


前言:
这个系列一共有8个部分。主要参考了github上的几个代码。
使用工具有torchtext,pytorch。
数据集主要是烂番茄电影评论数据集https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews。
实验相关:
数据集处理:
烂番茄电影评论数据集是包含了训练集和测试集,原始的句子已经通过斯坦福大学的解析器解析成为了很多短句,是数据集中的phrase ,另外提供了sentenceid可以寻找到原始的句子,情绪标签分为五个
0 - 消极
1 - 有些消极
2 - 中立
3 - 有点积极
4 - 积极
首先先观察数据
1 import pandas as pd 2 3 files1 = pd.read_csv("datasets/train.tsv",sep="\t") 4 files2 = pd.read_csv("datasets/test.tsv",sep="\t") 5 files1.head(5) 6 files2.head(5)
train_data test_data
test_data
利用torchtext构建数据集
import torchtext
from torchtext import data,datasets
train_data = data.TabularDataset(
path='./datasets/train.tsv',format='tsv',
skip_header=True,
fields = [('PhraseId', None),('SentenceId', None),('Phrase', TEXT),('Sentiment',LABEL)])
test_data = data.TabularDataset(
path='./datasets/test.tsv',format='tsv',
skip_header=True,
fields = [('PhraseId', None),('SentenceId', None),('Phrase', TEXT)])
import random
train_data, valid_data = train_data.split(random_state = random.seed(10))
构造词典和batch
from torchtext.vocab import GloVe from torchtext import data TEXT.build_vocab(train_data, vectors=GloVe(name='6B', dim=300)) LABEL.build_vocab()
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
构建模型:
使用最简单的RNN,如下
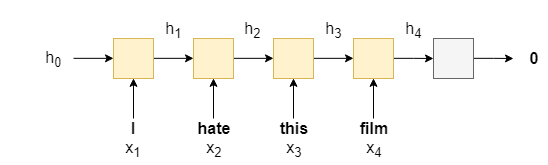
import torch.nn as nn class RNN(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim): super().__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.rnn = nn.RNN(embedding_dim, hidden_dim,frist_batch=True) self.fc = nn.Linear(hidden_dim, output_dim) def forward(self, text): embedded = self.embedding(text).permute(1,0,2)
output, hidden = self.rnn(embedded)
return self.fc(hidden)
import torch.optim as optim
import torch.nn.functional as F
model = RNN()
model.train()
optimizer = optim.Adam(model.parameters(), lr=0.01)
loss_funtion = F.cross_entropy
for epoch in range(2):
for batch in train_iterator:
optimizer.zero_grad()
predicted = model(batch.Phrase)
loss = loss_funtion(predicted, batch.Sentiment)
loss.backward()
optimizer.step()
不怎么会写,后面补充完。。。为啥别人的博客写的那么好!!!

