

从哈夫曼编码中我们学到了什么?
大家还记得我们在数据结构里学的哈夫曼编码吗?今天我们就来重新温习一下哈夫曼编码,以及通过哈夫曼编码,我们能学到什么核心思想呢。在开始之前,我们先回顾一下什么是哈夫曼编码。哈夫曼编码是一种对数据进行压缩的编码方式,可以有效节省存储空间。我们来看一个例子,假如我们有一个长度为200的字符串电文要传输,并且只包含6种不同的字符,分别是A、B、C、D、E、F。如果明文传输的话,那每个字符占一个字节,就会占用200字节的空间。为了节省空间,我们可以采用3个二进制位来表示一个字符。如下所示:
a(000)、b(001)、c(010)、d(011)、e(100)、f(101)那我们就可以用200*3=600个二进制位来传输,而原来明文需要占用1600个二进制位(1个字节等于8个二进制位),所以节省了空间。那还有没有更节省空间的方式了呢?那就是哈夫曼编码了。
哈夫曼编码
哈夫曼编码不仅会考虑不同字符的个数,同样会考虑每个字符出现的频率,根据频率的不同,选择不同长度的编码。由于哈夫曼编码采用的是不等长的,那我们每次应该读取几位来解压缩呢?这个问题就会导致解压缩会复杂一些。为了避免解压缩过程中的歧义,哈夫曼编码要求给各个字符的编码时,不会出现某个编码是另一个编码前缀的情况。
