

如何量化shader的性能标准学习心得
序言,开头耳
随着如今手游、主机游戏的开发越来越重度。硬件性能跟不上效果产生的能耗,开发者需要主动关注shader的性能问题,并合理指定标准。标准的制定前首先是让问题可被量化。
参考外网大佬的文章:
https://thegamedev.guru/unity-gpu-performance/shader-cost-analysis-mali-offline-compiler/
文章中提到,靠主观感觉某个shader很耗和肉眼统计代码中的耗时点都不科学。应该通过分析工具提供合理的数据。作者推荐可以以mali平台为标准,采用mali offline compiler统计shader的uniform注册数、指令数和循环数等等,开发者综合这些数据给出对该shader的合理平价。
以下是官方连接:
  官方介绍 :https://developer.arm.com/Tools and Software/Mali Offline Compiler
  官方引导 :https://developer.arm.com/documentation/101863/0801/Introduction?lang=en
当然,不同平台也有自己对应的工具:Arm的Mali Offline Compiler、NVIDIA的NVIDIA ShaderPerf、Imagination的PVRShaderEditor、 PowerVRAM的PVRUniSCo Shader分析器,XCode除了有Vertex和Fragment的耗时统计外,还能精确到每一行的耗时。移动端标准gpu型号:mali、高通、powervr(少数),所以这里特化以arm mali为例。
接下来看看工具的简单使用和shader标准应该如何指定。
mali offline compiler安装:
首先需要注册arm developer的用户账号。
官网连接:https://developer.arm.com

根据官方文档介绍需要先安装Arm Mobile studio。
官网安装引导:https://developer.arm.com/documentation/101863/0801/Using-Mali-Offline-Compiler/Install-Mali-Offline-Compiler?lang=en
如果下载无反应,看看是不是禁止了什么网络选项,若提示需要拓展组件IBM Aspera Connect,那安装一个便是,再重新点击下载即可。
由于本人是window环境,下载的是Setup Wizard。下载后直接双节exe根据引导安装即可。
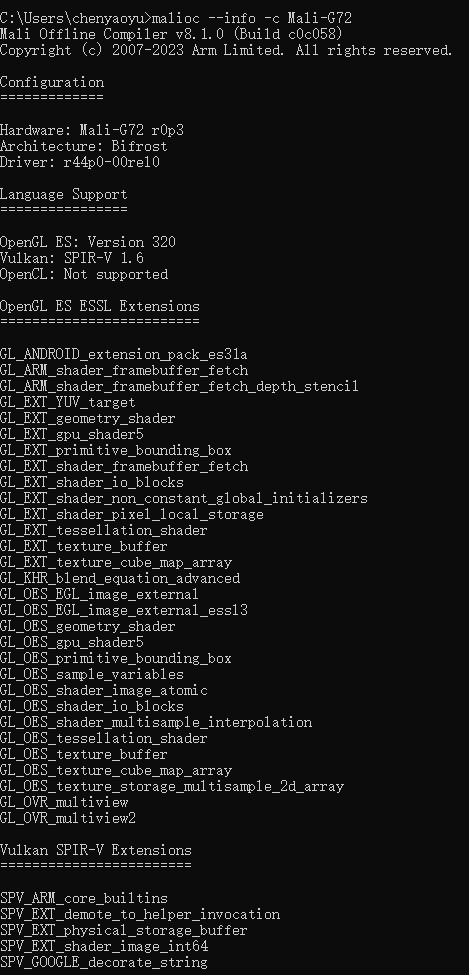
检验mali offline compiler是否可用。
官方工具使用说明:https://developer.arm.com/documentation/101863/0801/Using-Mali-Offline-Compiler/Querying-compiler-capabilities,检验mali offline compiler是否可用。
malioc --info -c Mali-G72
输出如下便是可用。
官方还是很贴心,安装目录下就有引导说明。里面的内容就是官方引导的内容。
官方线上引导说明: https://developer.arm.com/documentation/101863/0801/Using-Mali-Offline-Compiler
获取opengl shader代码
mali offline compiler评估的是标准的opengl shader代码,根我们在unity中编写的shader是存在差异的,unity shader、ue的蓝图是引擎简化过的shader,里面包含了一些引擎自定义的语法、关键字和宏等等,经过引擎编译后才会生成对应平台的shader代码。
那么我们如何获取标准的opengl shader代码呢?
