

Linux基础6-1 grep和正则表达式
grep:查找文件中符合条件的字符串
- 根据模式搜索文件内容,并将符合模式的字符串行显示出来
- 语法:grep [选项][模式][文件或目录名]
- 选项:
- -i :查找时,忽略字符大小写
- --color:将匹配的行的关键字,以高亮的颜色显示

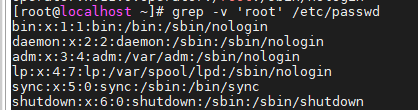
- -v :反向匹配,被模式匹配的行不显示,不匹配的行显示
- -o :值显示被模式匹配的字符串

- -E :使用扩展正则表达式
- -A n :表示匹配到字符后面的n行也显示
- -B n :表示匹配到字符前面的n行也显示
- -C n:表示匹配到的字符前后n行都显示

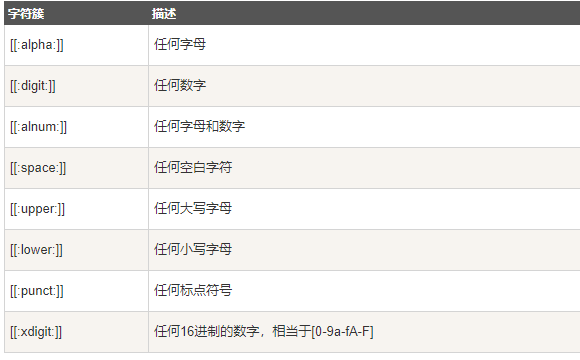
正则表达式(基本):
- 元字符:
- . :匹配任意单个字符
- [] :匹配指定范围内的任意单个字符
- [^] :匹配指定范围外的任意单个字符
- 字符集合:
- 匹配次数:
- * :匹配其前面的字符任意次

- .* :匹配任意长度的任意字符
- \? :匹配其前面的字符一次或0次

- \{m,n}:匹配其前面的字符,最少m次,最多n次,n最多次可以忽略,但是m最少次不能忽略

- 位置锁定
- ^ :锁定行首,此字符后面的任意内容为行首
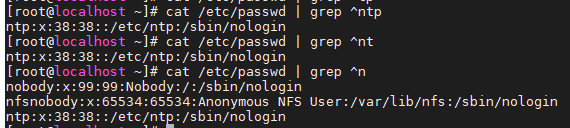
- $ :锁定行尾,此字符前面的任意内容为行尾
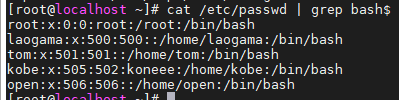
- ^$ :匹配空白行
- \< 或 \b :其后面的任意字符,必须作为单词的首部出现

- \> 或 \b :其前面的任意字符,必须作为单词的尾部出现
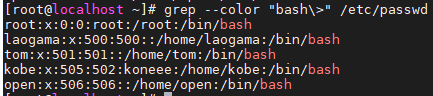
分组:
- \(m..n\):后向引用
- \1 :引用第一个左括号以及与之对应的右括号所包含的内容一致
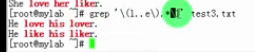
- 第一个匹配的字符串组,之后匹配的要同第一个一致
正则表达式(扩展):grep -E = egrep
- 字符匹配
- . :匹配任意单个字符
- [] :匹配范围内的任意单个字符
- [^] :匹配范围外的任意单个字符
- 字符匹配
- * :匹配其前面字符任意次
- ?:匹配其前面的字符1次或0次
- + :匹配其前字符至少一次
- {m,n} :匹配最少m次,最多n次
- 位置锁定
- ^ :锁定行首,此字符后面的任意内容为行首
- $ :锁定行尾,此字符之前的任意内容为行尾
- ^$ :匹配空白字符
- \< 或 \b :其后面的任意字符,必须为单词的首部出现
- \> 或 \b :其前面的任意字符,必须为单词的尾部出现
- 分组
- ():分组
- \1,\2,\3...
- 或语句
- a | b :a事件或b事件
