
python 技术篇-3行代码搞定图像文字识别,pytesseract库实现
我们需要 pillow 和 pytesseract 这两个库,pip install 安装就好。
还需要安装 Tesseract-OCR.exe 然后配置下就好了。
具体的环境配置方法请看
python 技术篇-使用pytesseract库进行图像识别之环境配置
英文字母图像识别演示
这个是我保存名为 English.png 的图片,下面我来提取文字。
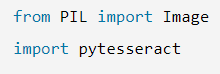
pytesseract 库的 image_to_string() 方法就能把图片中的英文字母提取出来。
from PIL import Image
import pytesseract
image = Image.open('English.png')
content = pytesseract.image_to_string(image) # 解析图片
print(content)
运行效果图:
注:有些字体可能会识别出现问题,尽量用比较标准的字体。

中文汉字图像识别演示
这个是我保存名为 chinese.png 的图片,下面我来提取文字。
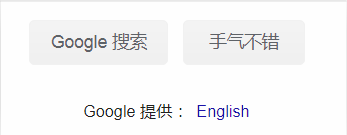
首先需要安装对应的语言包:
Tesseract各个版本语言包获取方式和安装方法
要在pytesseract 库的 image_to_string() 方法里加个参数lang='chi_sim',这个就是引用对应的中文语言包,中文语言包的全名是 chi_sim.traineddata。
from PIL import Image
import pytesseract
image = Image.open('English.png')
content = pytesseract.image_to_string(image, lang='chi_sim') # 解析图片
print(content)
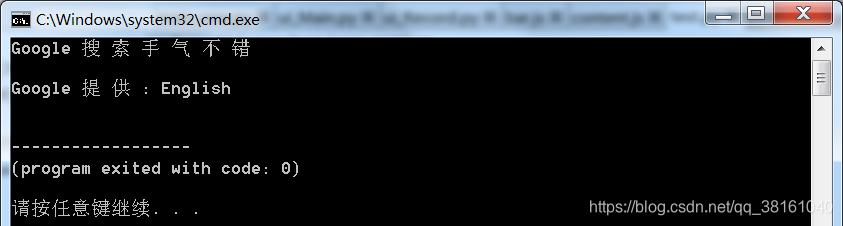
运行效果图:
注:有些字体可能会识别出现问题,尽量用比较标准的字体。
有什么问题可以评论区留言!
喜欢的点个赞❤吧!
各位好,我是csdn的小蓝枣,现在我的博客已经同步到博客园啦,欢迎大家关注哈!也欢迎大家关注我的公众号Py_JSQY!每天会更新有趣的科技文!哈哈!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号