如果是采用unity的开发者,Unity可以在直接在inspector检查器中只选中OpenGLES30,然后点击compile and show code获取对应平台的shader。
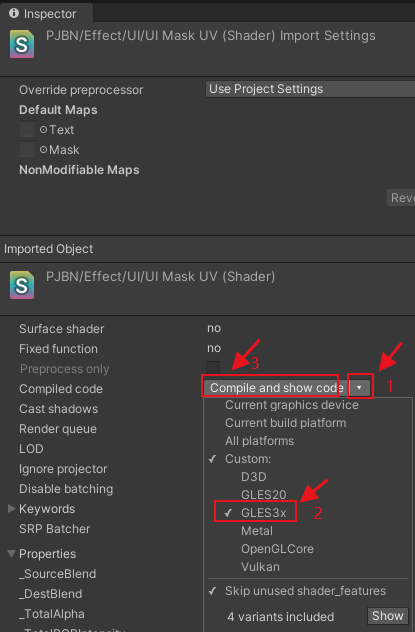
以#ifdef VERTEX与#endif包裹的顶点卓着色器代码(不包含#ifdef VERTEX),复制到新文件中并以.vert为扩展名。
以#ifdef FRAGMENT与#endif包裹的片段着色器代码(不包含#ifdef FRAGMENT),复制到新文件中并以.frag为扩展名。
顺便插一句,这里显示是着色器本身的变量数量,而不是实际编译的内容。
另外,可以使用第三方工具在移动端中截帧获取,例如renderdoc截帧在pipelinestate 中获取vs和ps的shader源码。这个具体可以参考道人大佬的这篇(https://zhuanlan.zhihu.com/p/568990608,虽然是ue的,但工具用法大体差不多,此外, 常用移动平台截帧工具:Snapdragon Profiler、Nsight、Renderdoc等。)
虽然Mali Offline Compiler为每种变体报告单独的性能表,但考虑到准确度和效率,最好预先只保留要测试的keywords。
malioc -c Mali-G72 shader.frag
-c 指定要测试的GPU,不指定则会使用默认型号GPU,后面接顶点着色器或者片段着色器。
输出中就包含了如下信息:
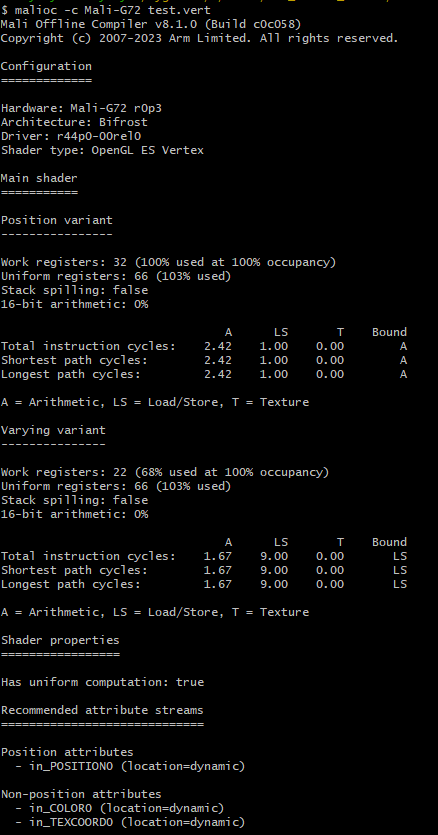
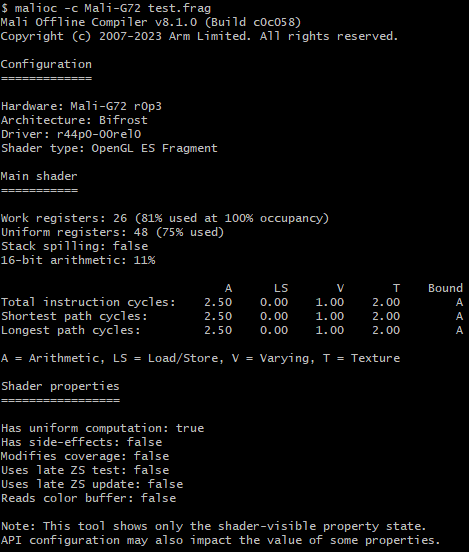
配置信息 Configuration
Hardware硬件信息
Architecture GPU架构
Driver驱动
Shader type 图形API 及Sharder类型
Shader信息
1. Work registers 该shader工作使用的寄存器数量,减少提升性能
2. Uniform registers 存储着色器可能需要的常量,所有线程都有共享uniform register
3. Stack spilling 是否有变量被放置到栈内存中,有的话GPU读取是性能消耗较大
4. 16-bit arithmetic 以 16 位或更低精度执行的算术运算的百分比。数值越高代表shader性能越好
5. Total Instruction Cycles :Shader生成的所有指令的累积执行周期数,与控制流无关
6. Shortest Path Cycles/Longest Path Cycles :通过着色器程序的最短/最长控制流路径的循环数的估计
7. A = Arithmetic 在Mali Valhall 架构的GPU实现了两个并行处理单元,算数单元A被拆分为 FMA , CVT , SFU
FMA(Fused Multi-Add)主要的算术管道,实现了着色器代码中广泛使用的浮点乘法器
CVT(Convert)单元负责基本的整型操作、数据类型的转换、分支处理
SFU(Special Function Unit):三角函数,指数,对数等
8. LS = Load/Store operation 读取和存储的操作消耗,处理所有非纹理内存访问
