DC综合简单总结(1)
DC综合简单总结(1)
*****************set_dont_touch和set_dont_touch_network****************
?
在综合的过程中,为了不让DC工具自动优化一些我们不希望其优化的模块(比如CLK)我们通常都会设置set_ideal_network和set_dont_touch,我理解为前者在timing_report的时候忽略延迟,后者阻止DC插入buffer。
那么dont_touch的属性,能不能穿过logic?
set_dont_touch和set_dont_touch_network有什么区别,为什么普遍认为set_dont_touch_network会造成未知问题而不推荐使用?
对于ideal_net的这个属性,是不是说直接忽略了延迟,忽略了DRC,如果将clk设定为ideal_net,是不是就不用再设定dont_touch了?
说的有点混乱,请各位大神技术支持,小弟不胜感激!!
=
set_dont_touch不会穿过logic,可以用于cells, nets,
references, 和 designs。你不希望DC碰的地方,都可以用它。
set_dont_touch_network可以穿过logic,可以用于clocks, pins, 或 ports,比上面的范围小。当你对设计不十分熟悉时,这个属性可能会传到你不希望的地方去。
ideal_net 顾名思义就是把这条net完全理想化--无穷大的驱动能力,没有延迟。有时会和上面的命令一起用。当你知道了它们的意思,如何使用取决于你的目的和得到的结果
?
对于Ideal_net这个属性,设置的时候有个no_propagate的属性,对于net来说一定要设这个,是不是就是为了阻止其穿过逻辑?那如果我设的是pin并且不加上no_propagate能穿过逻辑吗?
在建立clock的时候,我看到它会自动的设为ideal_net,但是却还是会计算延迟,会不会因为clock path有逻辑的原因?
=
set_ideal_net =
set_ideal_network -no_propagate
clock net 如果被用作data,就会有delay,那是因为net上面挂的clk pin的负载,不是ideal net本身
?
我大体上明白了,clk在创建的时候,会默认为ideal net的,但当clk接入到data path的时候,D端就会考虑我clk上的负载,但并不会影响clk的ideal net的属性。
假如我的clk需要门电路做gating,gating后的时钟也有很大的扇出,那我为了忽略掉延迟,是不是需要在gating后重新给clk定义ideal net?因为ideal net不能穿过逻辑。
=
如果你的CG集成好的标准单元,它会自动继承ideal的属性。
*****************set_dont_touch和set_dont_touch_network****************
输入端口到时序器件的数据端口。
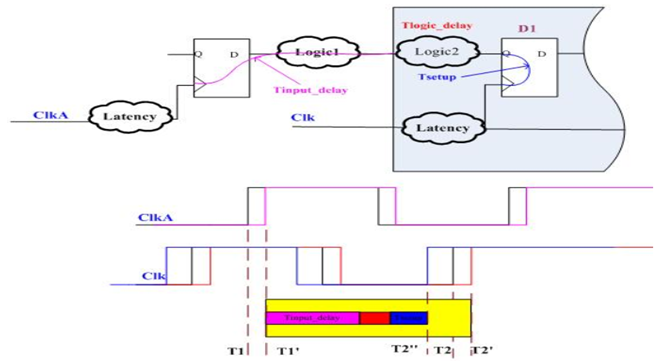
要求时间=T2+Tlatency-Tuncertainty_setup-Tsetup
到达时间=T1+Tlantency+Tinput_delay+Tlogic2
时序器件的输出管脚到输出端口 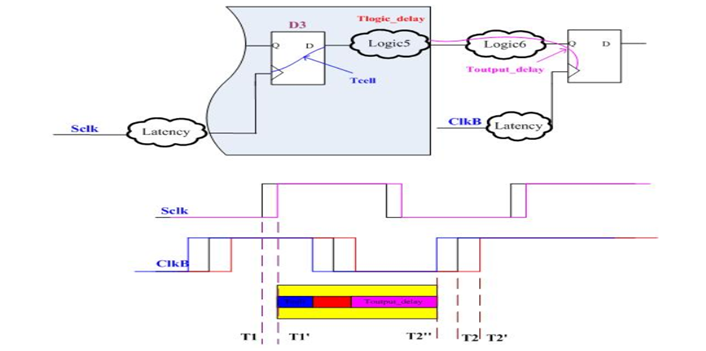
上图中:
要求时间=T2+Tlatency-Toutput_delay-Tuncertainty_setup
到达时间=T1+Tlatency+Tcell+Tlogic5
时序器件到时序器件
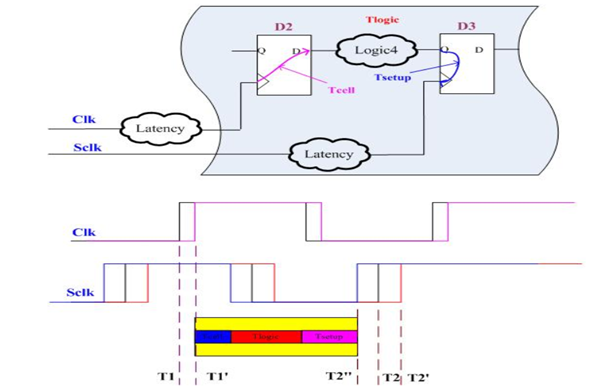
