
2.7日结

这里的闭包指的是,当Executor在执行的过程中需要用到Driver内存里面的变量的话,就要求这个变量必须要先序列化,否则就会报错
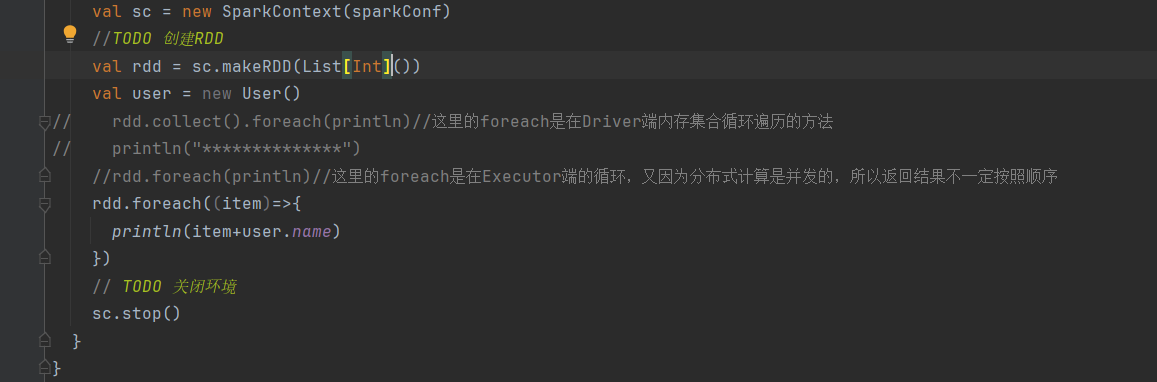
这里即使集合里面没有数据,也会报错,因为在执行foreach之前会有一次检测,如果发现有scala对象未序列化,就报错,也就不会触发foreach方法

另外这里要明白为什么rdd里面的方法才叫算子,因为算子方法在executor端执行。
