Flink SQL结合Kafka、Elasticsearch、Kibana实时分析电商用户行为
使用Flink SQL结合Kafka、Elasticsearch、Kibana实时分析电商用户行为 (Use flink sql to combine kafka, elasticsearch and kibana, real-time analysis of e-commerce user behavior.)
Flink与其它实时计算工具区别之一是向用户提供了更多抽象易用的API,比如读写各类程序的connector接口、Table API和SQL,从数据加载、计算、一直到输出,所有操作都可以使用SQL完成,大大减少了开发量和维护成本,本文将通过实时分析电商用户行为数据介绍flink sql的使用,分析的内容如下:
- 分析每10分钟累计在线用户数;
- 分析每小时购买量;
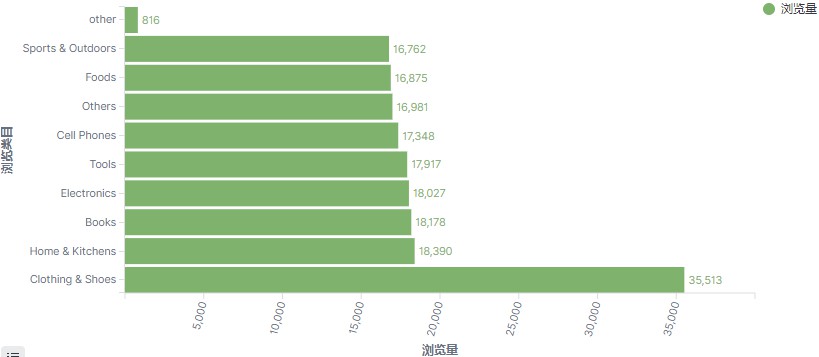
- 分析top浏览商品类目(浏览的商品归属于那个类目);
