
决策树--集成方法--树模型(rf、GBDT、XGB和LGB)的对比
一、熵相关内容
本章主要介绍几个关于熵的几个概念性定义,包括自信息、熵(信息熵)、联合熵、条件熵、左右熵、相对熵(KL散度)、交叉熵和softmax、信息增益(互信息)和信息增益率、条件互信息等。接下来介绍一种最大熵算法
1.1 熵的几个相关定义
1.1.1 自信息和熵(单个变量)
自信息 self-information也称为信息量,指单一事件发生时所包含的信息量。自信息表示事件发生前,时间发生的不确定性;时间发生后,事件所包含的信息量。事件发生的概率越小,则信息量越大。设\(X\)是一个离散随机变量,取值集合为\(\cal X\),变量所对应的概率分布函数为\(p(x)=Pr(X=x), x\in \cal X\),其中\(X=x\)的息量为:
\(I(x) = log(1/p(x)) = -log(p(x))\)
熵表示对自信息的加权求和,其中权重就是该信息概率。假设对于某个事件,有\(n\)种可能性,每一种可能性都有一个概率\(p(x_i)\),则信息熵可以定义为:
\(H(X) = -\underset{i=1} {\overset n \sum}log(p(x_i)) = \underset{i=1} {\overset n \sum}p(x_i)I(x_i)\)
例一台电脑:正常开机的概率为0.7,无法开机的概率是0.2,爆炸的概率是0.1,求电脑事件的信息熵是多少: \(H(X) = -\underset{i=1} {\overset n \sum}p(x_i)log(p(x_i)) = -[0.2*log(0.2)+0.7*log(0.7)+0.1*log(0.1)]=0.804\)
基尼系数的定义与熵类似,可对比记忆:\(Gini(X) = \underset{i=1} {\overset n \sum}p(x_i)(1-p(x_i)) = 1- \underset{i=1} {\overset n \sum}p(x_i)^2\)
1.1.2 联合熵、条件熵和左右熵(多变量)
联合熵:设有随机变量\((X,Y)\),其联合概率分布为: \(P(X=x_i, Y=y_j)=p(x_i,y_j)=p_{i,j}\)
则联合熵可以表示为: \(H(X,Y)=-\sum_{x,y}P(x,y)logP(x,y)\)
条件熵:\(H(Y|X) = \underset{x \in X}\sum p(x)H(Y|X=x)=\underset{x \in X}\sum p(x) \underset{y \in Y}\sum p(y|x)log(p(y|x)) \\= \underset{x \in X}\sum \underset{y \in Y}\sum p(x,y)log(p(y|x))\)
联合熵和条件熵的关系:\(H(Y|X) = H(X,Y)- H(X)\),即在联合分布的基础上,给定X的分布,就可以得到条件分布
左右熵(边界熵):多字词表达的左边界的熵和右边界的熵,分别定义如下:
$ E_L(W) = \underset{a\in A}\sum p(aW|W)logp(aW|W)$和 \(E_L(W) = \underset{b\in B}\sum p(Wb|W)logp(Wb|W)\)
实际上表达的就是某个词W出现时,与其联合出现的词的信息熵;如对于屌丝这个词,计算左信息的时候,可能会出现穷屌丝、这屌丝等,并计算这些词的熵;右信息计算的时候,可能会出现屌丝命、屌丝样等。
左右熵一般用于统计方法的新词发现。计算一对词之间的左熵和右熵,熵越大,越说明是一个新词。因为熵表示不确定性,所以熵越大,不确定越大,也就是这对词左右搭配越丰富,越多选择。
1.1.3 相对熵(KL散度)和交叉熵
相对熵也称为KL散度,用来衡量两个概率分布之间的差异。同一个随机变量\(x\)有两个单独的概率分布\(p(x)\)和\(q(x)\),使用KL散度来衡量这两个分布的差异。
\(D_{KL}(p||q)= \sum_{i=1}^np(x_i)log\frac{p(x_i)}{q_(x_i)}\)
KL散度的值越小,表示p和q的分布越接近。
交叉熵:\(H(p,q)=-\sum_{i=1}^n p(x_i)lopq(x_i) = \sum_{i=1}^np(x_i)log\frac{p(x_i)}{q_(x_i)} - \sum_{i=1}^np(x_i)logp(x_i)=D_{KL}(p||q)+H(p)\)
由于\(H(p)\)是已知分布,在模型评估时是一个固定值,因此可以使用交叉熵\(H(p,q)\)来近似\(D_{KL}(p||q)\),用于衡量\(p(x)\)和\(q(x)\)两个分布的差异。
1.1.4 信息增益(互信息)和信息增益率
信息增益反应的是在知道了X的值后,Y的不确定性的减少量,可以理解为X的值透露了多少关于Y的信息量。表示利用特征X对数据集Y分类后混乱程度降低了多少。信息增益越大,分类性越强。信息增益在词汇聚类、汉语自动分词、词义消歧、文本分类、聚类等问题的研究中具有重要作用。
\(I(X;Y) = \underset{x \in X}\sum \underset{y \in Y} \sum p(x,y) \log(\frac{p(x,y)}{p(x)p(y)})\)
重要推导:\(I(X;Y)=I(Y,X)=H(X)-H(X|Y)=H(Y)-H(Y|X)=H(X)+H(Y)-H(X,Y)\)
证明:
由于\(H(X,Y) = H(Y|X)+H(X)\) ,所以可得\(I(X;Y)=H(Y)-H(Y|X)\)
信息增益比较偏向于选择去值比较多的特征,如极端情况存在特征A,每个样本是一个取值,则此时\(H(Y|X)=\underset{x \in X}\sum \underset{y \in Y} \sum p(x,y)logp(y|x)=\frac{1}{n}*0 = 0\)
因此\(I(X;Y) = H(Y) - H(Y|X)=H(Y) - 0\),即此时X包含了所有Y的信息量
为了解决这个问题,提出了信息增益率,公式如下:
\(I_R(Y,X) = I(Y,X)/H(X)\)
条件互信息:假设\(Z\)是已知的,在知道\(Z\)的情况下,\(X\)和\(Y\)的互信息称为条件互信息,定义为
\(I(X;Y|Z)= \underset{x \in X}\sum \underset{y \in Y} \sum \underset{z \in Z} \sum p(x,y,z)log(\frac{p(z)p(x,y,z)}{p(x,z)p(y,z)})\)
并且有\(I(X;Y|Z) = I(X;Y,Z) - I(X;Z)\)
1.2 交叉熵和最大似然的关系
1.2.1 最大似然估计
设有一组训练样本\(X=\{x_1,x_2,...,x_m\}\),该样本的分布为\(p(x)\),假设使用\(\theta\)参数化模型得到\(q(x;\theta)\),现用这个模型来估计\(X\)的概率分布,得到似然函数
\(L(\theta) = q(X;\theta) = \underset{i}{\overset m \prod} q(x_i;\theta)\)
最大化似然估计就是求得\(\theta\)是的\(L(\theta)\)的值最大,也就是:
\(\theta_{ML}=\underset{\theta}{argmax}\underset{i}{\overset m \prod} q(x_i;\theta)\)
等式两边分别取log,且等式左边取\(\log(\theta)\)和\(\theta\)的趋势是一致的,且等式进行缩放也不影响最大最小值的判断,因此上式可等价为:
\(\theta_{ML} = \underset{\theta}{argmax} \frac{1}{m}\underset{i}{\overset m \sum}\log q(x_i;\theta)\)
1.2.2 最大似然与交叉熵
上式的最大化\(\theta_{ML}\)是没有和训练样本相关联的,因此需要某种变换,使其可以用训练的样本分布来表示。因为训练样本的分布可以看作是已知的,也是对最大化似然的一个约束条件。注意\(\frac{1}{m}\underset{i}{\overset m \sum}\log q(x_i;\theta)\)相当于求随机变量\(X\)的函数\(\log(X;\theta)\)的均值,根据大数定律,随着样本容量的增加,样本的算数平均值将趋于随机变量的期望,也就是说\(\frac{1}{m}\underset{i}{\overset m \sum}\log q(x_i;\theta) \rightarrow E_{x\sim P}(\log q(x;\theta))\)
其中\(E_{x\sim P}\)表示符合样本分布P的期望,这样就将最大似然估计使用真实样本的期望来表示
\(\theta_{ML}=\underset{\theta}{argmax}E_{x\sim P}(\log q(x;\theta))=\underset{\theta}{argmin}E_{x\sim P}(-\log q(x;\theta))\)
而交叉熵的定义为:\(H(p,q)=-\sum_{i=1}^n p(x_i)lopq(x_i) = E_{x\sim P}(-\log q(x))\)
从上式中可以看出,似然函数和交叉熵的定义形式是一致的。因此可以判断最大似然函数和最大化交叉熵,两个概念是等价的。
二、三种主要的决策树
本章主要介绍ID3、C4.5和Cart决策树