下面我们来具体看一下哈夫曼编码的编码过程。首先我们假设这6个字符出现的频率如下图所示:

我们把每个字符当作一个节点,并且把他们插入到优先级队列中(按照频率由小到大来排序)。然后我们从队列中取出频率最小的两个节点 A、B,然后新建一个节点 X,把频率设置为两个节点的频率之和,并把这个新节点 X 作为节点 A、B 的父节点。最后再把 X 节点放入到优先级队列中。重复这个过程,直到队列中没有数据。如下图所示:


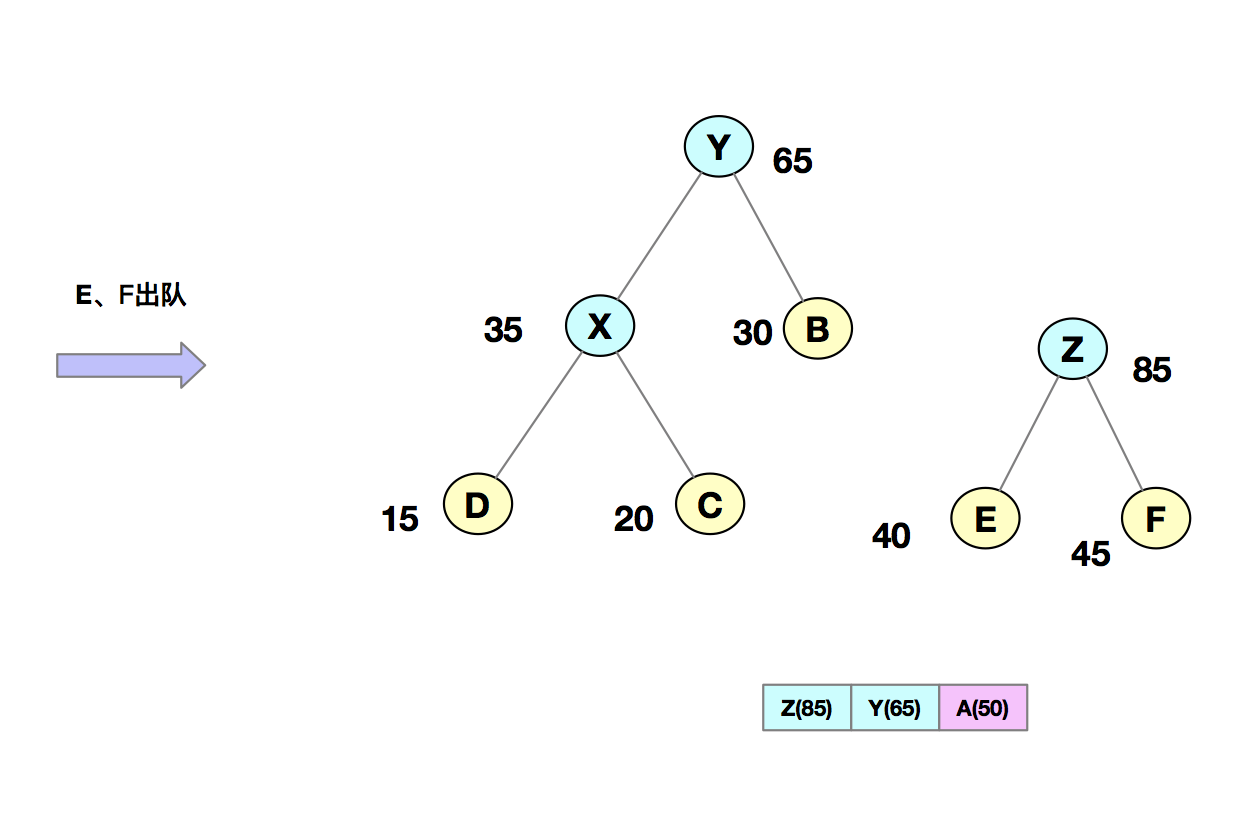
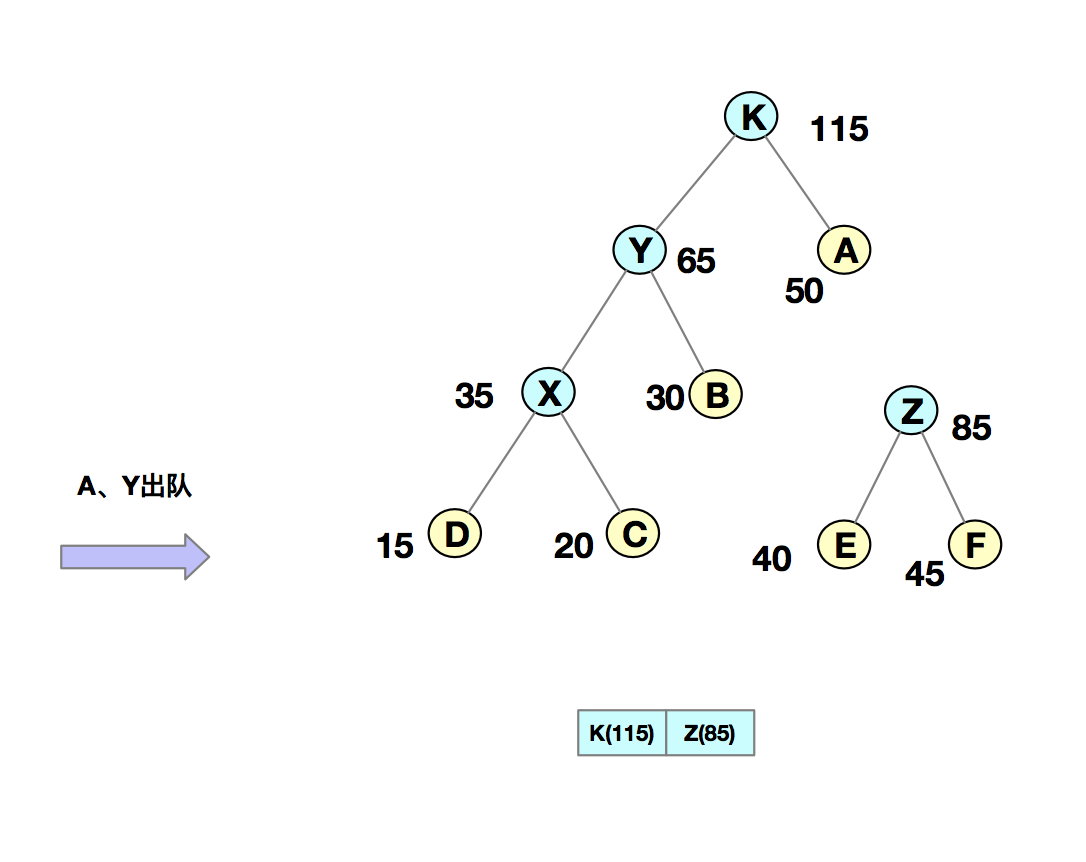
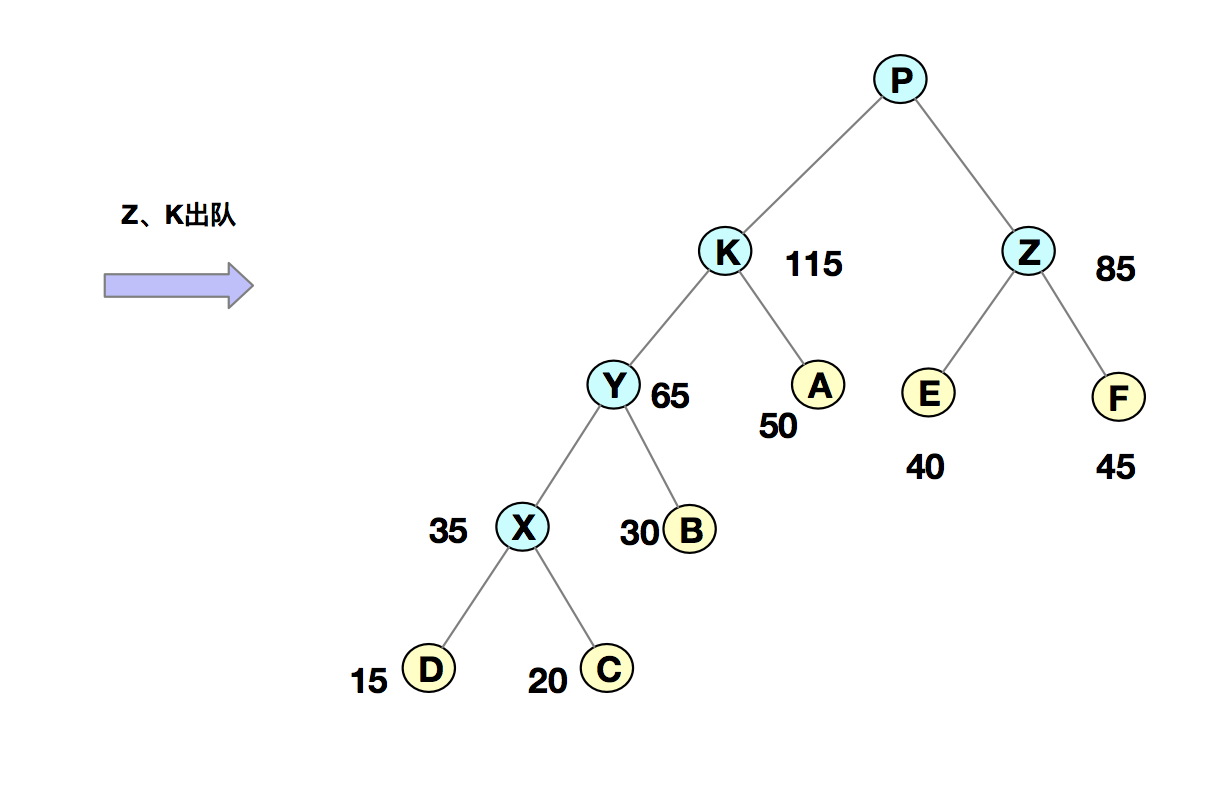
然后,我们给每一条边加上一个权值,指向左子节点的边记为 0,指向右子节点的边,标记为 1,那从根节点到叶节点的路径就是叶节点对应字符的哈夫曼编码。

到目前为止,我们已经把哈夫曼编码的讲完了。现在我们把这个问题抽象一下,哈夫曼编码的目标是用较少的空间来存储给定长度的字符串。那我们该如何对字符串的字符进行编码,才能使得空间最小呢?一个直观的想法是,我们把出现频率比较多的字符,用稍微短一些的编码;把出现频率比较少的字符,用稍微长一些的编码。这就是贪心算法的思想。下面我们来分析一下,对于什么样的问题,我们可以采用贪心算法呢?
贪心算法模型
如果你遇到针对一组数据,定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。我们首先要想到使用贪心算法。回到哈夫曼编码的例子,期望值就是编码后长度最小,限制值就是给定的字符串。这组数据指的就是字符串中的每个不相同的字符,我们对每个字符进行编码,对给定的字符串进行编码,使得编码后的长度最小。
然后尝试看下这个问题是否可以用贪心算法解决。在对限制值同等贡献量的情况下,我们选择对期望值贡献最大的数据。哈夫曼编码每个字符对限制值的贡献量是相同的,都是一个字符的贡献,选择编码最短的,对期望值的贡献最大。所以,我们把出现频率最多的字符,用最少的编码来表示。
以后,在遇到这类问题时,我们就可以考虑一下是否可以抽象成贪心算法模型,如果符合贪心算法模型,那这类问题就可以迎刃而解了。
更多有趣知识,请关注公众号。如果想要本文的pdf版本,可以在私信我。


