

unity广州站gpu resident drawer笔记
unity广州站gpu resident drawer笔记
什么是gpu resident drawer
将MeshRenderer数据转为BRG batch(BatchRendererGroup)数据的机制。

它在unity6正式推出,并关联dots。
它优化的是CPU耗时,但也可能进而提高gpu的性能。因为需要提交给GPU的绘制调用更少。
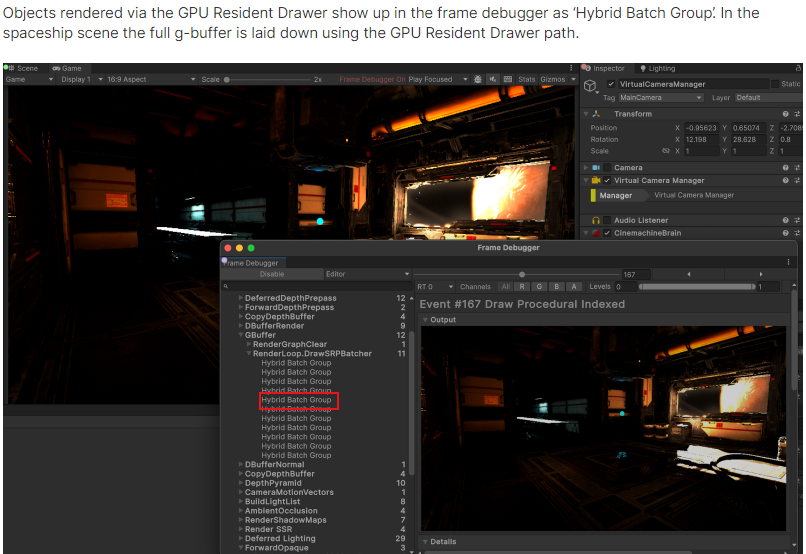
通过gpu resident drawer绘制的dc可以在framedebuger中的Hybrid Batch Group看到。
gpu resident drawer的好处
1.Persistent batch。更少的合批。
2.GPU Persistent data model。 用SoA思想减少cpu与gpu传输数据的时间。(既优化了结构大小,也优化的顺序)
官网说有1.5倍提升。
3.gpu渲染n+1帧时,用户可能会尝试对persisent buffer进行写操作,会导致数据乱掉,gpu resident drawer通过双缓存解决这个问题。
gpu resident drawer如何组织batch
传统srp组织batch的特点:
srp batch组织根据mesh render顺序进行合批,render间会被不同数据(mesh || meterial)打断。
srp组织render数据是每个render结构存储一个obj2world矩阵、world2obj矩阵和BaseColor。
srp随场景复杂度提高,可能会有瓶颈。因为srp组织batch只在主线程中单线程执行(见Profiler的RenderLoop.GPUSrpBatcher)。且srp有减少cpu与gpu传输数据的时间,但不能减少drawcall。
gpu resident drawer提交dc的大致流程
MeshRenderer数据转为BRG batch数据。
上传render数据到gpu
renderer进行裁剪
提交drawcall
gpu resident drawer如何减少drawcall
遍历一定范围Renderer的mesh和material一样,是否产生阴影,设置归属的BatchDrawRange组。
重映射remap所有render的顺序。
根据remap后的BatchDrawRange组提出三个数组(local to world、world to local和color,而srp是单个render一个local2worl、world2local 和color)。

前面提到了优化了结构大小便如下图,少了一个float。

遍历所有相机,与每个相机的视锥6个平面求交,每个相机与每个可产生shadow的灯光进行一次计算。unity用多线程进行裁剪+ smid进行提速。封装成PlanePacked,用 brust对 每四个裁剪屏幕合并成一条指令的计算。
每个 render分到8bit存储在裁剪屏幕求交的结果visibility mask。8 * 8bit= ulong.
每个batch的下表都是从0开始。shader如何采用这些数据呢?会生成visable instanced, remap, 类似内存随机访问,类超低端机器上不好(可能会产生负优化)。
如何开启gpu resident drawer
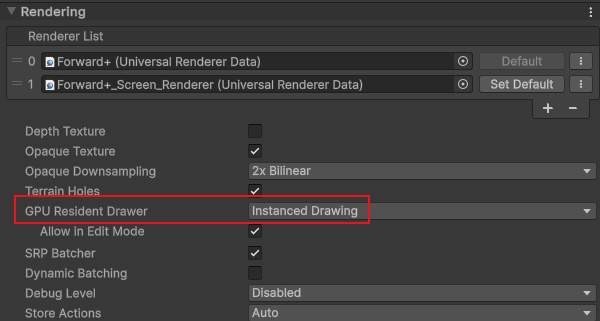
urp
hdrp
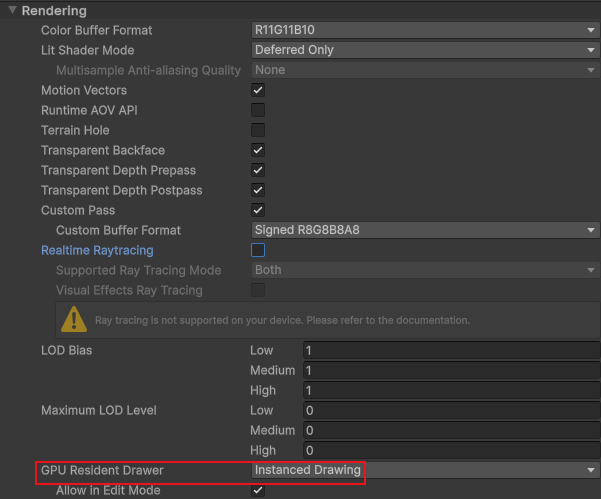
此外,它还需要一些必要的设置(见gpu resident drawer兼容性)
gpu resident drawer的选择性关闭
这在LateUpdate之后但在渲染开始之前每帧发生一次。
如果在渲染期间移动对象,可能数据会乱掉。
可以对象添加DisallowGPUDrivenRendering组件让这些对象不采用gpu resident drawer


gpu resident drawer兼容性
必要的设置

失效的案例

参考:
https://forum.unity.com/threads/gpu-driven-rendering-in-unity.1502702/
https://blog.unity.com/engine-platform/batchrenderergroup-sample-high-frame-rate-on-budget-devices