路径上的 cell 延迟由 input_transition 和 output_load(包括扇出 pin 上的 load)决定,这个由查抄表可以得到。
而 net 延迟是由 net 上的 R, C 决定的。在没有布局布线之前,我们不知道实际的 R, C 是多少, dc 根据互联线模型(set_wire_load_model)来计算出 R, C。然后根据得到的 R, C 计算出 net 上的延迟:
Net_delay=R*C*OC
其中系数 OC
是根据操作环境(set_opearting_conditions)中设置的 rc树模型得到。
一般的工艺库的操作环境有三种, WORST, TYPICAL, BEST,分别是最差,典型,最坏。
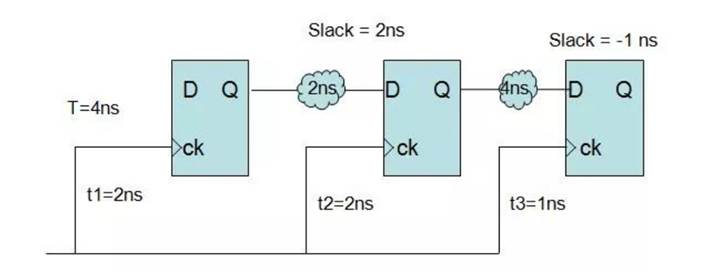
T=4,周期为4,Tdata为2,两个clk同时到达,slack=4-2=2,
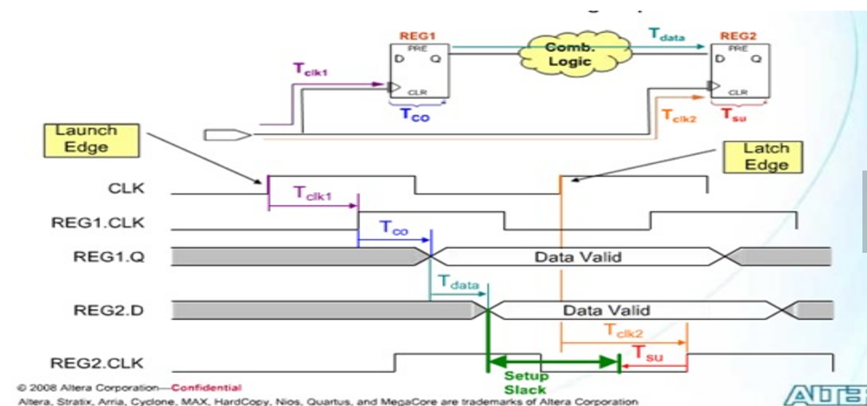
setup check是latch和lauch间隔一个时钟周期,hold check才是在同一个时钟沿
input_transition输入信号的转换时间可以采用两种约束:
1 直接设置转换时间
set_input_transition 0.1 [get_ports A]
2 采用设置输入驱动能力,驱动能力越大,转换时间越小,驱动能力越小,转换时间越大
set_drive或者set_driving_cell
Slew Rate vs. Transition Time
首先,我要说明一下,slew和transition其实并非独立存在使用的词汇。在诸多教材中,一般是以slew rate和transition time,两个词组出现的。
Slew rate,信号改变的速率。
Transition
time,信号改变的持续时间。
在静态时序分析(STA)中,一个上升或者下降的波形通常用slew rate来表征其跳变的快与慢。Transition time就是用来记录这个信号在两个电平之间的转换时间。
这里需要注意的是,transition time实际是slew rate的倒数。Transition time如果越大,那么slew rate就会越慢,反之亦然。
上图展示了一些CMOS器件的输出波形图。理想状态下,我们期望得到一个完美的方波,不过,这显然不够现实。实际上,由于对电容的充放电,一个数字信号的波形往往存在上升和下降的电压缓冲区间。
为了能量化这样的波形,我们近似采用一个线性上升或者下降的信号来模拟真实信号波形。注意到,真实信号波形里,不管是上升还是下降的时候,都会存在一定时间的线性区域。
这个线性区域的起点和终点,可能因为某些估算模型而有所不同。在STA中,我们有时候会采用比较宽松的约束模式,例如20%/80%、10%/90%。
当然,我们也可以采用激进一些的模式,如30%/70%。
在一个线性时序模型里,一个信号经过一个时序单元可能产生两种新的信号波形。
当输出信号的slew rate比输入信号的要快,也就是transition time变短了,说明这个单元对这个信号起到了增强驱动的作用。
反之,当输出信号的slew rate比输入信号还要慢,就是transition time变长了,说明这个单元对这个信号起到了削弱驱动的作用。可能的原因是,这个单元的输出端驱动了较大的负载。
所以,当我们要描述一个信号电平有所变化的时候,记得要用slew rate来表述快慢,用transition time来描述持续时间。
l 对于 cell 的延迟,dc 是根据 input_transition 和 out_load 对应的查找表来计算的。