2.1 ID3算法
2.1.1 ID3简单介绍
机器学习算法其实很古老,作为一个码农经常会不停的敲if, else if, else,其实就已经在用到决策树的思想了。只是你有没有想过,有这么多条件,用哪个条件特征先做if,哪个条件特征后做if比较优呢?怎么准确的定量选择这个标准就是决策树机器学习算法的关键了。1970年代,一个叫昆兰的大牛找到了用信息论中的熵来度量决策树的决策选择过程,方法一出,它的简洁和高效就引起了轰动,昆兰把这个算法叫做ID3。
ID3使用信息增益来判断当前结点应该用什么特征来构建决策树。
即\(I(X;Y) = \underset{x \in X}\sum \underset{y \in Y} \sum p(x,y) \log(\frac{p(x,y)}{p(x)p(y)}) = H(Y) - H(Y|X)\)
信息增益越大,越适合用来分类。
2.1.2 ID3算法的思路
输入的是m个样本,样本输出集合为D,每个样本有n个离散特征,特征集合即为A,输出为决策树T。算法过程为:
1)初始化信息增益的阈值\(\epsilon\)
2)判断样本是否为同一类输出\(D_i\),如果是则返回单结点树T,标记类别为\(D_i\)
3)判断特征是否为空,如果是则返回单结点树T,标记类别为样本中输出类别D实例做多的类别
4)计算A中的各个特征(一共n个)对输出D的信息增益,选择信息增益最大的特征\(A_g\)
5)如果\(A_g\)的信息增益小于阈值\(\epsilon\),则返回单结点树T,标记类别为样本中输出类别D实例最多的类别
6)否则,按特征\(A_g\)的不同去值\(A_{gi}\)将对应的样本输出D分成不同的类别\(D_i\),每个类别产生一个子结点,对应的特征值为\(A_{gi}\),返回增加了结点的树T
7)对于所有的子结点,令\(D=D_i, A=A-{A_g}\)递归调用2-6步,得到子树\(T_i\)并返回
例:上面提到ID3算法就是用信息增益大小来判断当前节点应该用什么特征来构建决策树,用计算出的信息增益最大的特征来建立决策树的当前节点。这里我们举一个信息增益计算的具体的例子。比如我们有15个样本D,输出为0或者1。其中有9个输出为1, 6个输出为0。 样本中有个特征A,取值为A1,A2和A3。在取值为A1的样本的输出中,有3个输出为1, 2个输出为0,取值为A2的样本输出中,2个输出为1,3个输出为0, 在取值为A3的样本中,4个输出为1,1个输出为0.
则样本D的熵为:\(H(D)=-(9/15 \log(9/15) = 6/15 \log(6/15))=0.971\)
样本D在特征A下的条件熵为\(H(D|A)=\frac{5}{15}H(D1)+\frac{5}{15}H(D2)+\frac{5}{15}H(D2) \\=\frac{5}{15}(\frac{3}{5}\log(\frac{3}{5})+\frac{2}{5}log(\frac{2}{5})) + ...=0.888\)
所以对应的信息增益为\(I(D,A)=H(D)-H(D|A)=00.83\)
2.1.3 ID3算法的不足
ID3算法虽然提出了新的思路,但是还是有很多值得改进的地方。
1)ID3没有考虑连续特征,这大大限制了ID3的用途
2)ID3采用信息增益大的特征优先建立决策树的结点,在相同条件下取值较多的特征比取值较少的特征信息增益大
3)ID3算法对于缺失值的情况没有做考虑
4)没有考虑过拟合的问题
2.2 C4.5决策树
2.2.1 对于ID3中几个不足的改进
1)不能处理连续特征:将连续特征离散化,如m个样本的连续特征A有m个,从小到大排列\(a_1,a_2,...,a_m\),然后取相邻两样本值的平均数,一共取得\(m-1\)个划分点,其中第i个划分点\(T_i=\frac{a_i + a_{i+1}}{2}\),对于这\(m-1\)个点,分别计算以该点作为二元分类点时的增益。选择信息增益最大的点作为连续特征的二元离散分类点。比如取到的增益最大的点为\(a_t\),则小于\(a_t\)的值为类别1,大于\(a_t\)的值为类别2,这样我们就将连续特征离散化了。要注意的是,与离散特征不同的是,如果当前结点为连续属性,则该属性还可以参与子结点的生成选择过程。
2)信息增益偏向取值过多的特征:引入一个信息增益率的变量\(I_R(D,A)=\frac{I(A,D)}{H_A(D)}\),其中\(H_A(D)\)其中D为样本特征输出的集合,A为样本特征,对于特征熵\(H_A(D)\)表达式为:
\(H_A(D)=-\sum_{i=1}^n \frac{|D_i|}{|D|} \log \frac{|D_i|}{|D|}\)
其中n为特征A的类别数,\(D_i\)为特征A的第i个取值对应的样本数,|D|为样本个数。特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
3)缺失值处理:主要需要解决的事两个问题,一是在样本某些特征缺失的情况下选择划分的属性;二是选定了划分属性,对于在该属性熵缺失特征的样本的处理(即选择划分属性时的缺失值和属性选择之后的缺失值)
第一个问题是有缺失值时,如何选择属性。对于某个有缺失值的特征A,C4.5的思路是
a.将数据分成两部分,对每个样本设置一个权重(初始可以都为1)
b.划分数据,一部分是有特征值A的数据D1,另一部分是没有特征A的数据D2
c.计算D1的各个特征值的加权重后信息增益
d.计算D1样本加权后占总样本的比例,并乘以上一步得到的信息增益,作为该特征A的信息增益
第二个问题,可以将缺失值特征的样本同时划分入所有的子结点,不过将该样本的权重按各个子结点样本的数量比例来分配。比如缺失特征值A的样本a之前权重为1,特征值A有3个特征值A1,A2,A3,三个特征值对应的无缺失A特征的样本个数为2,3,4,则a同时划分入A1,A2,A3,对应的权重调节为2/9, 3/9, 4/9
4) 过拟合处理:引入正则化系数进行剪枝
2.2.2 C4.5算法的不足
1)由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。(剪枝)
2)C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。(二叉树)
3)C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。(回归和分类)
4)C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。(基尼系数和均方误差)
2.3 CART决策树
Cart既可以做分类也可以做回归,分类树使用Gini系数,回归树采用均方误差选择划分属性;二叉树而非多叉树
2.3.1 CART分类树算法的最优特征选择方法
ID3和C4.5在计算信息增益的时候,涉及到大量的对数运算,比较耗时,Cart使用基尼系数来进行代替(基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好)
在分类问题中,假设给定样本D有K个类别,第k个类别的个数\(C_k\)概率是\(p_k\),则基尼系数表达式为:
\(Gnin(p)=\sum_{k=1}^Kp_k(1-p_k)=1- \sum_{k=1}^K p_k^2 = 1- \sum_{k=1}^K (\frac{|C_k|}{|D|})^2\)
特别的,对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数为:
\(Gini(D,A)=\frac{|D_1|}{|D|}Gini(d_1) + \frac{|D_2|}{D}Gini(D_2)\)
2.3.2 连续特征和离散特征处理的改进
连续型特征:处理过程同C4.5,只是计算特征得分的时候,Cart使用的是Gini系数,C4.5使用的是信息增益率。如果当前结点是连续属性,则该属性后面还可以参与子结点的产生选择过程。
离散型特征:采用的思路是不停的二分离散特征。如果某个特征A被选取建立决策树节点,如果它有A1,A2,A3三种类别,ID3和C4.5会在决策树上一下建立一个三叉的节点。而Cart分类树会考虑把A分成\(\{A1\}\)和\(\{A2,A3\}\),\(\{A2\}\)和\(\{A1,A3\}\),\(\{A3\}\)和\(\{A1,A2\}\)三种情况,找到基尼系数最小的组合,如\(\{A2\}\)和\(\{A1,A3\}\),然后建立二叉树结点。一个结点是A2对应的样本,另一个饿结点是\(\{A1,A3\}\)对应的结点。同时由于没有把A的取值完全分开,后面我们还有机会在子结点继续选择到特征A来划分A1和A3。即切分不充分的离散特征,后续还会继续参与子结点的产生选择过程。
2.3.3 CART分类树步骤
算法输入的是训练集D,基尼系数的阈值,样本个数阈值,输出是决策树T
对于当前结点的数据集D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前结点停止递归
计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前结点停止迭代
计算当前结点现有的各个特征的各个特征值对数据集D的基尼系数
在计算出来的各个特征值对数据集D的基尼系数,选择基尼系数最小的特征A和特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2.