9. T = Texture operations 所有纹理采样和过滤操作消耗
10. V = Varying operations 在shader中不同单位插值的消耗
11. Bound 循环计数最高的功能单元,识别瓶颈单元。A是算术边界则通过减少数学运算的数量或精度来优化
Shader properties
shader 使用了能影响shader执行表现的相关语言特性信息
1. Has uniform computation
是否有任何计算仅依赖于文字常量或统一值,尽量把这系列的计算移植到在CPU上进行逻辑处理
2. Has side-effects
此着色器是否具有在固定图形管道之外的内存中可见的副作用
3. Modifies coverage
片段着色器是否具有可以通过着色器执行更改的覆盖掩码,例如,通过使用丢弃语句
4. Uses late ZS update
具有可修改覆盖率的shader必须使用late ZS update,这会降低early ZS test在同一坐标上的later片段的效率
5. Uses late ZS test
片段shader是否包含了强制late ZS test的逻辑。会禁用early ZS test和hidden surface removal的使用,会导致性能损失
6. Reads color buffer
fragment shader 是否包含了从color buffer中读取的逻辑
有哪些需关注的指标:
gpu的压力表现:
gpu耗时长,GPU压力大会使得CPU等待GPU完成工作的耗时增加。
gpu发热。由于移动端硬件客观上存在体积较小、散热难的问题,使得GPU发热会物理上显著影响到CPU芯片温度同时上升,严重的即产生降频现象。
衡量gpu压力的指标:带宽、图元数量、Overdraw、时钟数据。
直接影响gpu耗时与发热的shader因素一般有:Fragment Shader的屏占比、指令数和时钟周期数。
(图自:https://www.163.com/dy/article/IKQT55G20511L9VL.html)
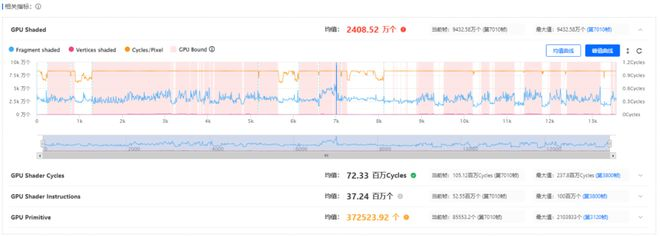
以UWA服务为例,在GOT Online GPU模式报告中,UWA将GPU Clocks作为衡量GPU性能的主要指标,当GPU Clocks目标帧率>=GPU最大频率80%时,这一帧会被判定为GPU Bound。GPU Bound反映了GPU在当前帧中计算所耗费的时钟周期数过高,使得单位时间内GPU的额定时钟周期数无法支持游戏满帧运行,即GPU压力。
此外,UWA的进一步服务中会详细测试项目中所有使用率较高的Shader在不同关键字组合下变体的复杂度,从而定位需要着重优化的Shader资源及其变体。
举个例子,假设采用Mali-G72 MP2、双核和每时钟两像素GPU、运行频率为1.3GHz的设备,项目目标为1080p分辨率,30FPS帧率(它就是每秒执行的时钟周期数)。一次测试一帧的总时钟为800w = 所有相机的RenderSingleCamera的时钟总和。某个效果pass的时钟为340w。
那么该设备的最佳情况周期预算为:
单个像素每帧的推荐上限周期:
一秒内需要处理的像素个数pixelsPerSecond = 1920 * 1080 * 30 = 1 2441 6000
