Guava中Lists.partition(List, size) 方法懒划分/懒分区
Guava中Lists.partition(List, size) 方法懒划分/懒分区
背景
前几天有同事使用这个方法,不小心点进去查看源码,源码如下,然他通过idea工具debug发现执行完Lists.partition(List, size) 这一行直接就现实了个size大小如下图:看了源码后根本就没有显示的调用size这些啊,就在那思考不知道为什么?
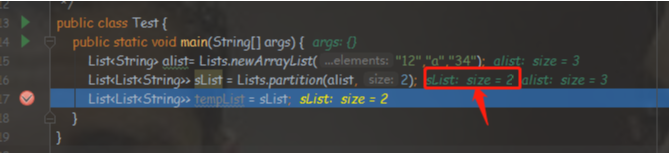
Lists.partition(List, size)源码如下:
@GwtCompatible(emulated = true)
public final class Lists {
.....
public static <T> List<List<T>> partition(List<T> list, int size) {
checkNotNull(list);
checkArgument(size > 0);
return (list instanceof RandomAccess)
? new RandomAccessPartition<>(list, size)
: new Partition<>(list, size);
}
private static class Partition<T> extends AbstractList<List<T>> {
final List<T> list;
final int size;
Partition(List<T> list, int size) {
this.list = list;
this.size = size;
}
@Override
public List<T> get(int index) {
checkElementIndex(index, size());
int start = index * size;
int end = Math.min(start + size, list.size());
return list.subList(start, end);
}
@Override
public int size() {
return IntMath.divide(list.size(), size, RoundingMode.CEILING);
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
}
private static class RandomAccessPartition<T> extends Partition<T> implements RandomAccess {
RandomAccessPartition(List<T> list, int size) {
super(list, size);
}
}
.....
}
分析
发现了问题,我们就应该分析为什么会出现这情况?
通过上面贴出来的代码以及Guava的源码,发现就是创建了一个Partition类过后啥都没做。为什么?
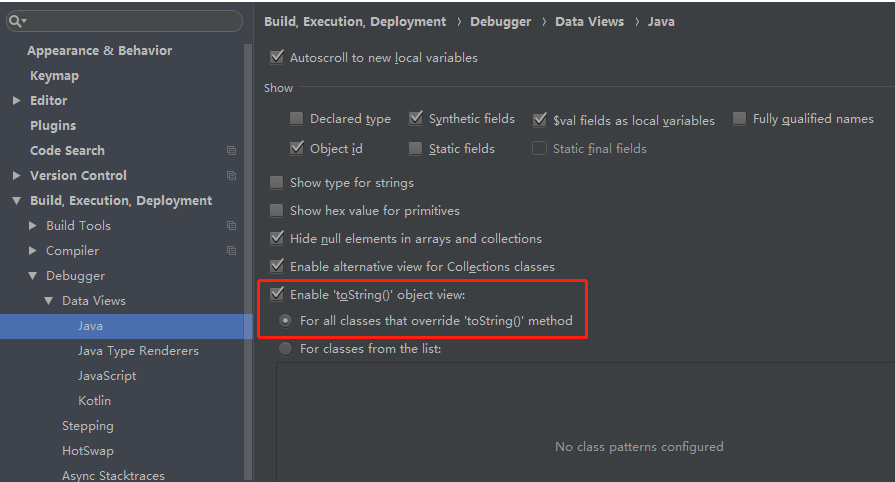
显示为什么调用toString?
通过查看idea--setting--Debugger--java可以看到。
那我们跟进代码后发现在AbstractCollection类中重写了toString方法,代码如下:
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}
刚才不是说会调用toString方法么?那问题来了应该显示一个数组,不应该显示size ?
应该显示一个数组,不应该显示size
在上面的截图中我们可以看到复选框勾选了好几个,其中有个Enable alternative view for Collections classes.好现在我们将这个去掉。看看执行的结果如下图:

通过结果,我们发现现在显示的是数组了。看来Enable alternative view for Collections classes这个选项是专门针对集合来显示的。
如何是懒划分/懒分区
懒划分/懒分区意思就是当我们真正使用的时候才会去划分。下面分析下如何来懒划分的。验证demo如下:
public class Test {
public static void main(String[] args) {
List<String> alist= Lists.newArrayList("12","a","34");
List<List<String>> sList = Lists.partition(alist, 2);
sList.forEach(e -> {
System.out.println(sList);
});
}
}
我们看下forEach的源码如下:
public interface Iterable<T> {
....
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
....