对左右子树结点递归的调用1~4步,生成决策树
对于生成的决策树做预测的时候,假如测试集里的样本A落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用的是这个叶子节点里概率最大的类别。
2.3.4 CART回归树的建立
CART回归树和CART分类树的建立和预测的区别主要有下面两点:1)连续值的处理方法不同,2)决策树建立后做预测的方式不同。
对于连续值的处理:CART分类树使用基尼系数的大小来度量特征的各个划分点的优劣情况,CART回归树使用均方差的大小来度量特征的各个划分点的优劣情况。对于任意划分特征A,对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点。
即 \(\underset{A,s} {min}\Big[\underset{c_1} {min}\underset{x_i \in D_1(A,s)}\sum(y_i-c_1)^2 + \underset{c_2} {min}\underset{x_i \in D_2(A,s)}\sum(y_i-c_2)^2 \Big]\)
其中\(c_1\)是\(D_1\)数据集的样本输出均值,\(c_2\)是\(D_2\)数据集的样本输出均值
对于决策树建立后做预测的方式:CART分类树采用叶子节点里概率最大的类别作为当前节点的预测类别,而回归树输出不是类别,采用最终叶子的均值或者中位数来预测输出结果。
2.3.5 CART树算法的剪枝
决策树很容易对训练集过拟合,而导致泛化能力差,为了解决这个问题,需要对CART树进行剪枝,CART采用的办法是后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。
在剪枝过程中,对于任意一时刻子树T,其损失函数为:\(C_\alpha(T_t) = C(T_t) + \alpha|T_t|\),其中\(C_\alpha(T_t)\)是循例那数据集的预测误差,\(|T_t|\)是子树T的叶子结点的数量
剪枝过程中会遇到两种情况,分别是保留子树(不做剪枝)和将子树剪掉(剪枝)
保留子树(不剪枝)时的损失为:\(C_\alpha(T_t)=C(T_t) + \alpha|T_t|\)
不保留子树(剪枝)的损失为:\(C_\alpha(T)=C(T) + \alpha\)
当\(\alpha=0\)或\(\alpha\)很小时,\(C_\alpha(T_t)<C_\alpha(T)\),当\(\alpha\)增大到一定程度时,有:
\(C_\alpha(T_t)=C_\alpha(T)\),即\(\alpha = \frac{C(T)-C(T_t)}{|T_t|-1}\)
\(T_t\)和\(T\)有相同的损失函数,但是\(T\)节点更少,因此可以对子树\(T_t\)进行剪枝,它就是将全部子节点剪掉,变为一个子节点\(T\)。当\(\alpha\)继续增大时,不等式反向。
通过上面的方法可以计算出每个子树是否剪枝的阈值\(\alpha\),如果把所有哦的结点是否剪枝的\(\alpha\)都计算出来,然后分别针对不同的\(\alpha\)所对应的剪枝后的最优子树做交叉验证,就可以得到一个最好的\(\alpha\),有了这个\(\alpha\)就可以用对应的最优子树作为最终结果
CART树的剪枝算法
输入时CART树建立算法得到的原始决策树\(T_0\),输出时最优决策子树\(T_\alpha\)
1)初始化\(k=0, T=T_0\),最优子树集合\(w={T}\)
2)\(\alpha_{min} = \infty\)
3)从叶子结点开始自下而上计算各内部节点\(t\)的训练误差损失函数\(C_\alpha(T_t)\),叶子节点数\(|T_t|\)以及正则化阈值\(\alpha = min\{\frac{C(T)-C(T_t)}{|T_t-1|}, \alpha_{min}\}\),更新\(\alpha_{min}\)
4)\(\alpha_k = \alpha_{min}\)
5)自上而下的访问子树t内部节点,如果\(\frac{C(T)-C(T_t)}{|T_t-1|}\leq \alpha_k\),进行剪枝。并决定叶节点t的值。如果是分类树,则是概率最高的类别,如果是回归树,则是所有样本输出的均值。这样得到\(\alpha_k\)对应的最优子树\(T_k\)
6)最优子树集合\(w=w \cup T_k\)
7)\(k=k+1,T=T_k\),如果T不是由根节点单独组成的树,则回到步骤2继续递归执行,否则就已经得到了所有的可选最优子树集合\(w\)
8)采用交叉验证在\(w\)选择最优子树\(T_\alpha\)
三、集成算法
3.1 集成学习简介
集成学习可以分成boosting、bagging、stacking三种主要策略。
其中boosting是一种串行结构,个体学习器之间存在强依赖关系,比较著名的算法是Adaboost;bagging是
并行结构,个体学习器之间不存在强依赖关系,著名算法有randomForest(采用boostrap有放回抽样),提升树(如GBDT、XGBoost、LGB等)。
stacking结合策略, 不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,即将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
3.2 AdaBoost算法原理
3.2.1 简要
Boosting系列算法中,Adaboost是最著名的算法之一。主要思想是:1)提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值;2)加大分类误差率小的弱分类器的权值,使其在表决起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
Adaboost是前向分布算法的一个特例
Adaboost中会涉及四个主要问题,即:计算学习误差率e,计算弱学习器的权重系数\(\alpha\),更新样本权重和结合策略
3.2.2 算法流程
Adaboost二元分类问题算法流程
输入样本集\(T=\{(x_1,y_1), (x_2,y_2), ...,(x_m,y_m)\}\),输出为\(\{-1,+1\}\),弱分类器算法,弱分类器迭代次数K
输出为最终的强分类器\(f(x)\)
- 初始化样本采集权重为:
\(D(1)=(w_{11},w_{12},...,w_{1m}), w_{1i}=\frac{1}{m}, i=1,2,...,m\)
- 对于\(k=1,2,...,K\):
a) 使用具有权重\(D_k\)的样本集来训练数据,得到弱分类器\(G_k(x)\)
