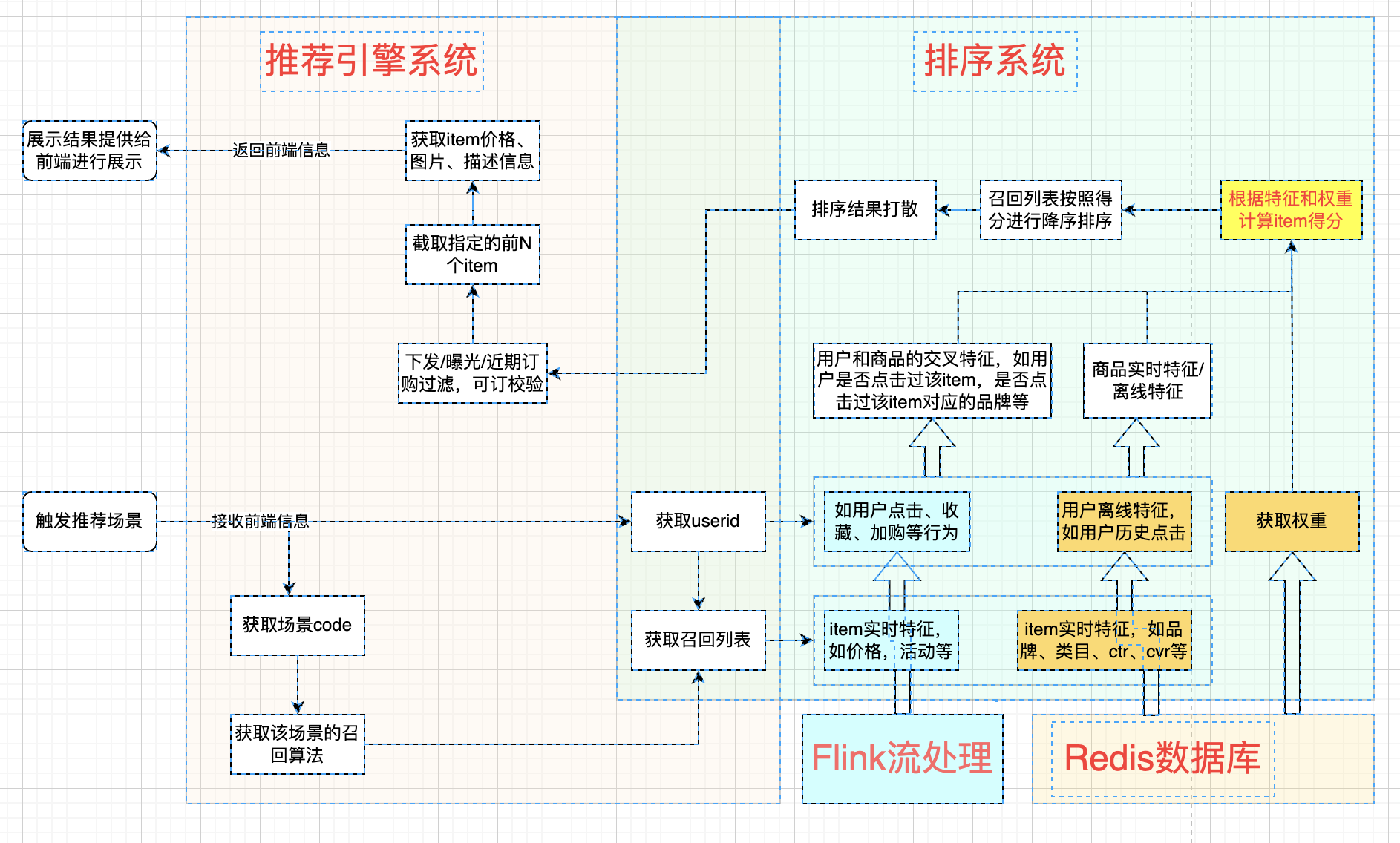
实现非常简单,只需要离线计算好逻辑回归模型的权重,并将其保存到redis数据库中。线上触发该模型后,先获取item的特征、用户和item的交互特征、模型权重,再将对应的特征和权重进行加权求和,并将求和的结果过一层sigmoid函数,即可得到每个item的逻辑回归得分。
3. 特征构建及更新
3.1 item和交叉特征
LR模型需要使用到的特征为:item特征,user和item的交叉特征(user的单独特征不会对排序结果产生影响)。
-
item特征:item固定属性,如item的价格、折扣率、类目、品牌等;item的质量属性,如昨天/过去一周/过去一个月的销量、ctr、cvr等;其他属性,如item的标题、文本描述、图片等。
-
user和item的交叉特征:商品价格是否与用户价格便好相匹配、用户历史上是否点击/订购过该商品,用户是否对相应的类目感兴趣等。
-
user单独的特征不会对排序结果产生影响,举例如下:
假设有两个item,分别记为\(i_1\)和\(i_2\),根据前两类特征已经计算出i1和i2的得分,分别记为\(s_1\)和\(s_2\),且设\(s_1>s_2\)。此时加入用用户特征记为\(f_u\),加入用户特征后的商品得分为\(snew_1=s_1+w_u*f_u\)和\(snew_2=s_2+w_u*f_u\),由于两个得分都加入了相同的值\(w_u*f_u\),因此最终得分的大小顺序是不变的。
3.2 实时特征
使用Flink对item和user的实时信息进行提取。
4. 模型调用和权重更新
模型使用时,只需要系统从redis数据库中读取到模型最新的参数,记为 w
之后读取用户和物品的离线特征
使用storm对用户近实时特征进行处理
对上述特征进行交叉操作
使用公式计算每个商品的得分
权重如何更新
每天增量更新一次参数
从数据库中提取前一天用户的所有行为数据,并按照训练集的清洗方法获得当天的模型数据
使用前一天的数据进行训练,得到新的模型参数 w_new
采用增量更新的方式 w = a * w + (1-a) * w_new
5. 服务端提供排序能力
线上如何调用特征
如何计算得分
结果打散

 浙公网安备 33010602011771号
浙公网安备 33010602011771号