每秒所有核的推荐的总时钟cyclesPerSecond = 2 * 130000w * 80% = 26 0000 0000 * 0.8 = 15 6000 0000
单个像素每帧的推荐上限周期cyclesPerPixel = cyclesPerSecond / pixelsPerSecond = 12.53
pass一帧的耗时:
一帧的实际总时钟800w * 帧率30 = 一秒的实际总时钟24000w,
某个效果pass的一帧的时钟为340w / 一秒的总时钟24000w = 该pass一帧的耗时14.17ms
上面提到都只是参考值,目前我还没找到公式可准确的将一个shader cycles转换成具体耗时的标准,即使有,应该是个理论成本,还需要结合实际。因为具体的shader的cycles次数受到自身复杂度、配置的sampler不同特性、fragment占屏比和Overdraw次数影响,所以需结合实际的压测情景下调整cycles后具体总耗时结合“刚好够”+“80%”原则来约定。另外,也可根据计算pass的耗时,判断pass是否超标,再考虑优化其下的shader。
指标从项目中来,跟项目而去,才是最合适项目的。
指标从项目来:
为什么说指标从项目中来,因为每个项目运行时生效的shader个数和复杂度和压力情景各不相同,需要因地制宜地在自己项目极限情况下(比如达到上限玩家数、大招时刻等等业务情景),在不同品质(高中低等)和不同soc(mali、晓龙等等),进行gpu压测,统计gpu的压力。
定分档和标准机型:一般性能组会根据市面或者公司以往产品的数据统计出本项目最低兼容机型和各中机型的用户大致数量占比。根据这些数据划分好不同挡位的机型范围,并提出标准机型作为该挡位的测试机器。
定美术效果的限制:在某个版本下,各部门应该一起确认好,项目在不同品质和soc下允许开启哪些效果,当特殊机型不支持时需要有平替换方案或者砍效果的共识。目标一致才好干活。
压测采样,指定具体标准:根据上面商讨好的效果标准下,先优化一波,尽量保证压测环境没有因为发热而导致降频,再通过工具(snapdragon profiler或者uwa服务)统计好压测场景下的总cycles和各个pass的时钟,根据结果合理的进行划分好各个模块耗时,根据划分再细分shader进行cycles统计,比如根据shader是否基于物理、有无光照、有无阴影,半透明还是不透明,甚至根据业务功能(比如玩家和怪物,场景A和场景B等等)。此外,这些测试一般不是一次通过,可能会因为位置关系导致占屏比不同导致测试出来的结果不同。需要合计几次测试,减少误差。
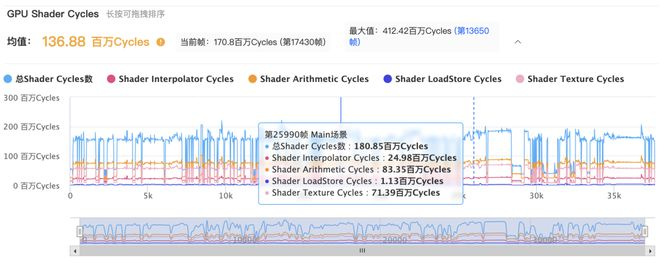
(图自:https://www.163.com/dy/article/IF6L39360511L9VL.html)
规范化制作流程,定期独立环境检查:细分好项目shader,并指定好上限的循环数后,应该做好资源检查和自动化反馈(比如ci机器人通知,提交拦截),例如具体可以通过mali offline compiler工具逐个shader各个变体进行定期检查。超标的shader,需要根据具体shader细化shader特性的开关、类型或者函数替换,并在独立环境中的进行验证。
紧跟项目做好回归测试和保底方案:由于真实的clocks并不是完全均分,优化完代码仍需回到压测情景下检验最终的gpu压力。若遇到特殊机型不支持时就设定好黑名单来动态调整效果开关。