}
看到这里是否有点懵逼。这里套了一层循环,没有显示调用分区呢?这个需要对for循环深入研究才行。我们可以通过简单写一个for循环后查看字节码看看底层到底是如何实现循环的。简单的for循环如下:
public class Test2 {
public static void main(String[] args) {
List<Integer> il = Lists.newArrayList(12,1,3,4);
for (Integer i : il) {}
}
}
通过javap -c Test2.class反解析字节码后如下图:
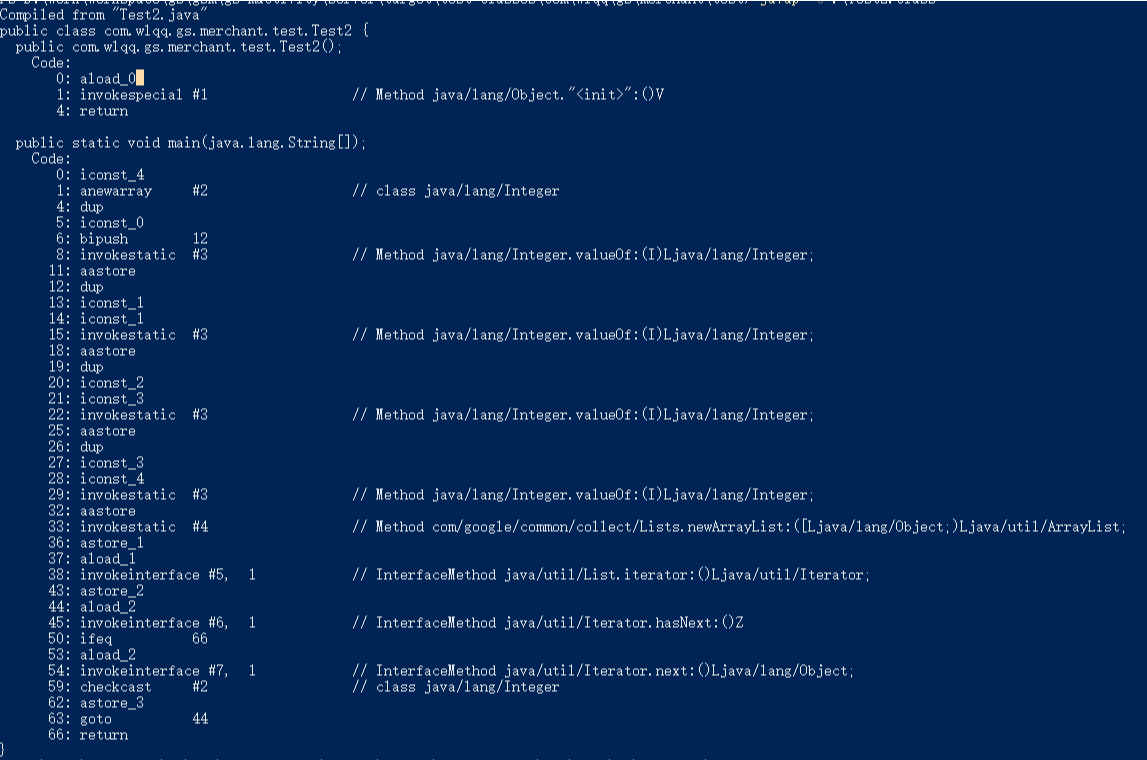
从图中这些关键字信息
38: invokeinterface #5, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
45: invokeinterface #6, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
54: invokeinterface #7, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
这说明了我们for循环底层上还是通过迭代器来实现的。我们也可以看出依次调用iterator()->hasNext()->next()。
从开篇源码看出Guava中Partition的继承关系,发现当底层循环的时候调用iterator()方法是其实是调用AbstractList#iterator()方法,AbstractList#iterator()涉及源码如下
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
public Iterator<E> iterator() {
return new Itr();
}
...
private class Itr implements Iterator<E> {
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
通过上面的源码,发现当调用hasNext()方法的时候会调用size()方法。然size()方法就是我们Guava中这段代码
public int size() {
return IntMath.divide(list.size(), size, RoundingMode.CEILING);
}
当调用next()方法的时候,先是调用子类实现的get(i)方法,子类也就是Guava中这段代码
public List<T> get(int index) {
checkElementIndex(index, size());
int start = index * size;
int end = Math.min(start + size, list.size());
return list.subList(start, end);
}
到此已基本分析完成了。
总结
我们在学习任何知识点的时候都要好好分析,想想,为什么要这样设计?设计的好处是什么?还有就是知识的串联。
比如for 循环。如果不深入研究,你也不知道为啥会调用iterator等一系列的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号