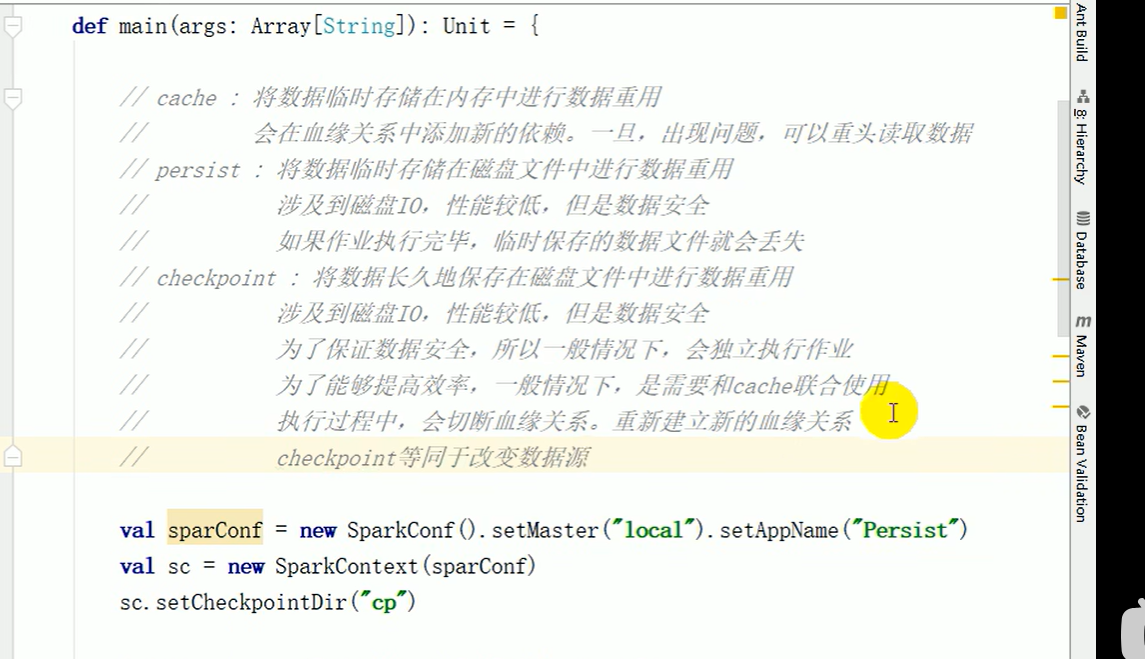
P92说明了RDD之间的依赖和血缘关系
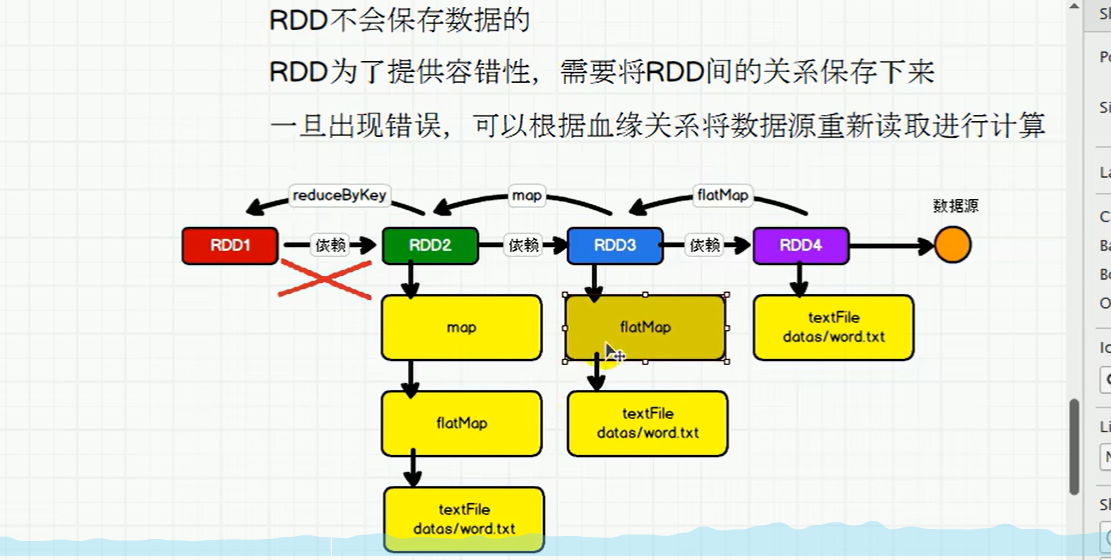
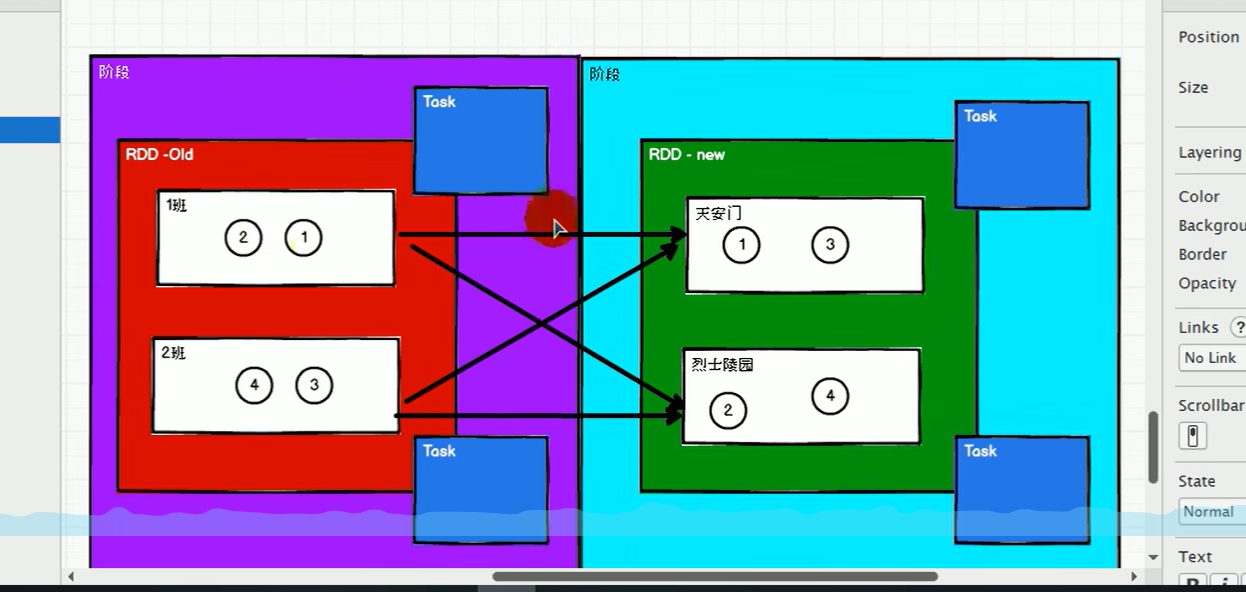
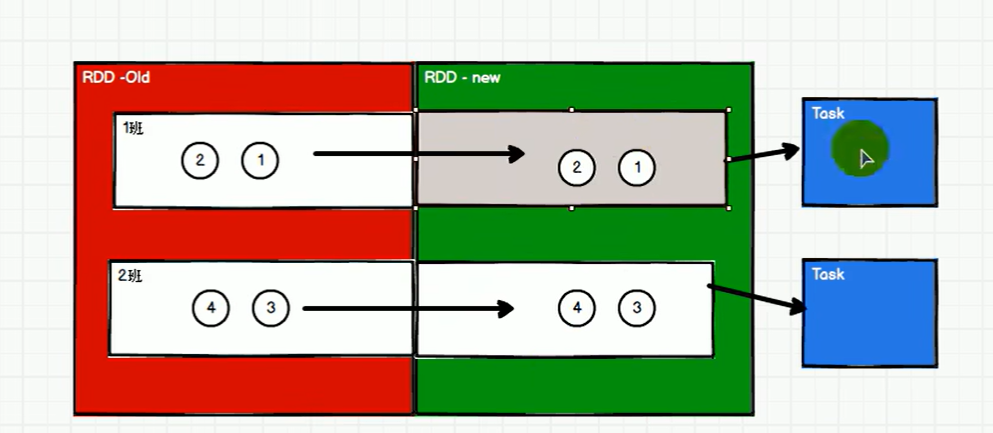
窄依赖指下游rdd里面的数据只依赖于一个上游的rdd,宽依赖(shuffle)指的是上游的数据被多个下游的rdd所依赖。