1 最终实时分析kibana展现效果
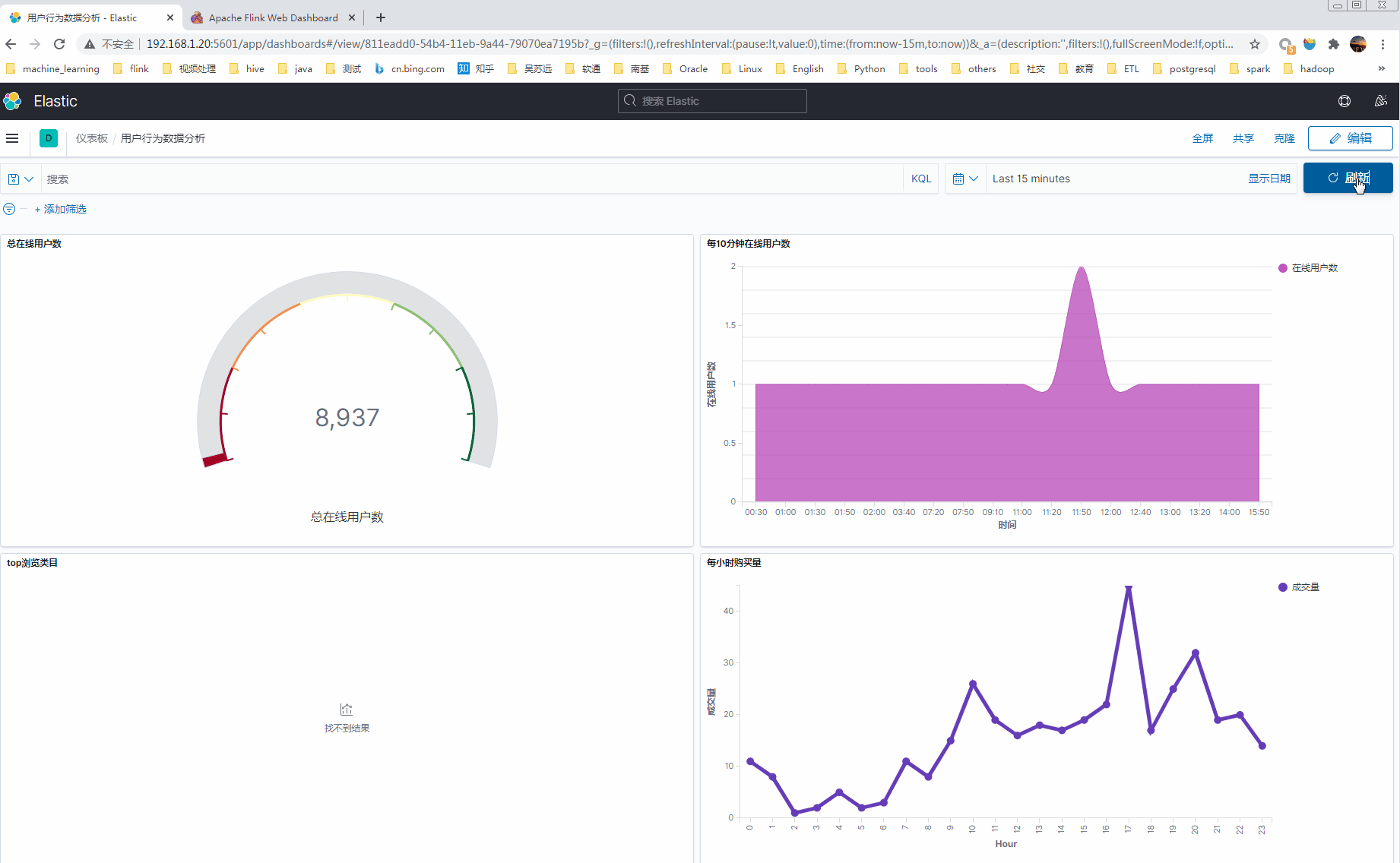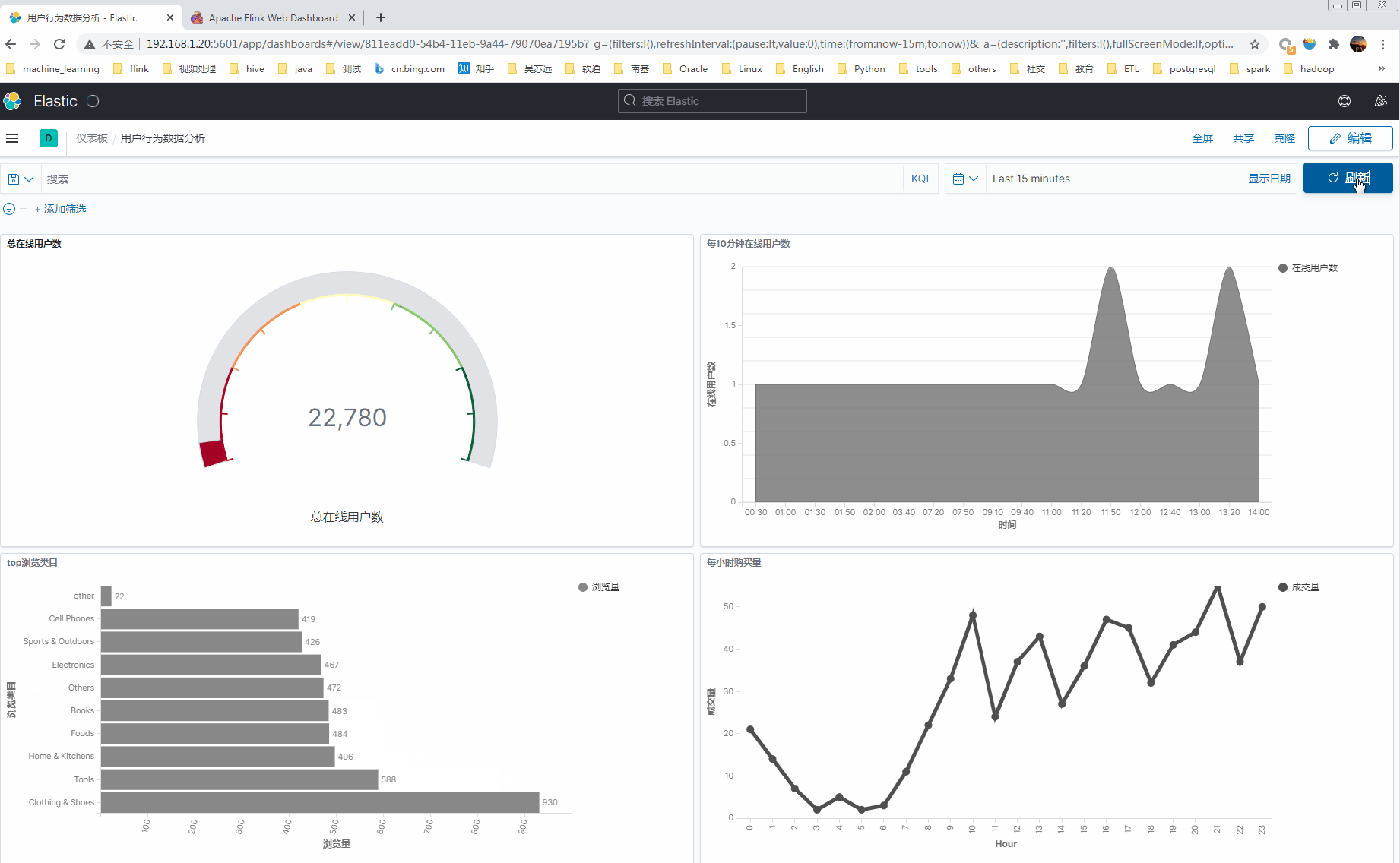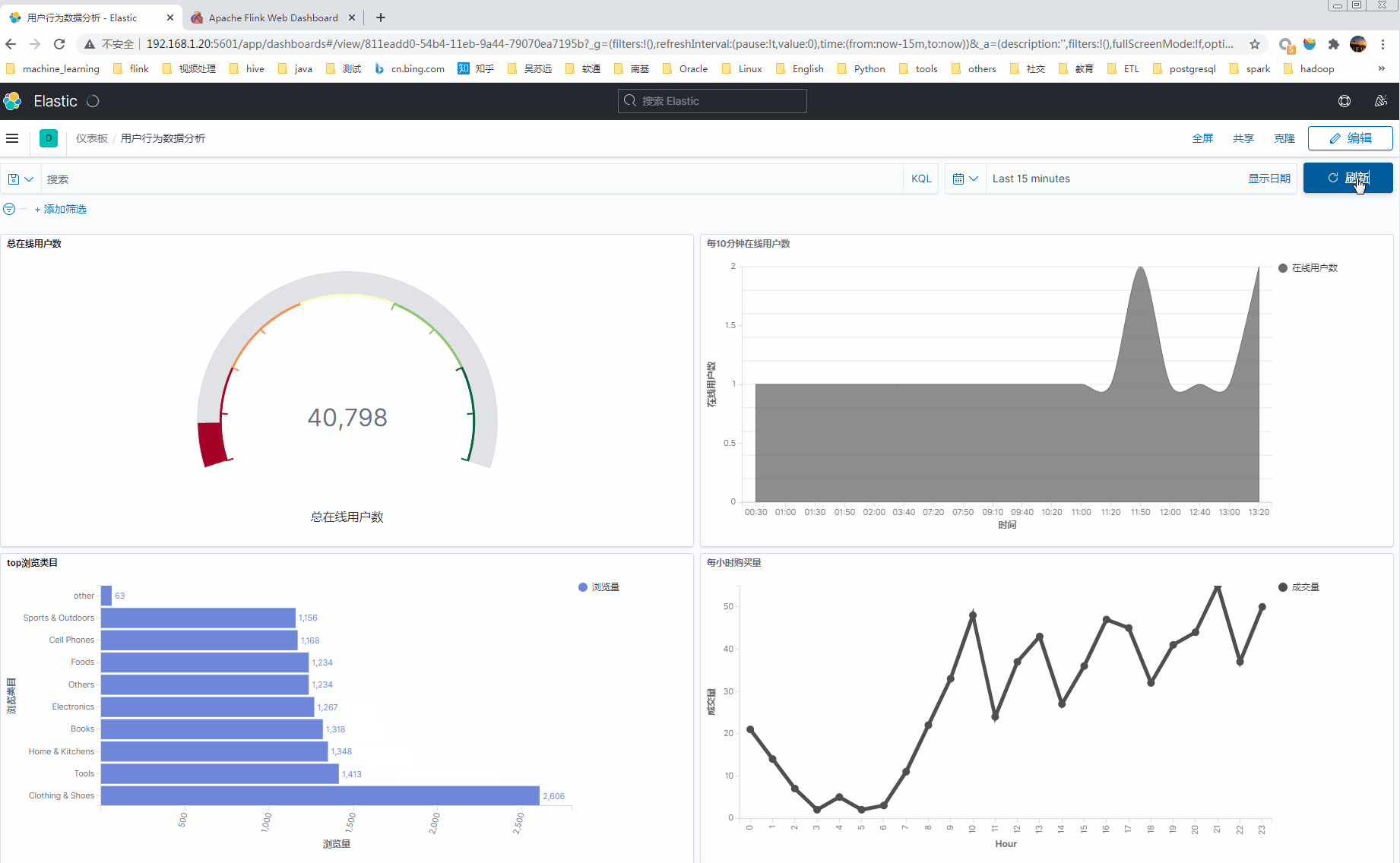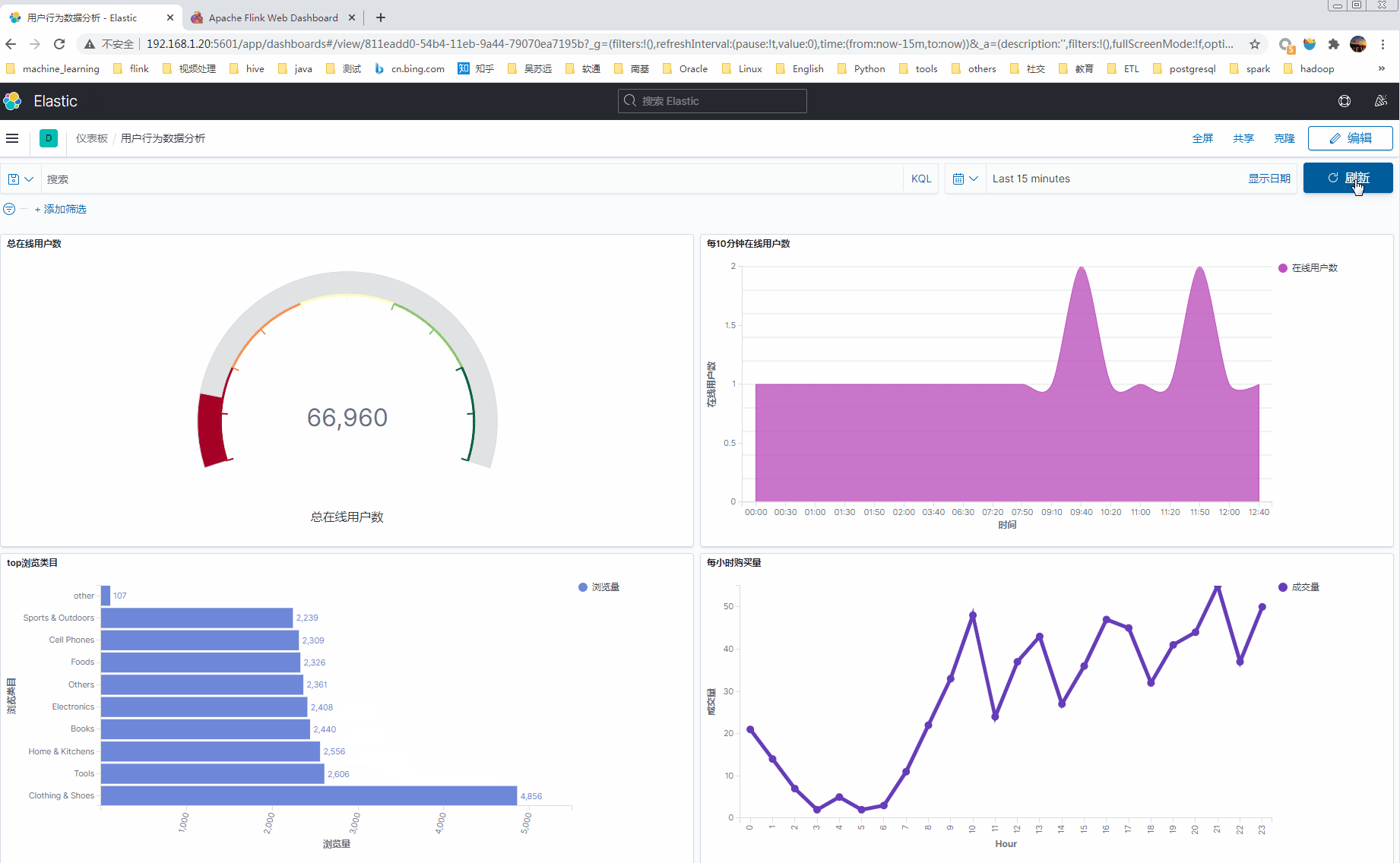
2 流程和版本信息
- kafka --> flink --> es -->kibana
数据采集存储到kafka,通过flink消费kafka数据,实时计算,结果存储到es,最后通过kibana展现。
版本信息
flink 1.12.1、kafka_2.13-2.7.0、elasticsearch 7.10.1、kibana 7.10.1
3 数据结构
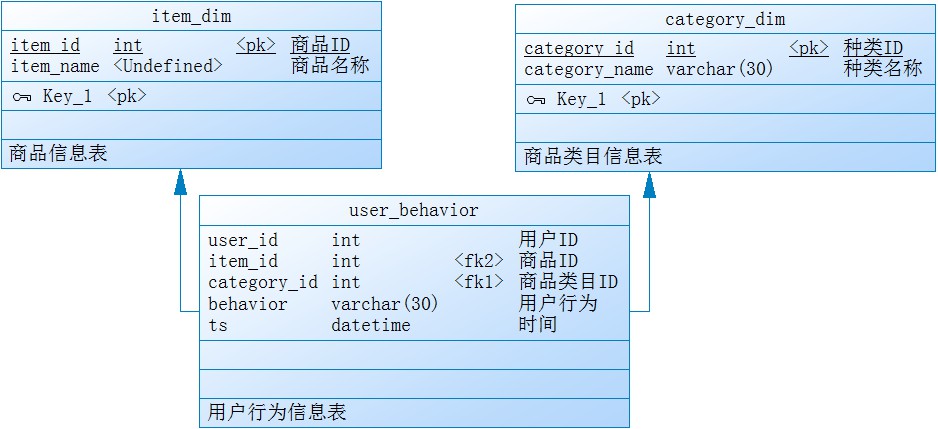
电商用户行为分析共涉及3个表,商品类目信息表、商品类目信息表、用户行为信息表,其中用户行为信息表共5个列:用户ID、商品ID、商品类目ID、行为类型、时间戳;
