

发展背景
早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位;任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了;于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位;一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间);一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成;而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位

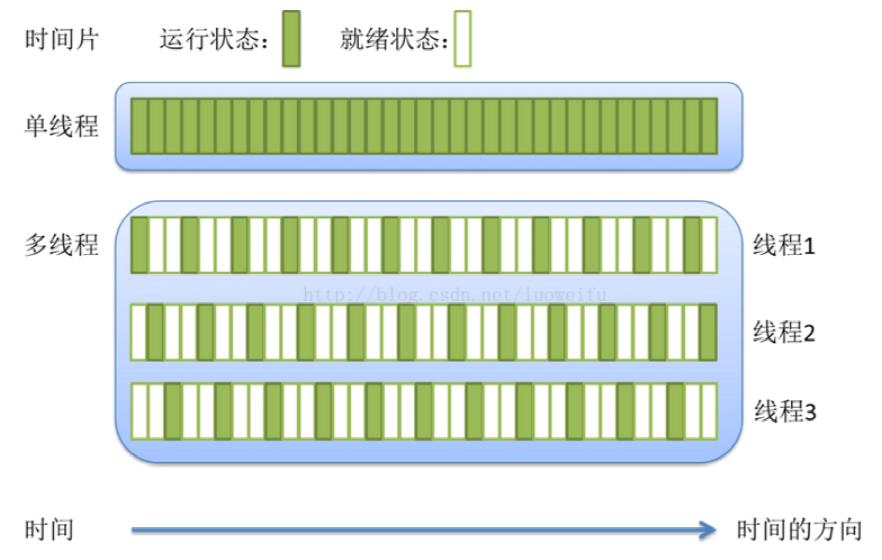
单线程
''' 输出为 listen music 夜曲 Wed Nov 27 09:34:48 2019 listen music 夜曲 Wed Nov 27 09:34:49 2019 look movie 战狼 Wed Nov 27 09:34:50 2019 look movie 战狼 Wed Nov 27 09:34:51 2019 look movie 战狼 Wed Nov 27 09:34:52 2019 end time Wed Nov 27 09:34:53 2019 ''' import time import threading #单线程 def music(name,loop): for i in range(loop): print('listen music %s %s'%(name,time.ctime())) time.sleep(1) def movie(name,loop): for i in range(loop): print('look movie %s %s'%(name,time.ctime())) time.sleep(1) if __name__ == '__main__': music('夜曲',2) movie('战狼',3) print('end time %s'%time.ctime())
多线程
1、threading使用简介(一)
threading.Thread(self, group=None, target=None, name=None, args=(), kwargs={})
Thread 是threading模块中最重要的类之一,可以使用它来创建线程;有两种方式来创建线程:一种是通过继承Thread类,重写它的run方法;另一种是创建一个threading.Thread对象,在它的初始化函数(__init__)中将可调用对象作为参数传入
参数group是预留的,用于将来扩展;
参数target是一个可调用对象(也称为活动[activity]),在线程启动后执行;
参数name是线程的名字,默认值为“Thread-N”,N是一个数字;
参数args和kwargs分别表示调用target时的参数列表和关键字参数
2、threading使用简介(二)
Thread类还定义了以下常用方法与属性:
Thread.getName()/ Thread.name用于获取线程的名称,有返回值,需要print打印出来
Thread.setName()用于设置线程的名称,没有返回值,print打印出来是None
Thread.ident获取线程的标识符,线程标识符是一个非零整数,只有在调用了start()方法之后该属性才有效,否则它只返回None
Thread.is_alive()/Thread.isAlive判断线程是否是激活的(alive),从调用start()方法启动线程,到run()方法执行完毕或遇到未处理异常而中断这段时间内,线程是激活的
Thread.join([timeout])调用Thread.join将会使线程堵塞,直到被调用线程运行结束或超时,参数timeout是一个数值类型,表示超时时间,如果未提供该参数,那么主线程将一直堵塞到被调线程结束
①包含在 threading.Thread中,里面均视为子线程
②除了“不包含在Thread里面的程序”,UI界面和Main函数均为主线程
3、threading使用简介(三)
python对于thread的管理中有两个函数:
Join()和setDaemon()
join:如在一个线程B中调用thread1.join(),则thread1结束后,线程B才会接着threada.join()往后运行
setDaemon:主线程A启动了子线程B,调用B.setDaemaon(True),则主线程结束时,会把子线程B也杀死,必须在运行线程之前设置
Thread.isDaemon()/ Thread.daemon用于获取线程的名称,有返回值,需要print打印出来
''' 输出为 listen music 夜曲 Fri Nov 29 23:38:25 2019 musicThread look movie 战狼 Fri Nov 29 23:38:25 2019 movieThread 5132 6088 listen music 夜曲 Fri Nov 29 23:38:26 2019 musicThread look movie 战狼 Fri Nov 29 23:38:26 2019 movieThread 主线程结束:Fri Nov 29 23:38:27 2019 ''' #多线程 import time import threading def music(name,loop): for i in range(loop): print('listen music %s %s %s'%(name,time.ctime(),threading.Thread.getName(t1))) time.sleep(1) def movie(name,loop): for i in range(loop): print('look movie %s %s %s'%(name,time.ctime(),threading.Thread.getName(t2))) time.sleep(1) #1.创建多线程 t1 = threading.Thread(target= music,args=('夜曲',2)) t1.setName('musicThread') t2 = threading.Thread(target= movie,args=('战狼',2),name = 'movieThread') if __name__ == '__main__': #4.守护主线程,主线程结束杀死子线程,在开启子线程之前调用 t1.setDaemon(True) t2.setDaemon(True) #2.启动线程 t1.start() t2.start() #time.sleep(1) print(t1.ident) print(t2.ident) #3.join 可以对主线程进行阻塞,等所有的子线程运行结束在运行主线程 t1.join() t2.join() print('主线程结束:%s'%time.ctime())