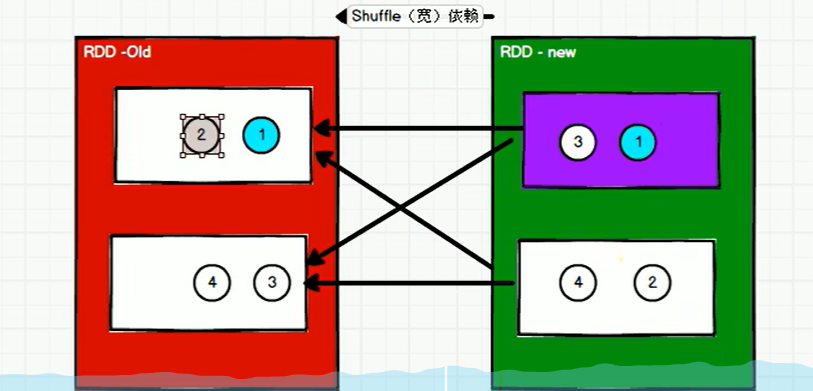
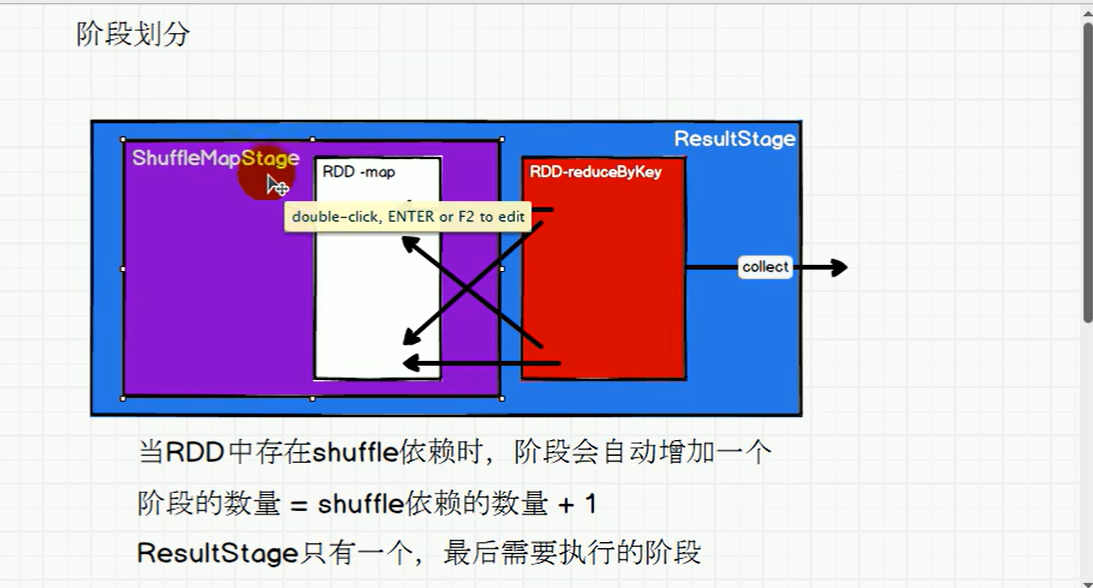
如下有两张图,分别是宽依赖和窄依赖,宽依赖因为要经过shuffle,那么需要分阶段,我以WordCount为例,在进行reduceBYKey之前是一个阶段,然后聚合是另一个阶段(只有一个阶段结束之后才可以执行下一个阶段)
