mysql数据结构及mvcc
索引
帮助mysql高效获取数据排好序的数据结构
B-tree
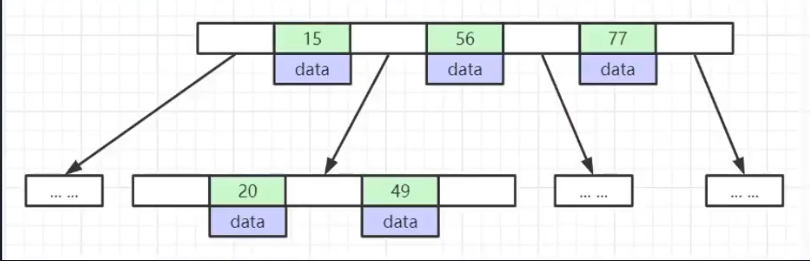
B+-tree mysql主键索引与单列索引
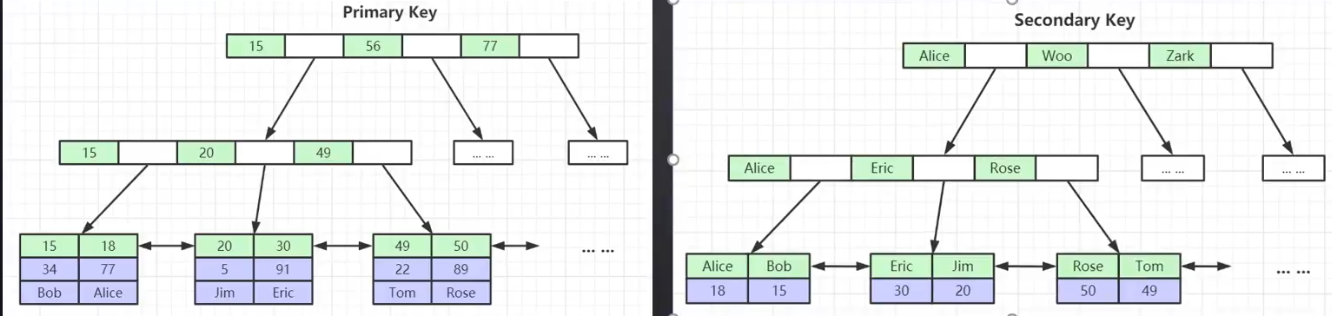
b+-tree增加优化:1.叶子数据节点有指针,范围查询时可以更快。2.数据都放置在最下层叶子节点,上层节点占用空间小,可以有更多分叉,树高度会小,查询更快
联合索引
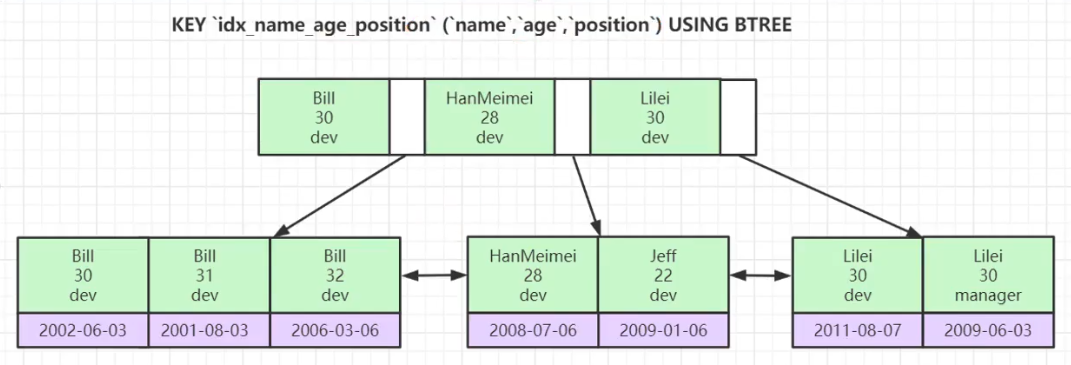
最左匹配原则
MVCC
在使用READ COMMITTD\REPEATABLE READ这两种隔离级别的事务在执行普通的select操作时访问记录的版本链的过程。可以让不同事务的读写、写读操作并发执行,从而提升性能。这两个隔离级别很大不同就是生产READVIEW的实际不同。READ COMMITTD在每次进行普通select操作前会生产readview,而REPEATABLE READ只有在第一次仅限普通select操作前生成readview,之后的查询操作都重复使用第一次生成的readview。
版本链
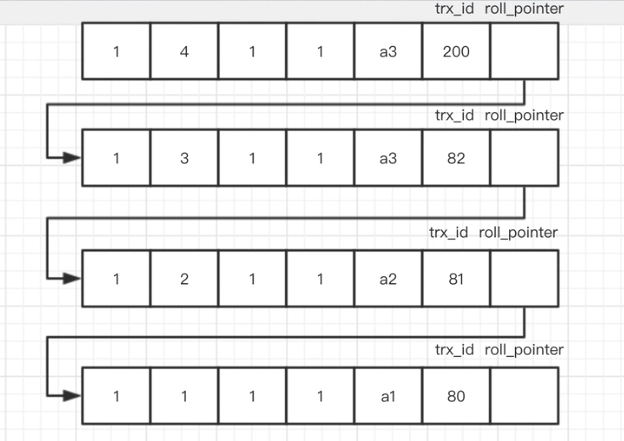
readview
存储事务id
mysql 索引下推
mysql锁
读锁,写锁
READ COMMITTD隔离事务中,只会对写的固定行加锁,其他的行则不会阻塞。
REPEATABLE READ 隔离事务中,会加间隙锁,会对有影响的行加锁。
自己mysql优化过程
配置msyql开启慢查询sql;
拿到sql后使用explain检查sql查看分析结果
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度----长度越短越好
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号