b) 计算\(G_k(x)\)的分类误差率:
\(e_k=P(G_k(x)\neq y)=\sum_{i=1}^mw_{ki}I(G_k(x_i)\neq y_i)\)
c) 计算弱分类器的系数:
\(\alpha = \frac{1}{2}\log \frac{1-e_k}{e_k}\)
d) 更新样本权重分布(误分类样本权重增大):
\(w_{k+1,i}=\frac{w_{ki}}{Z_k}exp(-\alpha_ky_iG_k(x_i))\),这里\(Z_k\)是规范化因子,即:
\(Z_k = \sum_{i=1}^m w_{ki}exp(-\alpha_ky_iG_k(x_i))\)
- 构建最终分类器:
\(f(x) = sign(\sum_{k=1}^K \alpha_k G_k(x))\)
注:对于多元分类器,其他原理类似,只是在计算弱分类器系数的时候有区别:\(\alpha_k = \frac{1}{2} \log\frac{1-e_k}{e_k} + \log(R-1)\)
Adaboost回归问题
输入输出同分类算法
样本初始化(同分类算法)
对于k=1,2,...,K:
a) 使用具有权重\(D_k\)的样本集来训练数据,得到弱学习器\(G_k(x)\)
b) 计算\(G_k(x)\)的误差率:
计算训练集上的最大误差:
$E_k = max|diff(y_i, G_k(x_i)|, i =1,2,...,m $
计算每个样本的相对误差:\(e_{ki}=\frac{diff(y_i,G_k(x_i))}{E_k}\)
计算回归误差率:\(e_k = \sum_{i=1}^mw_{ki}e_{ki}\)
c) 计算弱学习器的权重:
\(\alpha_k = \frac{e_k}{1-e_k}\)
d) 更新样本权重分布:
\(w_{k+1,i}=\frac{w_{ki}}{Z}\alpha_k^{1-e_{ki}}\)这里\(Z=\sum_{i=1}^mw_{ki}\alpha_k^{1-e_{ki}}\)
- 构建最终强学习器\(f(x)=G_{k^*}(x)\)
其中\(G_{k^*}(x)\)是所有\(ln \frac{1}{a_k},k=1,2,...,K\)的中位数值对应序号\(k^*\)对应的弱学习器(原论文内容,无理论解释)
3.2.3 Adaboost算法的损失函数和正则化
损失函数:
Adaboost第k-1轮的强学习器为:\(f_{k-1}(x)=\sum_{i=1}^{k-1}\alpha_iG_i(x)\)
第k轮的强学习器为:\(f_{k}(x)=\sum_{i=1}^{k}\alpha_iG_i(x)\)
从而可得:\(f_k(x)=f_{k-1}(x)+\alpha_kG_k(x)\)
Adaboost的损失函数为指数函数,即\(L(y,f(x))=\sum_{i=1}^mexp(-y_if_k(x_i))\)
损失函数优化:\(argmin\ f(y,f(x))=\underset{a,G}{argmin}\sum_{i=1}^mexp(-y_if_k(x))\underset{a,G}\sum_{i=1}^m\Big[exp(-y_i(f_{k-1}(x)+aG(x))\Big]\)
我们令\(w_{ki}=exp(-y_if_{k-1}(x))\),则\((a_k,G_k(x))=\underset{a,G}{argmin}\sum_{i=1}^m w_{ki}exp[-y_iaG(x)]\)
首先求\(G_k(x)\),得到
\(\sum_{i=1}^m w_{ki}exp[-y_iaG(x)]=\underset{y_i=G_k(x_i)}\sum w_{ki}e^{-a}+\underset{y_i\neq G_k(x_i)}\sum w_{ki}e^a \\=(e^a-e^{-a})\sum_{i=1}^mw_{ki}I(y_i\neq G_k(x_i)+e^{-a}\sum_{i=1}^mw_{ki} (2)\)
由于上式中\(w_{ki}\)是上一步迭代得到的固定值,且直大于0;又因为\(a>0\)所以\((e^a-e^{-a})>0\)从而便可以得到上式相加的两项可以单独求解,即
\(G_k(x)=\underset G{argmin}\sum_{i=1}^mw_{ki}I(y_i\neq G(x_i))\)
公式(2)中,\(G_k(x)\)为已知值,并对\(a\)求导,令导数等于0,可得:
\(a_k=\frac{1}{2}\log \frac{1-e_k}{e_k}\),其中\(e_k\)为分类误差率,即\(e_k=\frac{\underset{i=1}{\overset m \sum }w_{ki}I(y_i\neq G(x_i)}{\underset{i=1}{\overset m \sum }w_{ki}}=\underset{i=1}{\overset m \sum }w_{ki}I(y_i\neq G(x_i))\)
最后利用权重的更新公式\(f_k(x)=f_{k-1}(x)+\alpha_kG_k(x)\)和\(w_{ki}=exp(-y_if_{k-1}(x))\)便可以得到
\(w_{k+1,i}=w_{ki}exp[-y_ia_kf_{k-1}(x)]\)
正则化:
加入正则化前的学习函数\(f_k(x)=f_{k-1}(x)+\alpha_kG_k(x)\)
加入正则化后\(f_k(x)=f_{k-1}(x)+\lambda \alpha_kG_k(x)\),其中\(\lambda\)是正则化系数
3.2.4 Adaboost算法的优劣
Adaboost的主要优点有:
1)Adaboost作为分类器时,分类精度很高
2)在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
3)作为简单的二元分类器时,构造简单,结果可理解。
4)不容易发生过拟合
Adaboost的主要缺点有:
1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
3.2.5 AdaBoost训练误差分析
后续再补充
3.3 GBDT(梯度提升决策树)
GBDT可以简称为GBT、GTB、GBRT(Gradient Boosting Regression Tree)、MART(Multiple Additive Regression Tree)等。是一种Boosting方法,使用前向分布算法,弱学习器限定了只能使用CART回归树做模型。GBDT是对前一步学习器的损失进行拟合,即
\(argmin \ L(y,f_t(x)) = argmin \ L(y, f_{t-1}(x)+ h_t(x))\)
损失函数各种各样,如何找到一种通用的拟合方法?