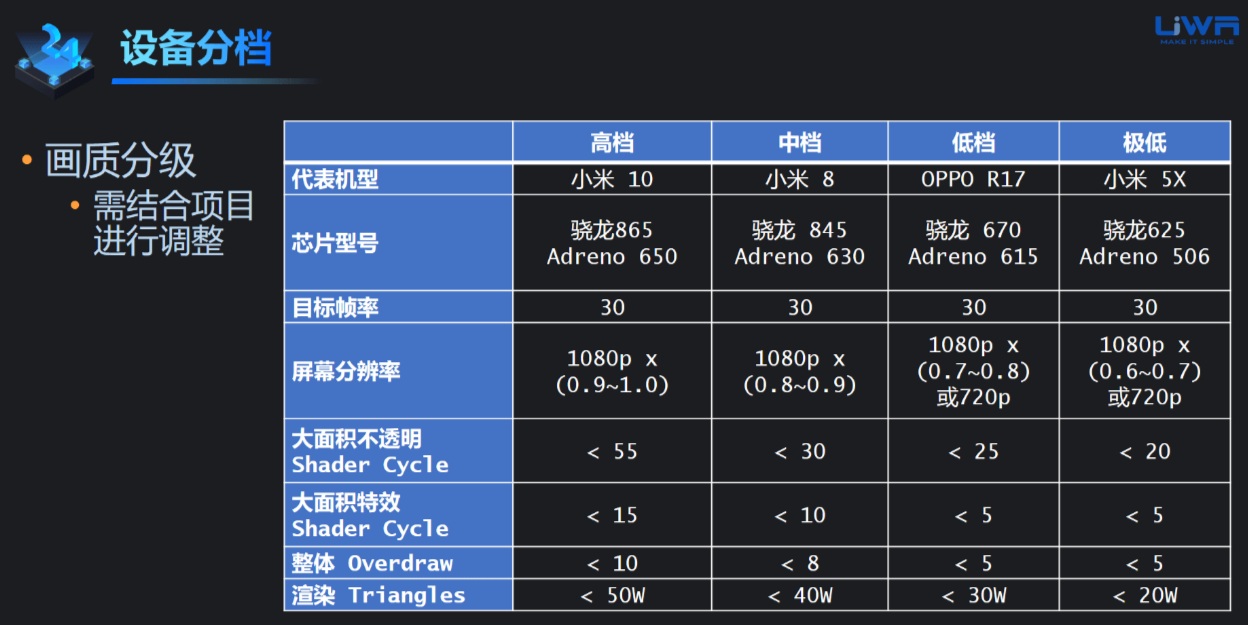
(图自:https://blog.csdn.net/UWA4D/article/details/127862213)
指标跟项目而去:
随着项目不断迭代,初期指定的性能指标可能会出现不再适用的情况,每个大版本后都需要通过跟踪测试和合理调整。
推荐每个版本的初期都需要根据上一个版本的测试结果进行重新压测,根据压测结果看看原本的指标是否需要调整。性能空闲多的,可以考虑放宽美术效果;性能快触碰或者已超过标准值的,可以考虑从shader代码或者砍部分效果出发。
为什么应该在版本初期,因为标准越早出来,就可以越早提供规则检查工具。让美术的提交更加标准化,降低后期优化的成本,而不是到后期来不及改动只能放弃效果或者任风险暴露到外网。
优化gpu及shader的手段:
降低渲染分辨率。
将目标帧率从60下调到27~30。
关注目标设备的cache line大小,适当限制cycles数。
具体开关shader某些特性,比如关闭光照、阴影,开启culling back,非透明物体关闭blend等等。
优化类型,比如改trilinear为bilinear滤波,高精度计算和浮点数计算改为中精度或整形数计算等等。
优化函数,比如用lerp代替if,或通过unroll标记在编译器期展开循环,从而减少Shader代码中flow control数,但可能会导致指令数、寄存器用量增加等等。
采用mipmap
。。。
(新人笔记,如有错误,请指明,如有补充分享,那谢谢大佬)
参考:
https://zhuanlan.zhihu.com/p/644860678
https://blog.csdn.net/mango9126/article/details/122743975
https://www.bilibili.com/read/cv12145909/
https://www.zhihu.com/question/25421190/answer/2273086866?utm_id=0
https://developer.arm.com/documentation/101863/0705/Using-Mali-Offline-Compiler/Performance-analysis/IDVS-shader-variants
https://www.zhihu.com/question/365127321/answer/973288762
https://zhuanlan.zhihu.com/p/560738175?utm_id=0&wd=&eqid=930a25b100048f0a0000000364802a21
https://edu.uwa4d.com/lesson-detail/487/2316/1?isPreview=0
https://developer.arm.com/documentation/102643/0100/Improving-fragment-bound-content
https://www.sohu.com/a/428194690_667928
https://www.163.com/dy/article/IF6L39360511L9VL.html
https://zhuanlan.zhihu.com/p/536477555
