
数据结构
数据结构
指同一数据元素类中各数据元素之间存在的关系。
分别为逻辑结构,存储结构(物理结构)和数据的运算。
一:逻辑结构:
逻辑结构是从具体问题抽象出来的数据模型,是描述数据元素及其关系的数学特性的,有时就把逻辑结构简称为数据结构。
逻辑结构可以把数据结构分成线性结构和非线性结构。
♦线性结构:顺序存储结构、链式存储结构。
♦非线性结构:
二:存储结构:
存储结构分四类:顺序存储、链接存储、索引存储、散列存储。
一:顺序存储结构:
它是把逻辑上相邻的结点存储在物理位置相邻的储存单元里,结点间的逻辑关系由存储单元的邻接关系来体现,通常借助于程序设计语言中的数组来实现。
特点:
1、随机存取表中元素。
2、插入和删除操作需要移动元素。
二:链式存储结构:(单向,双向)
它不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系是由附加的指针字段表示的,链式存储结构通常借助于程序设计语言中的指针类型来实现。
特点:
1、比顺序存储结构的存储密度小 (每个节点都由数据域和指针域组成,所以相同空间内假设全存满的话顺序比链式存储更多)。
2、逻辑上相邻的节点物理上不必相邻。
3、插入、删除灵活 (不必移动节点,只要改变节点中的指针)。
4、查找结点时链式存储要比顺序存储慢。
5、每个结点是由数据域和指针域组成。
三:索引存储:
除建立存储结点信息外,还建立附加的索引表来标识结点的地址。索引表由若干索引项组成。
特点:
索引存储结构是用结点的索引号来确定结点存储地址,其优点是检索速度快,缺点是增加了附加的索引表,会占用较多的存储空间。
四:散列存储:(hash存储)
是一种力图将数据元素的存储位置与关键码之间建立确定对应关系的查找技术。
特点:
散列是数组存储方式的一种发展,相比数组,散列的数据访问速度要高于数组,因为可以依据存储数据的部分内容找到数据在数组中的存储位置,进而能够快速实现数据的访问,理想的散列访问速度是非常迅速的,而不像在数组中的遍历过程,采用存储数组中内容的部分元素作为映射函数的输入,映射函数的输出就是存储数据的位置,这样的访问速度就省去了遍历数组的实现。
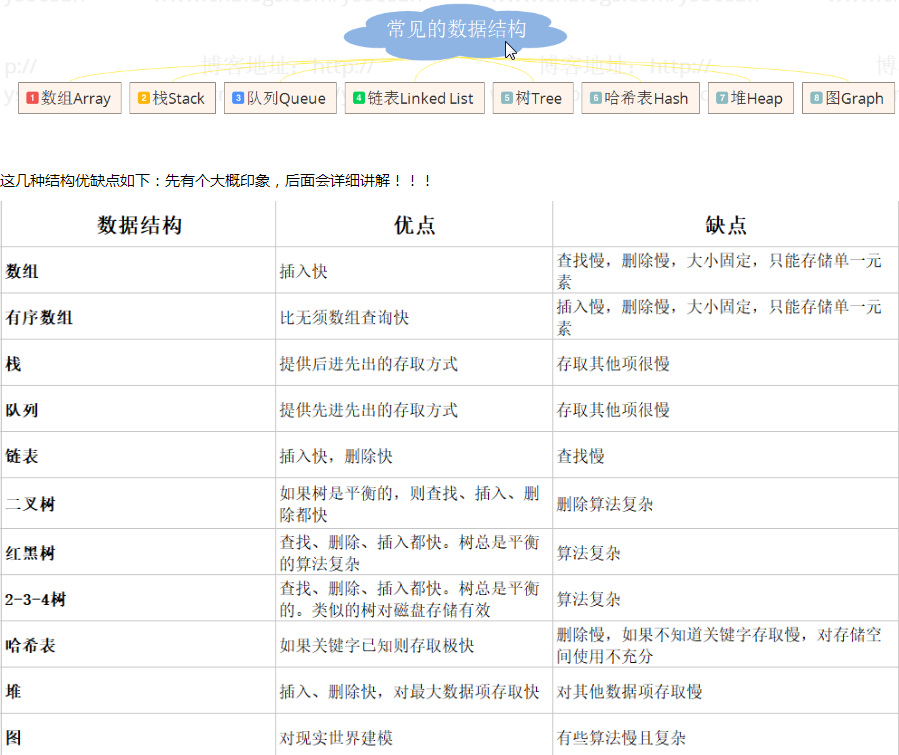
Java中常用的数据结构:
数组
栈
队列
链表
树
图
堆
散列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号