
flink的watermark机制你学会了吗?
大家好,今天我们来聊一聊flink的Watermark机制。
这也是flink系列的的第一篇文章,如果对flink、大数据感兴趣的小伙伴,记得点个关注呀。
背景
flink作为先进的流水计算引擎,提供了三种时间概念,这对基于时间的流处理应用提供了多种可能。
-
Event time 指生产设备中每个独立的事件发生的时间,比如用户点击产生的时间。
-
Process time 指正在执行相关进程的机器的系统时间。
-
IngestionTime 指事件进入flink的时间。
![]()
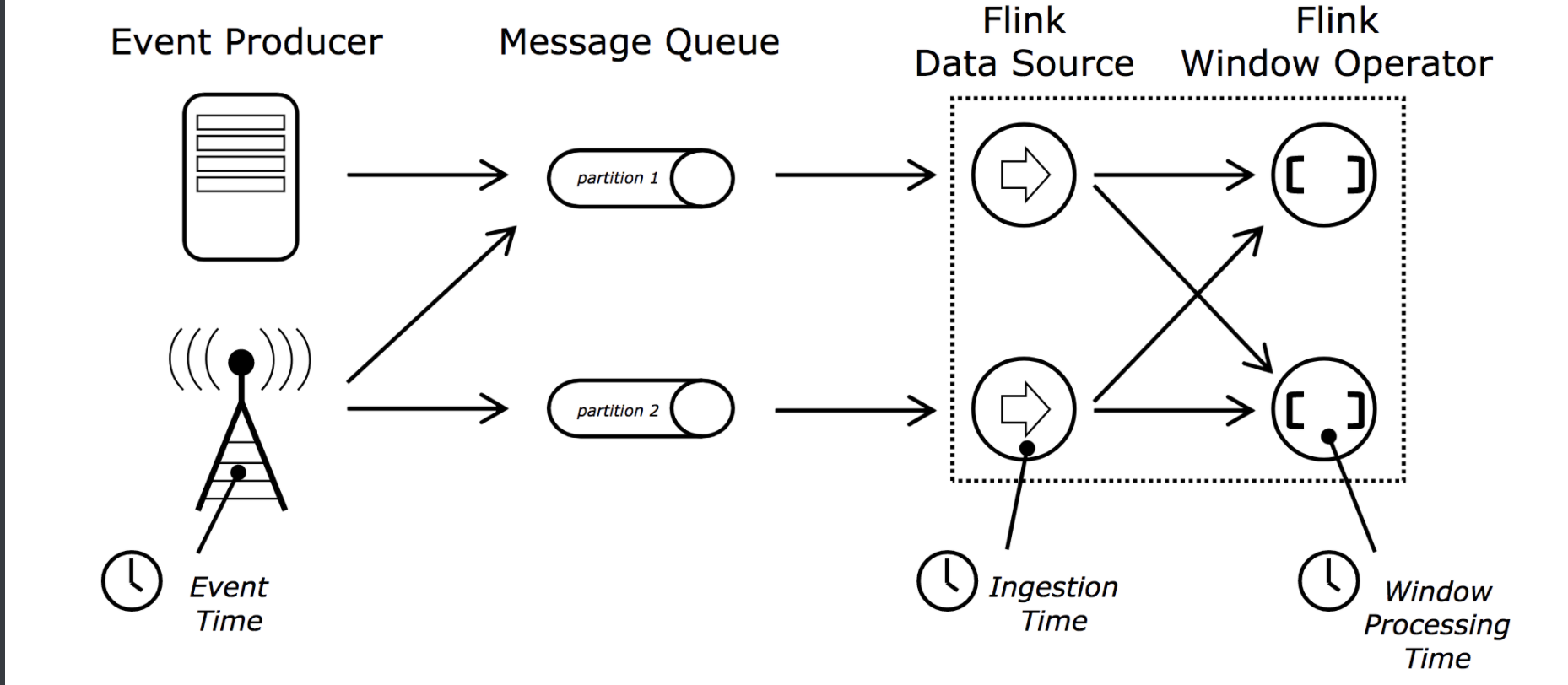
WaterMark机制主要是用来解决EventTime乱序的情况。从事件的产生、到经过消息中间件、然后经过data source和Operator,在传输的过程中,由于网络传输等原因,会导致EventTime出现乱序,如果只是根据EventTime来决定window的运行,我们不能明确数据是否已经全部到位,所以我们需要有一个机制来保证特定的时间后,必须触发window去执行计算了,这个机制就是Watermark。
定义
WaterMark是一种特殊的时间戳,它会被插入到数据流中,用于表示EventTime小于Watermark的事件全部落入到了相应的窗口中。
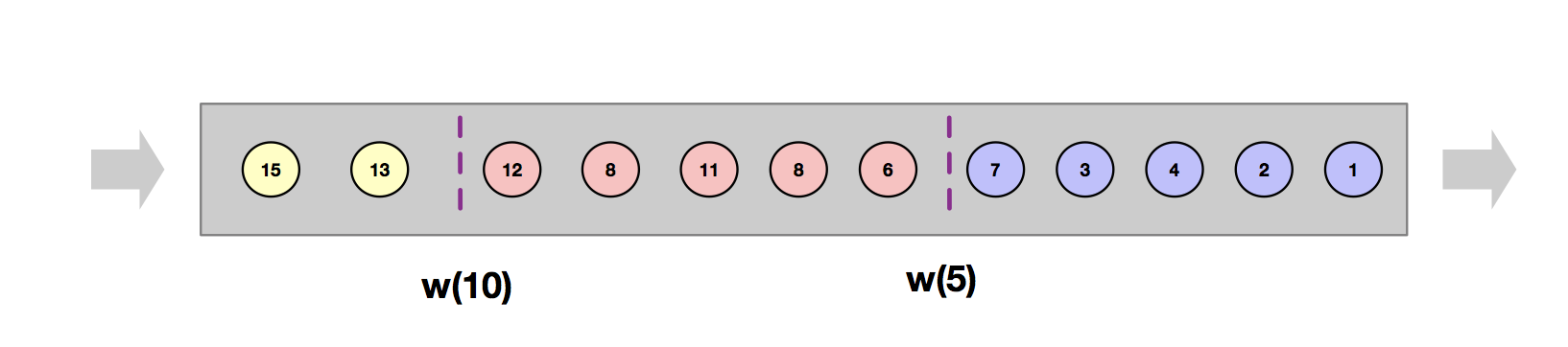
如图所示,这是一个窗口大小为5的乱序流。w(5)表示EventTime小于5的数据已经落入相应的窗口。当Watermark大于等于窗口的最大时间戳(即窗口的endTime),就会触发相应窗口的计算。比如W(5)大于等于5,会触发窗口[0,5)的计算。
生成
WaterMark有两种生成方式,分别是Punctuated Watermark(标点水位线)和Periodic Watermark(周期性水位线)。
-
标点水位线
标点水位线(Punctuated Watermark)是通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下,窗口的触发与时间无关,而是决定于何时收到标记事件。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
-
周期性水位线
周期性的(允许一定时间间隔或者达到一定的记录条数)产生一个Watermark。水位线提升的时间间隔是由用户设置的,在两次水位线提升时隔内会有一部分消息流入,用户可以根据这部分数据来计算出新的水位线。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
案例
在实际的项目中,主要是使用周期性的水位线,我们可以通过env.getConfig().setAutoWatermarkInterval()设置,默认是200ms。
public class test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<String> inputStream = env.socketTextStream("localhost", 8888);
SerializableTimestampAssigner<String> timestampAssigner =