如果是用真实值减预测值得到残差,那么这个残差就是一部到位了,GBDT期望的是一点点的去模拟残差,得到多个决策树。有点像梯度下降,我们希望沿着梯度的方向一步步的走,而不是一次走完。
3.3.1 GBDT的负梯度拟合
Frieidman提出了用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树,第t轮的第i个样本的损失函数的负梯度表示为:
\(r_{ti}=\Big[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\Big]_{f(x)=f_{t-1}(x)}\)
注意:不是拟合残差,而是拟合负梯度。①至于为什么拟合负梯度可以得到一个好的模型呢?因为沿着负梯度的方向学习,效率是最高的,当负梯度为0时,全局损失函数就是最好的,得到的强学习器F(x)自然也是比较好的。②为什么每个弱学习器的组合方式是相加呢?因为梯度下降或者说泰勒展开式的形式就是加法。
如果是用真实值减预测值得到残差,那么这个残差就是一部到位了,GBDT期望的是一点点的去模拟残差,得到多个决策树。有点像梯度下降,我们希望沿着梯度的方向一步步的走,而不是一次走完。
利用\((x_i,r_{ti}),i=1,2,...,m\),我们可以拟合一颗CART回归树,得到第t颗回归树,其对应的叶节点区域\(R_{t,j},j=1,2,...,J\),其中\(J\)为叶子节点的个数。
针对每一个叶子节点力的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的输出值\(c_{tj}\)如下:
\(c_{tj}=\underset c {argmin} \underset{x_i \in R_{tj}}\sum L(y_i, f_{t-1}(x_i)+c)\)(c值是用于拟合\(r_{ti}\)的)
这样我们就得到了本轮的决策树拟合函数:
\(h_t(x) = \sum_{j=1}^Jc_{tj}I(x \in R_{tj})\)
从而本轮最终得到的强学习器表达如下:
\(f_t(x)=f_{t-1}(x)+\sum_{j=1}^Jc_{gj}I(x \in R_{tj})\)
通过损失函数的负梯度拟合,我们找到了一种通用的拟合损失误差的方法。
3.3.2 GBDT回归算法
由于在回归算法中,大部分使用的是均方误差损失,而均方误差求负梯度,就等于是残差
输入训练样本\(T=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}\),最大迭代次数T,损失函数L;输出是强学习器\(f(x)\)
1)初始化弱学习器
\(f_0(x)=\underset c{argmin} \sum_{i=1}^mL(y_i,c)\)
2)对迭代轮数\(t=1,2,...T\)有:
a.对样本\(i=1,2,...,m\),计算负梯度
\(r_{ti}=\Big[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\Big]_{f(x)=f_{t-1}(x)}\)
b.利用\((x_i,r_{ti}),i=1,2,...,m\),我们可以拟合一颗CART回归树,得到第t颗回归树,其对应的叶节点区域\(R_{t,j},j=1,2,...,J\),其中\(J\)为叶子节点的个数。
c.对叶子区域\(j=1,2,...,J\),计算最佳拟合值
\(c_{tj}=\underset c {argmin} \underset{x_i \in R_{tj}}\sum L(y_i, f_{t-1}(x_i)+c)\)(c值是用于拟合\(r_{ti}\)的)
d.更新强学习器
\(f_t(x)=f_{t-1}(x)+\sum_{j=1}^Jc_{gj}I(x \in R_{tj})\)
3)得到强学习器\(f(x)\)的表达式
\(f(x)=f_T(x)=f_0(x)+\sum_{t=1}^T\sum_{j=1}^Jc_{tj}I(x \in R_{tj})\)
3.3.3 GBDT分类算法
GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。本文仅讨论用对数似然损失函数的GBDT分类。而对于对数似然损失函数,我们又有二元分类和多元分类的区别。
对于二元GBDT,如果对数似然损失函数,则损失函数可以表示为:
\(L(y,f(x)) = \log(1+exp(-yf(x))), y\in\{-1,+1\}\)
此时的负梯度误差为:\(r_{ti}=\Big[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\Big]_{f(x)=f_{t-1}(x)}=y_i/(1+exp(y_if(x_i)))\)
对于生成的决策树,各个叶子节点的最佳负梯度拟合值为
\(c_{tj}=\underset c {argmin} \underset{x_i \in R_{tj}}\sum \log(1+exp(-y_i(f_{t-1}(x_i)+c))\)
由于上式比较难优化,一般使用近似值代替
\(c_{tj}=\underset{x_i \in R_{tj}} \sum r_{ti}/ \underset{x_i \in R_{tj}} \sum |r_{ti}|(1-|r_ti|)\)
对于多元GBDT,设有K个类别,则损失函数可以记为:
\(L(y,f(x))=\sum_{k=1}^Ky_k\log p_k(x)\)(此处只有当样本输出类别为k时\(y_k=1\))
第k类的概率\(p_k(x)\)的表达式为:
\(p_k(x)=exp(f_k(x))/\sum_{l=1}^K exp(f_l(x))\)
集合上面两个式子,可以计算出第t轮的第i个样本对应类别\(l\)的负梯度误误差为
\(r_{til}=\Big[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\Big]_{f(x)=f_{l,t-1}(x)}=y_{il} - p_{l,t-1}(x_i)\)
这里的误差就是样本i对应类别\(l\)的真实概率和\(t-1\)轮预测概率的差值。
对于生成的决策树,各个叶子节点的最佳负梯度拟合值为:
\(c_{tjl}=\underset{cjk}{argmin}\sum_{i=0}^m\sum_{k=1}^KL(y_k,f_{t-1,l}(x)+\sum_{j=0}^Jc_{jl}I(x_i \in R_{tjl}))\)
上式比较难优化,一般用近似值代替\(c_{tjl}=\frac{K-1}{K}\frac{\underset{x_i \in R_{tjl}}\sum r_{til}}{\underset{x_i \in R_{til}}\sum |r_{til}|(1-|r_{til}|)}\)
3.3.4 GBDT常用损失函数和正则化
分类算法损失函数:
指数损失:\(L(y,f(x))=exp(-yf(x))\),此时的梯度为\(G_k(x)=\underset G{argmin}\sum_{i=1}^mw_{ki}I(y_i\neq G(x_i))\)
对数损失二分类: \(L(y,f(x)) = \log(1+exp(-yf(x))), y\in\{-1,+1\}\)
对数损失多分类:\(L(y,f(x))=\sum_{k=1}^Ky_k\log p_k(x)\)
回归算法损失函数:
均方误差:\(L(y,f(x))=(y-f(x))^2\)
绝对损失:\(L(y,f(x))=|y-f(x)|\),此时负梯度差为 \(sign(y_i-f(x_i))\)
Huber损失:是均方差和绝对损失的折中产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差,即
此时对应的负梯度为:
分位数回归损失:\(L(y,f(x))=\underset{y \geq f(x)}\sum\theta|y-f(x)|+\underset{y < f(x)}\sum(1-\theta)|y-f(x)|\)
对应的负梯度为\(r(y_i,f(x_i))=\begin{cases} \theta & y_i \geq f(x_i) \\1-\theta & y_i < f(x_i) \end{cases}\)
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
GBDT的正则化
- 加步长限制
\(f_k(x)=f_{k-1}(x)+h_k(x) \overset{\text{正则化项}\lambda} \rightarrow \ f_k(x)=f_{k-1}(x)+\lambda h_k(x)\)
- 控制采样比例(在不同采样的样本中构建数,可以使用并行的方法)
这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
- 对CART回归树进行正则化剪枝。
3.3.6 GBDT优缺点
GBDT主要的优点有:
-
可以灵活处理各种类型的数据,包括连续值和离散值。在分布稠密的数据集上范化能力和表达能力都很好;
-
在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。采用决策树作为弱分类器使得 GBDT 模型具有较好的解程性和鲁棒性,能够自动发现特征之间的高阶关系,并且也不需要对数据进行特殊的预处理如归一化等 。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
4)在预测阶段的计算速度快,树与树之间可并行化计算
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
2)在高维稀疏的数据集上表现不如支持向量机或神经网络不如它在处理数值恃征时明显 。
3)在处理文本分类特征问题上,相对真他模型的优势不
3.4 Bagging和随机森林
3.4.1 简要
Bagging的弱学习器之间没有串行的联系,它的特点是随机采样,即bootstrap。每次只取一个样本,并将其放回后进行下一次采样。构建T颗树,每棵树需要采集m个样本,则在某一次随机采样中,每个样本被选中的概率为\(1/m\),不被选中的概率是\(1-1/m\);则m次采样均未被选中的概率为\(\underset{m \rightarrow \infty}{lim}(1-1/m)^m \rightarrow 1/e \approx 0.368\)。也就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。对于这部分大约36.8%的没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, 简称OOB)。这里的m与原训练数据的样本数是相等的。
