RDD
RDD是最小的计算单元,里面存放了数据结构和要执行的逻辑,当执行复杂的计算时,往往有多个RDD组合使用
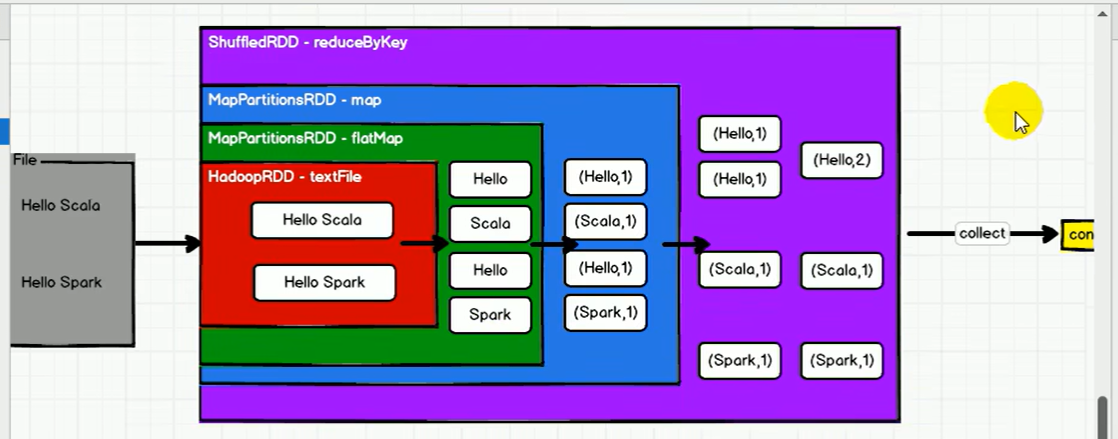

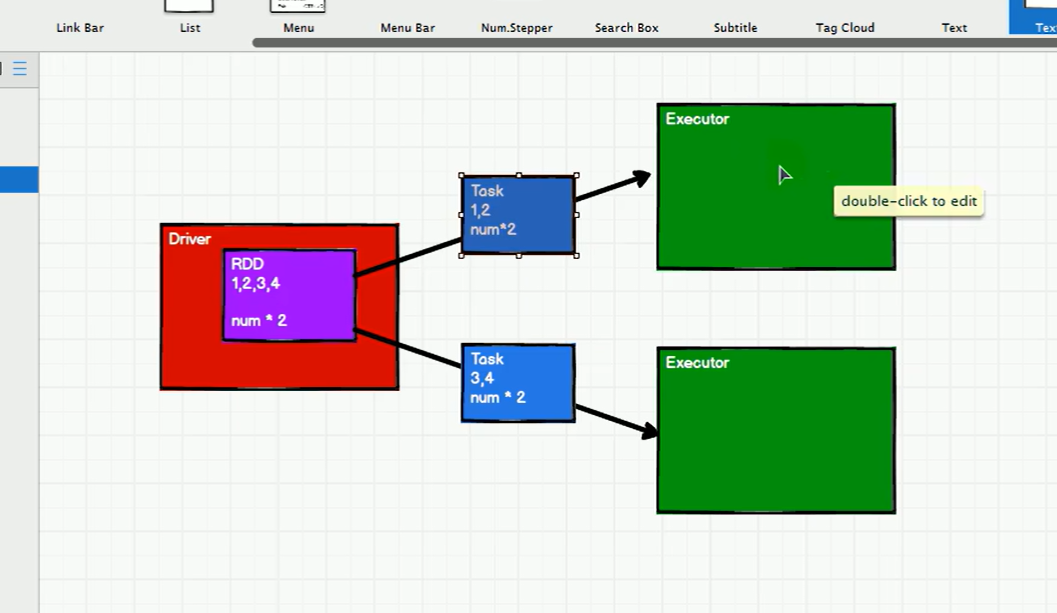
大体的执行流程:

Internally, each RDD is characterized by five main properties:RDD基本五大属性
A list of partitions 分区列表
A function for computing each split 计算的逻辑函数
A list of dependencies on other RDDs 依赖的RDD列表
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 分区的规则
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) 首选位置
==========================================================================================
创建rdd对象的数据源可以是集合,也可以是具体的文件(本地和hdfs都可以)
其次在读取文件时,分区文件是怎样得来的,每个分区文件的数据是怎样进行分配的?这是我们要解决的一个问题
答: 在使用内存创建rdd对象的时候,我们可以直接指定分区的数量,至于每个分区文件的数据是怎么分布的呢,源码中是根据集合的长度和分区数量(未指定的话就按照CPU的默认内核数)来进行计算
计算得出的是一个tuple 这个元组集合就放的是每个分区文件存储哪一部分的内容。
在使用文件作为数据源的时候,首先可以指定最小分区数量,使用文件作为数据源的话,是按照文件的字节大小 除以最小分区数量,余数超过其他单个文件的10%的话,分区数量加一(底层调的hadoop)其次读取文件使用的是TextInputStream,按行读取(这是是hadoop里面提供的读取类) .
里面的数据分布,是按照偏移量进行的。