4 kafka数据
./kafka-console-consumer.sh --topic user_behavior --bootstrap-server kafka:9092 --from-beginning --max-messages 5
1,2268318,2520377,pv,1511544070
1,2333346,2520771,pv,1511561733
数据来源于淘宝开放的用户行为数据UserBehavior,数据格式为csv,以逗号分隔;
2 使用Flink SQL建表读取kafka数据
现在数据已经存储在kafka,进入flink sql client,

创建消费kafka数据表;
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
app_time BIGINT,
ts AS TO_TIMESTAMP(FROM_UNIXTIME(app_time, 'yyyy-MM-dd HH:mm:ss')),
proctime AS PROCTIME(),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka', --使用kafka connector
'topic' = 'user_behavior', --kafka topic
'scan.startup.mode' = 'earliest-offset', --从topic最开始处开始消费
'properties.bootstrap.servers'='localhost:9092', --kafka broker地址
'properties.group.id' = 'test-group03',
'format' = 'csv', --存储在kafka的数据格式为csv
'csv.field-delimiter'=',' --数据分隔符
);
- WATERMARK 定义处理混乱次序的事件时间属性,每5秒触发一次window
- PROCTIME 是内置函数,产生一个虚拟的Processing Time列,偶尔会用到
- WITH 里定义kafka连接信息和属性
- 由于事件时间格式为bigint,在sql中将其转为timestamp
3 分析场景
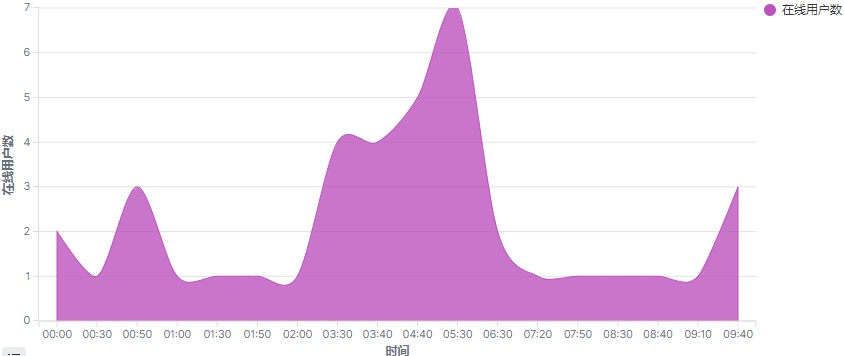
3.1 场景1:分析每10分钟累计在线用户数
最终的分析结果数据会写入es,首先创建es index和写入es的表;
CREATE TABLE cumulative_uv (
date_str STRING,
time_str STRING,
uv BIGINT,
PRIMARY KEY (date_str, time_str) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'cumulative_uv'
);
- WITH 里面定义es连接信息和属性
分析每10分钟在线用户数只需要知道日期(date_str)、时间(time_str)、数量(uv)即可;上面已经定义了消费kafka数据的表 user_behavior,现在查询该表,并将数据写入es;