bagging的集合策略也比较简单,对于分类问题,通常使用简单投票法;对于回归问题,通常使用简单平均法。
3.4.2 Bagging和随机森林算法
Bagging算法步骤
输入训练样本\(T=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}\),最大迭代次数T,损失函数L;输出是强学习器\(f(x)\)
1)对于t=1,2,...,T:
a. 对训练集进行第t次随机采样,共采集m次,得到包含m个样本的采集\(D_t\)
b. 用采样集\(D_t\)训练第t个弱学习器\(G_t(x)\)
2)如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
随机森林改进点
1)随机森林使用CART决策树作为弱学习器
2)在构建每个决策树的时候,随机选择\(n_{sub}\)个特征,其中\(n_{sub}\leq n\)
\(n_{sub}\)越小,则模型越健壮,但是对训练集的拟合程度会越差;集模型方差减小,偏差增大。在实际应用中,一般通过交叉验证调参获取一个合适的\(n_{sub}\)值
每棵树尽可能最大程度的生长,没有剪枝过程(由于上一步随机采样的原因,保证了随机性,所以就算不剪枝也不会出现overfitting;因为没课树都是很弱的)
3.4.3 随机森林的推广
随机森林不光可以用于分类回归,还可以用于特征转换,异常点检测等。
extra trees
原理和随机森林一样,仅有区别有:
1)不再随机采样,而是使用所有训练样本
2)决策树划分叶节点的时候,不再使用最优划分,而是随机选择特征值的划分点。
第二点改进会导致单个决策树的性能变差,增大随机森林的偏差,减少方差;在某些时候extra trees的泛化能力比随机森林更好
Tatally Random Trees Embedding
非监督学习的数据转化方法,将低维的数据集映射到高维,从而让映射到高维的数据更好的运用于分类回归模型。TRTE的数据转化方法类似于GBDT+LR中GBDT的转化方式
Isolation Forest
异常点检测方法,其中与RF不同的是:采样个数不用等于样本数,而是只要采集很少的样本就可以了(因为我们的目的是异常点检测,只需要部分的样本一般就可以将异常点区别出来了)。
1)对于每一个决策树的建立, IForest采用随机选择一个划分特征,对划分特征随机选择一个划分阈值。
2)IForest一般会选择一个比较小的最大决策树深度max_depth,原因同样本采集,用少量的异常点检测一般不需要这么大规模的决策树。
3)对于异常点的判断,则是将测试样本点\(x\)拟合到T颗决策树。计算在每颗决策树上该样本的叶子节点的深度\(ℎ_𝑡(𝑥)\)。,从而可以计算出平均高度\(h(x)\)。此时我们用下面的公式计算样本点\(x\)的异常概率:
\(s(x,m)=2^{-\frac{h(x)}{c(m)}}\);其中m为样本个数,\(h(x)\)高度越高,说明越难分,与其他点的相似度越高
\(c(m)=2\ ln(m-1) + \xi - 2 \frac{m-1}{m}\),其中\(\xi\)为欧拉常数
\(s(x,m)\)的取值范围是\([0,1]\),取值越接近1,则是异常点的概率也越大。
3.4.4 随机森林优缺点
RF的主要优点有:
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。个人觉得这是的最主要的优点。
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3) 在训练后,可以给出各个特征对于输出的重要性
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
5) 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
6) 对部分特征缺失不敏感。
RF的主要缺点有:(主要都是CART决策树的缺点)
1)在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
3.4.5 随机森林特征重要度
每个特征在随机森林中的每颗树上做了多大的贡献,取平均值,然后比较特征之间的贡献大小。常见的计算方法有两种,一种是平均不纯度的减少,常用基尼系数测量;另一种是平均准确率的减少,常用袋外误差率去衡量。
平均不纯度的减少:计算每个特征在随机森林所有决策树中节点分裂不纯度的平均该变量
平均准确率的减少:对每个特征加躁,看对结果的准确率的影响。影响小说明这个特征不重要,反之重要
1、对于随机森林中的每一颗决策树,使用相应的OOB(袋外数据)数据来计算它的袋外数据误差,记为errOOB1.
2、随机地对袋外数据OOB所有样本的特征X加入噪声干扰(即随机的改变样本在特征X处的值),再次计算它的袋外数据误差,记为errOOB2.
3、假设随机森林中有N棵树,那么对于特征X的重要性\(=∑(errOOB2-errOOB1)/N\),之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
3.5 XGBoost算法
3.5.1 GBDT和XGBoost的区别
XGBoost的优点,主要从下面三个方面做了优化:
1)算法本身的优化:
支持很多其他的弱分类器,如线性分类器,而传统GBDT以CART作为基分类器
损失函数加入正则化(包括叶子节点个数和也节点输出值),用于控制模型的复杂度
优化方式上,xgboost损失函数对误差部分进行了二阶泰勒展开,而GBDT损失函数只对误差部分做负梯度(一阶泰勒)展开
2)算法运行效率的优化:
决策树建立过程并行选择:支持列抽样,从而可以并行构建决策树;
在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度;
构建特征的直方图,高效的生成候选分割点。
3)算法健壮性的优化:
对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式
算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。
学习率:进行完一次迭代后,将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间
XGBoost的缺点:
节点分类需要遍历数据集:虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
预排序空间复杂度高:预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
找到特别精确的分割点,可能存在过拟合。
3.5.2 XGBoost算法原理
GBDT的决策树更新过程
1)对样本\(i=1,2,...,m\),计算负梯度\(r_{ti}=\Big[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\Big]_{f(x)=f_{t-1}(x)}\)
2)利用\((x_i,r_{ti}),i=1,2,...,m\),我们可以拟合一颗CART回归树,得到第t颗回归树,其对应的叶节点区域\(R_{t,j},j=1,2,...,J\),其中\(J\)为叶子节点的个数。
3)对叶子区域\(j=1,2,...,J\),计算最佳拟合值\(c_{tj}=\underset c {argmin} \underset{x_i \in R_{tj}}\sum L(y_i, f_{t-1}(x_i)+c)\)
4)更新强学习器 \(f_t(x)=f_{t-1}(x)+\sum_{j=1}^Jc_{gj}I(x \in R_{tj})\)
上面的第一步是计算负梯度(泰勒展开式的一阶导数),第二步是第一步的优化求解,即基于残差拟合一颗CART回归树,得到\(J\)个叶子节点;第三步是第二个优化求解,在第二步优化求解的基础上,对每个优化求解的结果上,对每个节点区域再做一次线性搜索,得到每个叶子节点区域的最优取值。最终得到当前轮的强学习器。第二步和第三步需要求解当前决策树最优的所有\(J\)个叶子节点区域的每个叶子区域的最优解。GBDT采样的方法是分两步走,先求出最优的所有\(J\)个叶子节点区域,再求出每个叶子节点区域的最优解。
XGBoost改进点
损失函数加入正则项\(\Omega(h_t)=\gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum}w_{tj}^2\),\(w_{tj}\)是第j个叶子节点的最优值,此时损失函数可表达为:
\(L_t=\underset{i=1}{\overset m \sum}L(y_i,f_{t-1}(x_i)+h_t(x_i))+\gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2\)
我们最终要极小化上面这个损失函数,得到第t颗决策树最优的\(J\)个叶子节点区域和每个叶子节点区域的最优解\(w_{tj}\)。XGBoost没有和GBDt一样去拟合泰勒展开式的一阶导数,而是期望直接基于损失函数的二阶泰勒展开式来求解,损失函数的二阶泰勒展开式为:
\(L_t=\underset{i=1}{\overset m \sum}L(y_i,f_{t-1}(x_i)+h_t(x_i))+\gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2 \\ \approx \underset{i=1}{\overset m \sum}\Big[L(y_i,f_{t-1}(x_i))+\frac{\partial L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)}h_t(x_i)+\frac{1}{2}\frac{\partial^2 L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}^2(x_i)}h_t^2(x_i)\Big] + \gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2\\= \underset{i=1}{\overset m \sum}\Big[L(y_i,f_{t-1}(x_i))+g_{ti}h_t(x_i)+\frac{1}{2}h_{ti}h_t^2(x_i)\Big] + \gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2\)
其中第i个样本再第t个弱学习器的一阶和二阶导数分别记为:
\(g_{ti}= \frac{\partial L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)}\)和\(h_{ti}=\frac{\partial^2 L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}^2(x_i)}\)
其中,\(L(y_i,f_{t-1}(x_i))\)是常数,对最小化无影响,可以去掉
\(L_t \approx \underset{i=1}{\overset m \sum}\Big[g_{ti}h_t(x_i)+\frac{1}{2}h_{ti}h_t^2(x_i)\Big] + \gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2 \\=\underset{j=1}{\overset J \sum}\Big[\underset{x_i \in R_{tj}}\sum g_{ti}w_{tj}+\frac{1}{2}\underset{x_i \in R_{tj}}\sum h_{ti}w_{tj}^2\Big] + \gamma J + \frac{\lambda}{2}\underset{j=1}{\overset J \sum} w_{tj}^2 \\=\underset{j=1}{\overset J \sum}\Big[\big(\underset{x_i \in R_{tj}}\sum g_{ti}\big)w_{tj}+\frac{1}{2}\big(\underset{x_i \in R_{tj}}\sum h_{ti} + \lambda\big)w_{tj}^2\Big] + \gamma J \\=\underset{j=1}{\overset J \sum}\Big[G_{tj}w_{tj}+\frac{1}{2}\big(H_{tj} + \lambda\big)w_{tj}^2\Big] + \gamma J\)
其中,\(G_{tj}=(\underset{x_i \in R_{tj}}\sum g_{ti})\),\(H_{tj}=(\underset{x_i \in R_{tj}}\sum h_{ti})\)
3.5.3 XGBoost损失函数的优化求解
如何求解出决策树最优的所有\(J\)个叶子节点区域和每个叶子节点区域的最优解\(w_{tj}\),可分解成两个问题:
1)如果已经求出了第t个决策树的\(J\)个最优的叶子节点区域,如何求出每个叶子节点区域的最优解\(w_{tj}\)
2)对当前决策树做子树分裂决策时,应该如何选择哪个特征和特征值进行分裂,使最终我们的损失函数\(L_t\)最小
对于第一个问题,只要对损失函数\(w_{tj}\)求导并令导数为0即可,此时得到叶子节点区域的最优解为:
\(w_{tj}=-\frac{G_{tj}}{H_{tj}+\lambda}\)
说明GBDT叶节点求解,GBDT在求解过程中实际上也已经考虑了二阶梯度:
二元分类的损失函数是:\(L(y,f(x))=\log(1+exp(-yf(x)))\)
其每个样本的一阶导数为:\(g_i=-r_i=-y_i/(1+exp(y_if(x_i)))\)
其每个二阶导数为:\(h_i=\frac{y_i^2exp(y_if(x_i))}{(1+exp(y_if(x_i)))}=\frac{exp(y_if(x_i))}{(1+exp(y_if(x_i)))}=|g_i|(1-|g_i|)\),其中\(y_i^2=1\)
由于不存在正则化项,所以\(c_{tj}=-\frac{g_i}{h_i}=\underset{x_i \in R_{tj}} \sum r_{ti}/ \underset{x_i \in R_{tj}} \sum |r_{ti}|(1-|r_ti|)\)
第二个问题,在GBDT里面,我们是直接拟合CART回归树,所以树节点分裂使用的是均方误差。XGBoost,这里不使用均方误差,而是使用贪心法,即每次分裂都期望最小化我们的损失函数的误差。
注意当\(w_{tj}\)取最优解的时候,原损失函数的表达式为:\(L_t==-\frac{1}{2}\underset{j=1}{\overset{J}\sum}{\frac{G_{tj}^2}{H_{tj}+\lambda}} + \gamma J\)
如果我们每次做左右子树分裂时,可以最大程度的减少损失函数的损失就最好了。也就是说,假设当前节点左右子树的一阶二阶导数和为\(G_L,H_L,G_R,H_R\),则我们期望最大化下式:
\(-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}+\gamma J-(-\frac{1}{2}\frac{G_L^2}{H_L+\lambda}-\frac{1}{2}\frac{G_R^2}{H_R+\lambda}+\gamma (J+1))\),整理如下:
\(max \ \frac{1}{2}\frac{G_L^2}{H_L+\lambda}+\frac{1}{2}\frac{G_R^2}{H_R+\lambda}-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}-\gamma\)
也就是说决策树分类标准不再是CART回归树的均方误差,而是上面的式子
3.5.4 算法流程
输入训练样本\(T=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}\),最大迭代次数T,损失函数L;正则化系数\(\lambda, \gamma\),输出是强学习器\(f(x)\)
对于t=1,2,...,T:
1)计算第i个样本在当前轮损失函数L基于\(f_{t-1}(x_i)\)的一阶导数\(g_{ti}\),二阶导数\(h_{ti}\),计算所有样本的一阶和二阶导数\(G_{t}=\underset{i=1}{\overset{m} \sum} g_{ti}\),\(H_{t}=\underset{i=1}{\overset{m} \sum} h_{ti}\)
2)基于当前及诶单尝试分裂决策树,默认分数score=0,G和H为当前需要分裂的节点的一阶和二阶导数之和,对特征序号\(k=1,2,...,K\)
a) \(G_L=0,H_L=0\)
b) 将样本按特征k从小到大排序,依次取出第i个样本,依次计算当前样本放入左子树后,左右子树一阶和二阶导数和
\(G_L=G_L+g_{ti}, G_R=G-G_L; \ \ \ \ \ H_L=H_L+H_{ti},H_R=H-H_L\)
c) 尝试更新最大的分数 \(score=max\Big[score, \frac{1}{2}\frac{G_L^2}{H_L+\lambda}+\frac{1}{2}\frac{G_R^2}{H_R+\lambda}-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}-\gamma\Big]\)
3)基于最大score对应的划分特征和特征值分裂子树
4)如果最大score为0,则当前决策树建立完毕,计算所有叶子区域的\(w_{tj}\),得到弱学习器\(h_t(x)\),更新强学习器\(f_t(x)\),进入下一轮弱学习器迭代.如果最大score不是0,则转到第2)步继续尝试分裂决策树。
3.5.5 运行效率和算法健壮性的优化
运行效率的优化
单个弱学习器里最耗时的是决策树的分裂过程,XGBoost针对这个分裂做了比较大的并行优化。对于不同的特征的特征划分点,XGBoost分别在不同的线程中并行选择分裂的最大增益。
同时,对训练的每个特征排序并且以块的结构存储在内存中,方便后面迭代重复使用,减少计算量。计算量的减少参见上面第4节的算法流程,首先默认所有的样本都在右子树,然后从小到大迭代,依次放入左子树,并寻找最优的分裂点。这样做可以减少很多不必要的比较。
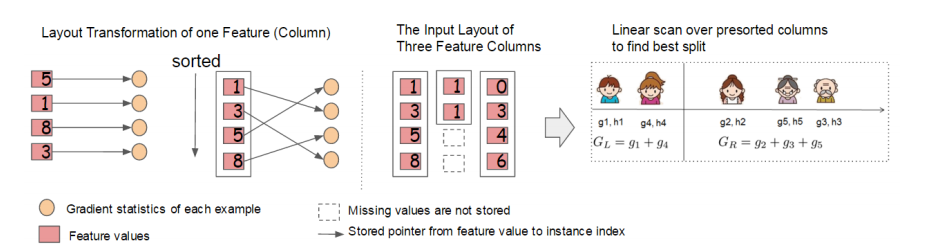
通过设置合理的粉快大小,充分利用了CPU缓存进行读取加速。使得数据读取的速度更快。另外,通过将分块进行压缩(block compressoin)并存储到硬盘上,并且通过将分块分区到多个硬盘上实现了更大的IO。
算法健壮性的优化
XGBoost没有假设缺失值一定进入左子树还是右子树,则是尝试通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向,这样处理起来更加的灵活和合理。第一次假设特征k所有有缺失值的样本都走左子树,第二次假设特征k所有缺失值的样本都走右子树。然后每次都是针对没有缺失值的特征k的样本走上述流程,而不是所有的的样本。
如果是所有的缺失值走右子树,使用上面第4节的a),b)和c即可。如果是所有的样本走左子树,则上面第4节的a)步要变成:\(G_R=0,H_R=0\)
b) 更新为:\(G_R=G_R+g_{ti}, G_L=G-G_R; \ \ \ \ \ H_R=H_R+H_{ti},H_L=H-H_R\)
3.6 LightGBM(轻量级的高效梯度提升树)
3.61 带深度限制的Leaf-wise算法
决策树学习的两种方法:leaf-wise和level-wise;leaf-wise不断寻找分裂后收益最大的叶子节点,将起分裂成两个节点,从而生长决策树(生长过程是顺序的,不方便加速);level-wise按层生长,不需要每次去挑选节点,在每一个level中各个节点的分裂可以并行完成(但是会产生很多没有必要的分裂,有更多的计算代价)。
XGBoost 采用 Level-wise 的增长策略,方便并行计算每一层的分裂节点,提高了训练速度,但同时也因为节点增益过小增加了很多不必要的分裂,降低了计算量。
LightGBM 采用 Leaf-wise 的增长策略减少了计算量,配合最大深度的限制防止过拟合,由于每次都需要计算增益最大的节点,所以无法并行分裂。
3.6.2 直方图算法加速
xgboost采用预排序的方法,计算过程中则是按照feature value的排序,逐个数据样本计算当前feature value的分裂收益。这样能够精确找到最佳分裂点。
lightGBM采用直方图算法,将连续的特征离散化为 k 个离散特征,同时构造一个宽度为 k 的直方图用于统计信息(含有 k 个 bin)。利用直方图算法我们无需遍历数据,只需要遍历 k 个 bin 即可找到最佳分裂点。
使用直方图的好处:
1)降低内存的使用。Xgboost按照feature value对数据排序,用32位整型去存储排序后的索引值,32位整型去存储特征值,而lightgbm只需要8位去存储分桶后的bin value,内存下降了1/8.