l 对于 net 的延迟,dc 是根据 wire_load_model 中的fanout_length 和 resistance,capacitance, area 的查找表计算的。
l 负载其实有两个概念,一个是阻性负载,这个负载当你提供了足够的驱动力就能够正确输出,否则电压就不对;另一个是容性负载,这个负载一般在系统里头,和系统能跑到什么速度相关。
一个输出驱动力大的话就能够带更大的负载,从这个意义上说,认为驱动=负载也是可以理解的。但其实这两个概念还是有些区别,侧重点不同。你上面也引用了,“电路的负载能力是下一级的load(即电容)总和”,这都是完全不同的两个量纲,怎么会一样。系统设计上,假设你需要跑10MHz的频率,你需要10mA的驱动力,则同一个容性负载上,要跑到20MHz的频率,你就需要20mA的驱动力。
l 对于Fanout 的理解
Fanout,即扇出,指模块直接调用的下级模块的个数,如果这个数值过大的话,在FPGA直接表现为net delay较大,不利于时序收敛。因此,在写代码时应尽量避免高扇出的情况。
https://www.cnblogs.com/aikimi7/p/5945822.html
综上,在遇到信号高扇出时,对于普通信号可采用
1.寄存器复制或者2.设置max_fanout属性优化;而3.对于复位信号,可加入BUFG优化。
寄存器复制是解决高扇出问题最常用的方法之一,通过复制几个相同的寄存器来分担由原先一个寄存器驱动所有模块的任务,继而达到减小扇出的目的。通过简单修改代码,如图3所示,复制了4个寄存器:din_d0、din_d1、din_d2、din_d3,din_d、din_d0、din_d1、din_d2分别驱动2个DSP48E1,din_d3驱动3个DSP48E1。其中在代码中为防止综合器优化相同寄存器,在对应信号上加入了(* EQUIVALENT_REGISTER_REMOVAL="NO" *)属性避免被优化。

综合实现后得到时序报告如图4所示,该数据路径上输入数据fanout减为2,对应net delay也减小到了0.57ns。得到设计如图5所示,与期望的相同,复制了4个寄存器来分担fanout。在没有优化情况下,该设计的fmax:206.016MHz,经过寄存器优化后得到fmax:252.143MHz.
2. max_fanout属性
在代码中可以设置信号属性,将对应信号的max_fanout属性设置成一个合理的值,当实际的设计中该信号的fanout超过了这个值,综合器就会自动对该信号采用优化手段,常用的手段其实就是寄存器复制。属性设置如下代码所示:
(* max_fanout = "3" *)reg signed [15:0] din_d;
将din_d信号的max_fanout属性设置成3,经过综合实现后,得到时序报告如图6所示,其中fanout只有2,相应的net delay也只有0.61ns,自动优化效果还不错。结构如图7所示,其中din_d_12_1、din_d_12_2、din_d_12_3是综合器优化后自动添加,即实现了寄存器复制功能。经过设置max_fanout属性优化后得到fmax:257.135MHz
3. BUFG
通常BUFG是用于全局时钟的资源,可以解决信号因为高扇出产生的问题。但是其一般用于时钟或者复位之类扇出超级大的信号,此类信号涉及的逻辑遍布整个芯片,而BUFG可以从全局的角度优化布线。而且一块FPGA芯片中BUFG资源也有限,在7k325tffg900上也仅有32个,如果用于普通信号的高扇出优化也不大现实。因此,在时钟上使用BUFG是必须的,但是如果设计中遇到某些复位信号因高扇出产生的时序问题时,可以在此信号上使用BUFG来优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号