而窄依赖的话,本身不同任务之间不需要相互等待,异步执行完毕即可,所以窄依赖只需要两个Task任务,而涉及宽依赖的RDD中需要更多的Task.
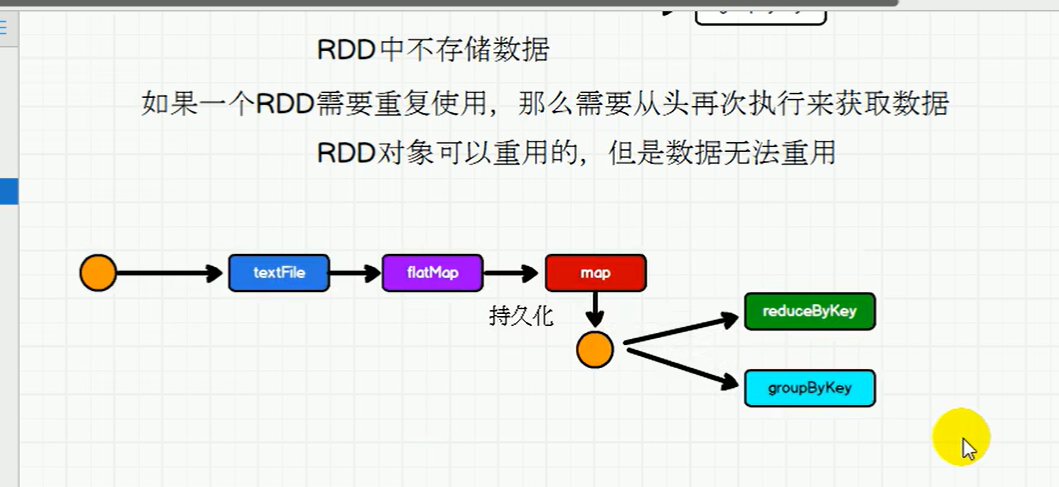
cache持久化,不一定用于对象重用,也有可能在执行行动算子的时候数据执行较长或者比较重要的场合,也可以采用持久化的操作(默认是在内存)
学习完毕RDD,之后又了解到累加器




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用