2)降低计算代价。计算特征分裂增益时,XGBoost 需要遍历一次数据找到最佳分裂点,而 LightGBM 只需要遍历一次 k 次,直接将时间复杂度从 $O(data * feature) $降低到 \(O(k * feature)\) ,而我们知道 \(data >> k\) 。
直方图差的加速
在构建叶节点的直方图时,还可以通过父节点的直方图与相邻叶节点的直方图相减的方式构建,从而减少一半的计算量。在实际操作过程中,可以先计算直方图小的叶子节点,然后利用直方图做差来获取直方图大的叶子节点,可以达到2倍加速的效果。

3.6.3 支持并行
特征并行
传统的特征并行算法在于对数据进行垂直划分,然后使用不同机器找到不同特征的最优分裂点,基于通信整合得到最佳划分点,然后基于通信告知其他机器划分结果。传统的特征并行方法有个很大的缺点:需要告知每台机器最终划分结果,增加了额外的复杂度(因为对数据进行垂直划分,每台机器所含数据不同,划分结果需要通过通信告知)。
LightGBM 则不进行数据垂直划分,每台机器都有训练集完整数据,在得到最佳划分方案后可在本地执行划分而减少了不必要的通信。
数据并行
传统的数据并行策略主要为水平划分数据,然后本地构建直方图并整合成全局直方图,最后在全局直方图中找出最佳划分点。
这种数据划分有一个很大的缺点:通讯开销过大。如果使用点对点通信,一台机器的通讯开销大约为 O(#machine * #feature *#bin ) ;如果使用集成的通信,则通讯开销为 O(2 * #feature *#bin ) 。
LightGBM 采用分散规约(Reduce scatter)的方式将直方图整合的任务分摊到不同机器上,从而降低通信代价,并通过直方图做差进一步降低不同机器间的通信。
投票并行
针对数据量特别大特征也特别多的情况下,可以采用投票并行。投票并行主要针对数据并行时数据合并的通信代价比较大的瓶颈进行优化,其通过投票的方式只合并部分特征的直方图从而达到降低通信量的目的。大致步骤为两步:
- 本地找出 Top K 特征,并基于投票筛选出可能是最优分割点的特征;
- 合并时只合并每个机器选出来的特征。
3.6.4 其他改进
提升cache命中率
xgboost对cache优化不够好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
基于直方图的算法简单的提高cache命中率。
所有的feature采用相同方法访问梯度(区别于不同特征通过不同的索引获得梯度),只需要对梯度进行一次重新排序,所有特征能够连续地访问梯度。不需要使用行索引到叶子索引的数组。
数据量很大的时候,相对于随机访问,顺序访问能够提升速度4倍以上。这个速度的差异基本上是由cache miss所带来的。
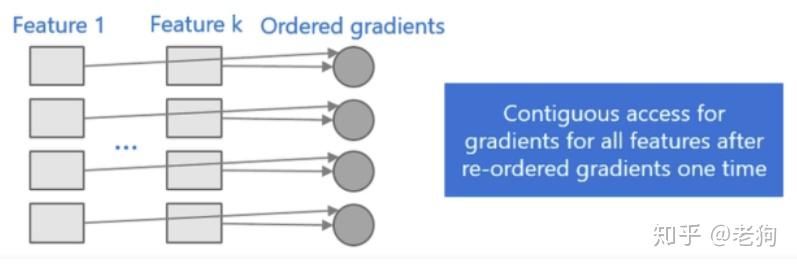
直接支持类别特征作为输入
经过实验,直接使用类别特征比one-hot特征速度快8倍以上。
3.6.5 XGBoost和LightGBM的调参
XGBoost的主要参数:
max_depth:树的最大深度,用来避免过拟合,默认为0
min_child_weight:最小的叶子节点样本权重和,如果节点分裂造成一个叶子节点的样本权重和小于该值,则放弃分裂。
gamma:公式中叶子节点个数的参数,也就是分类后损失函数的增益,增益大于这个阈值,才会对节点进行分裂。
subsample:训练样本随机采样的比例
colsample_bytree, colsample_bylevel, colsample_bynode: 列采样的参数设置。bytree表示在构建每棵树的时候使用。bylevel表示构建每层节点的时候使用,bynode在每次分裂的时候使用。
eta:shinkage,类似学习率,防止过拟合,默认0.3
num_round:迭代次数
scale_pos_weight: 控制正负样本的平衡,用于不平衡数据。
max_delta_step 该参数限制每棵树权重改变的最大步长。一般用不到,但是在数据样本极度不平衡时,可能对逻辑回归有帮助。
lambda: L2正则化项。默认为1.
alpha:L1的正则化项.
objective:定义损失函数。常用值有binary:logistic; multi:softmax; multi:softprob
booster: 每次迭代的模型选择,gbtree或者gbliner
nthread:并行的线程数,默认使用最大的核数
XGBoost的主要参数:
application:regression\binary\multiclass
Boosting:gbdt、rf、dart(带dropout的gbdt)、goss(基于梯度的单边采样的gbdt)
num_iteration:迭代次数,通常100+
learning_rate:学习率
num_leaves:一棵树上的叶子树,默认31;使用较大的num_leaves可提升拟合能力,但太大会过拟合
num_threads:线程数,一般设置为cpu内核数
device:指定计算设备(cpu or gpu)
metric:评估指标(mae、mse、binary logloss、multi logloss)
maxdepth:数的最大深度,默认-1,小于0表示没有限制(限制深度可避免过拟合)
min_data_in_leaf:叶子上包含的最小样本数量,默认为20(设置较大值可避免过拟合)
min_sum_hessian_in_leaf:一个叶子节点上最小hessian之和,默认1e-3
bagging_fraction:数据抽样
bagging_freq:bagging的频率,表示没bagging_freq次执行bagging
feature_fraction:特征抽样
early_stopping_round:**步无提升则提前停止迭代
Lambda_l1, lambda_l2:正则化系数,默认为0
min_gain_to_split:分裂时最小增益
dropout_rate:dorpout的概率
max_cat_threshold:表示category特征的取值集合的最大大小,默认为32
max_bin:使用较小的max_bin可以加快训练速度,但是可能会引起过拟合,影响算法效果
save_binary:将数据保存为二进制文件,来加速数据读取
parallel learning:
categorical_feature:categorical_feature=0,1,2表示第0,1,2,列作为category特征
Ignore_colum:Ignore_colum=0,1,2 表示将忽略0,1,2列
3.7 Stacking
stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。
代码地址:https://github.com/log0/vertebral/blob/master/stacked_generalization.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号