
Python 技术篇-百度语音识别API接口调用演示
百度语音识别api官网文档
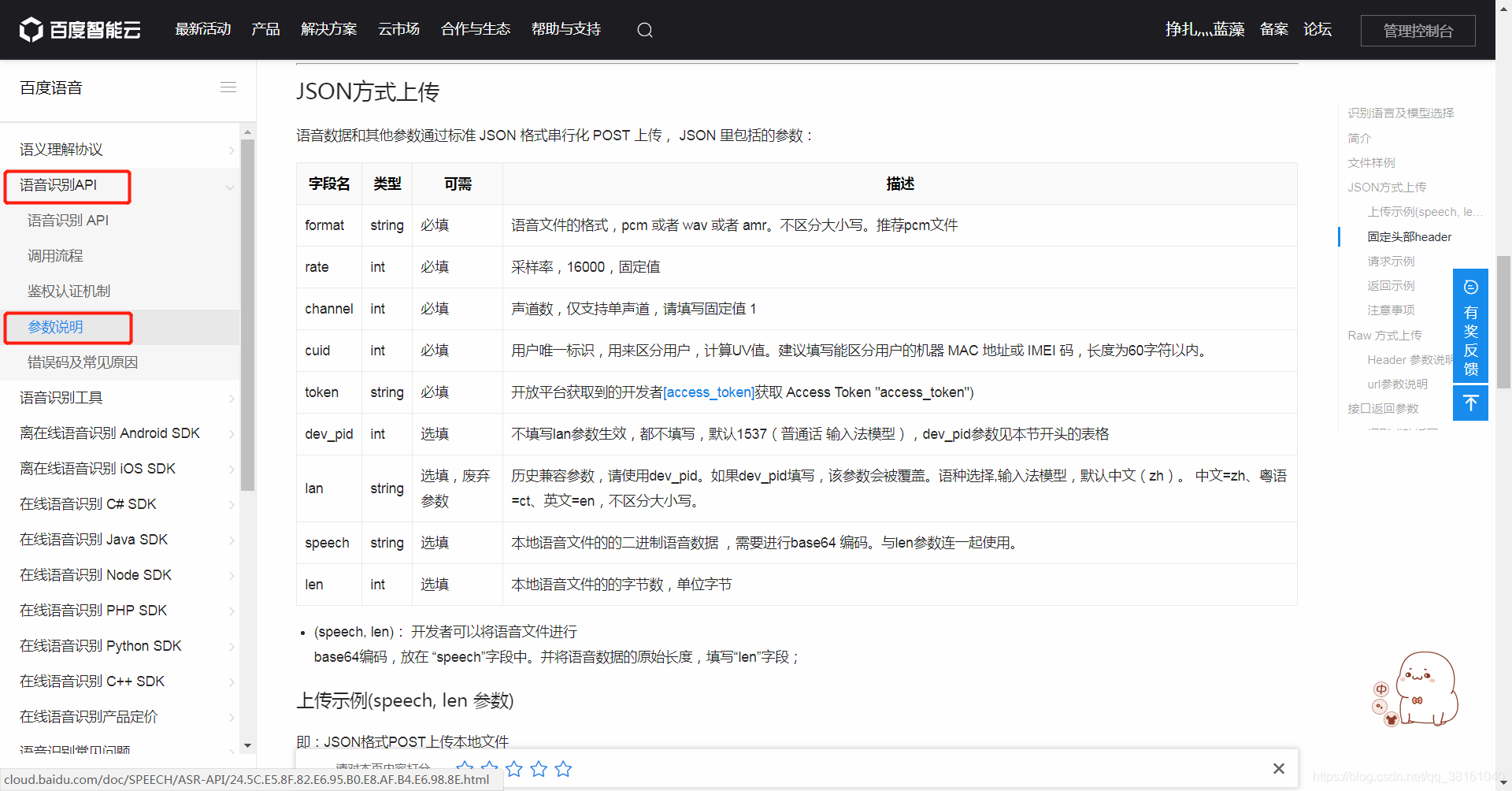
现在演示的是识别音频文件的内容。
重要:token 参数的获取请看上一篇文章:
Python 技术篇-百度语音API鉴权认证获取Access Token
注:下面的 token 是我自己申请的,建议按照我的文章自己来申请专属的。
import requests
import os
import base64
import json
apiUrl='http://vop.baidu.com/server_api'
filename = "16k.pcm" # 这是我下载到本地的音频样例文件名
size = os.path.getsize(filename) # 获取本地语音文件尺寸
file1 = open(filename, "rb").read() # 读取本地语音文件
text = base64.b64encode(file1).decode("utf-8") # 对读取的文件进行base64编码
data = {
"format":"pcm", # 音频格式
"rate":16000, # 采样率,固定值16000
"dev_pid":1536, # 普通话
"channel":1, # 频道,固定值1
"token":"24.0c828682d414bf79b08f89c4c7dcd83a.2592000.1562739150.282335-16470175", # 重要,鉴权认证Access Token,需要自己来申请
"cuid":"DC-85-DE-F9-08-59", # 随便一个值就好了,官网推荐是个人电脑的MAC地址
"len":size, # 语音文件的尺寸
"speech":text, # base64编码的语音文件
}
try:
r = requests.post(apiUrl, data = json.dumps(data)).json()
print(r)
print(r.get("result")[0])
except Exception as e:
print(e)
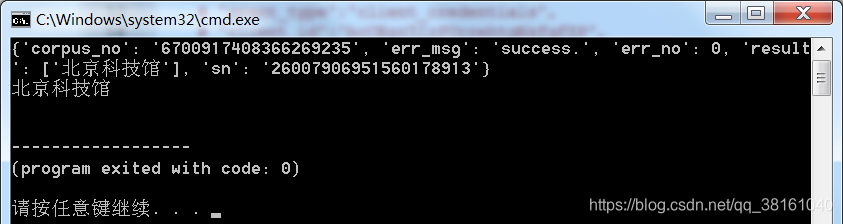
运行效果图:
北京科技馆就是我音频文件的内容。
音频样例文件下载就在帮助文档里。

喜欢的点个赞❤吧!
各位好,我是csdn的小蓝枣,现在我的博客已经同步到博客园啦,欢迎大家关注哈!也欢迎大家关注我的公众号Py_JSQY!每天会更新有趣的科技文!哈哈!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号