GIL全局解释锁
为了利用多核,Python开始支持多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁,于是有了GIL这把超级大锁;但当CPU有多个核心的时候,问题就来了——从release GIL到acquire GIL之间几乎是没有间隙的,所以当在其他核心上的线程被唤醒时,大部分情况下主线程已经又再一次获取到GIL了,这个时候被唤醒执行的线程只能白白的浪费CPU时间,看着另一个线程拿着GIL欢快的执行着,然后达到切换时间后进入待调度状态,再被唤醒,再等待,以此往复恶性循环;GIL的存在导致多线程无法很好的利用多核CPU的并发处理能力;所以一般情况下不会用到多线程
#加锁 import threading balance = 0 def change(n): global balance balance+=n balance-=n # def run_thread(n): #不加锁会造成抢资源 # for i in range(1000000): # change(n) lock = threading.Lock() #获取线程锁 def run_thread(n): for i in range(1000): #获取锁 lock.acquire() try: #固定格式 change(n) finally: #释放锁 lock.release() t1 = threading.Thread(target= run_thread,args=(4,))#args里面必须传入元组 t2 = threading.Thread(target= run_thread,args=(8,)) t1.start() t2.start() t1.join() t2.join() print(balance) #输出为0
单进程
''' 输出为 SKT fighting SKT fighting come on baby come on baby come on baby ''' import time import multiprocessing #单进程 def work_1(f,n): print('work_1 start') for i in range(n): with open(f,'a') as fs: fs.write('SKT fighting\n') time.sleep(1) print('work_1 end') def work_2(f,n): print('work_2 start') for i in range(n): with open(f,'a') as fs: fs.write('come on baby \n') time.sleep(1) print('work_2 end') if __name__ == '__main__': work_1('file.txt',2) work_2('file.txt',3)
多进程
用multiprocessing替代Thread
multiprocessing库的出现很大程度上是为了弥补thread库因为GIL低效的缺陷;它完整的复制了一套thread所提供的接口,方便迁移;唯一的不同就是它使用了多进程而不是多线程;每个进程有自己的独立的GIL,完全并行,无GIL的限制(进程中包括线程),可充分利用多cpu多核的环境,因此也不会出现进程之间的GIL争抢
Multiprocessing使用简介:
1、multiprocessing包是Python中的多进程管理包,与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程;该Process对象与Thread对象的用法相同,也有start(),run(), join()等方法
2、此外multiprocessing包中也有Lock/Event/Semaphore/Condition类 (这些对象可以像多线程那样,通过参数传递给各个进程),用以同步进程,其用法与threading包中的Thread类一致;所以,multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的情境
3、multiprocessing提供了threading包中没有的IPC(比如Pipe和Queue),效率上更高;应优先考虑Pipe和Queue,避免使用Lock/ Event/ Semaphore/Condition等同步方式 (因为它们占据的不是用户进程的资源,而是线程)
#多进程 ''' 输出为 work_1 start work_2 start work_1 end work_2 end ''' import time import multiprocessing def work_1(f,n): print('work_1 start') for i in range(n): with open(f,'a') as fs: fs.write('SKT fighting\n') time.sleep(1) print('work_1 end') def work_2(f,n): print('work_2 start') for i in range(n): with open(f,'a') as fs: fs.write('come on baby \n') time.sleep(1) print('work_2 end') if __name__ == '__main__': p1 = multiprocessing.Process(target=work_1,args = ('file.txt',2)) p2 = multiprocessing.Process(target=work_2, args=('file.txt', 2)) p1.start() p2.start()