new SerializableTimestampAssigner<String>(){
@Override
public long extractTimestamp(String element, long recordTimestamp) {
String[] fields = element.split(" ");
Long aLong = new Long(fields[0]);
return aLong * 1000L;
}
};
SingleOutputStreamOperator<Tuple2<String,Long>> result=inputStream.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(timestampAssigner)
).map(new MapFunction<String, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(String s) {
return Tuple2.of(s.split(" ")[1],1L);
}
}).keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> stringLongTuple2, Tuple2<String, Long> t1) throws Exception {
return new Tuple2<>(stringLongTuple2.f0,stringLongTuple2.f1+t1.f1);
}
});
result.print();
env.execute("warter mark test");
}
}
当通过nc -l 8888输入数据
1630312530 java
1630312533 java
1630312536 java
1630312540 java
1630312543 java
1630312538 java
1630312545 java
1630312539 java
1630312550 java
1630312549 java
1630312555 java
输出为:
1> (java,5)
1> (java,4)
当事件“1630312545 java”进入流处理后,生成的Watermark为“W(1630312540)”,大于等于窗口[1630312530,1630312540)的endTime,触发窗口的计算,此时延迟数据“1630312538 java”也会被计算在内,所以会输出“(java,5)”,而事件“1630312539 java”是在Watermark已经触发相应的窗口计算后,才进入流处理中,延迟太久,会被忽略掉。当事件“163031255 java”进入流处理后,生成的Wartermark为W(163031250),触发窗口[163031240,163031250)的计算。
最后
到此为止,我们已经把Watermark机制聊完了,如果喜欢,请点个关注吧。
更多有趣知识,请关注公众号【程序员学长】。我给你准备了上百本学习资料,包括python、java、数据结构和算法等。如果需要,请关注公众号【程序员学长】,回复【资料】,即可得。
你知道的越多,你的思维也就越开阔,我们下期再见。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号