INSERT INTO
cumulative_uv
SELECT
date_str, MAX(time_str), COUNT(DISTINCT user_id) as uv
FROM (
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd') as date_str,
SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0' as time_str,
user_id
FROM user_behavior)
GROUP BY
date_str;
由于分析跨度为每10分钟,在sql 内层查询中使用 SUBSTR 截取事件小时和分钟字符,拼凑成每10分钟的数据,比如: 12:10,12:20。提交sql后,flink会将sql以流作业方式按照设定的WATERMARK和窗口提交到集群运行;
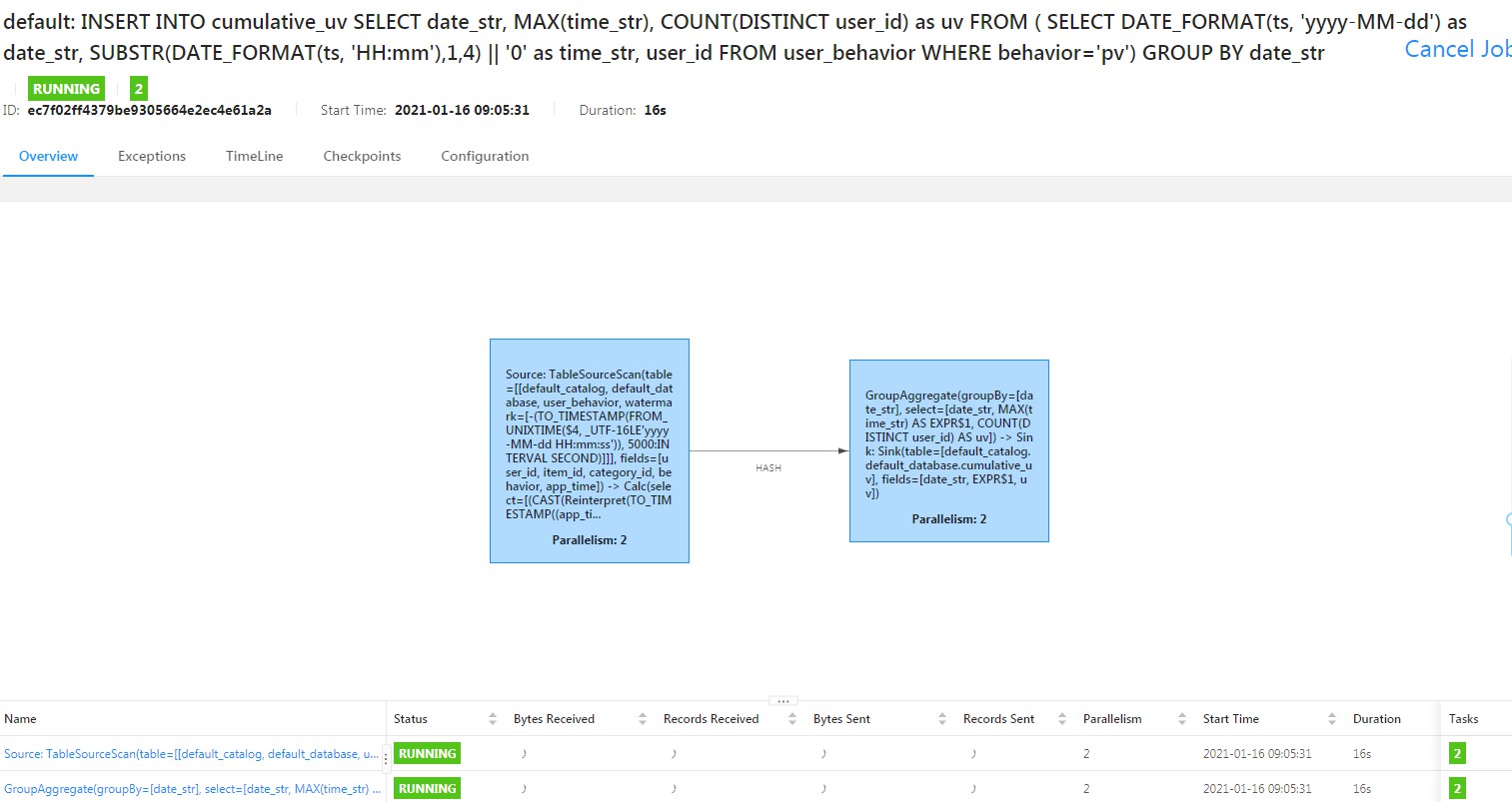
现在查询kibina可以看到数据已经实时写入.
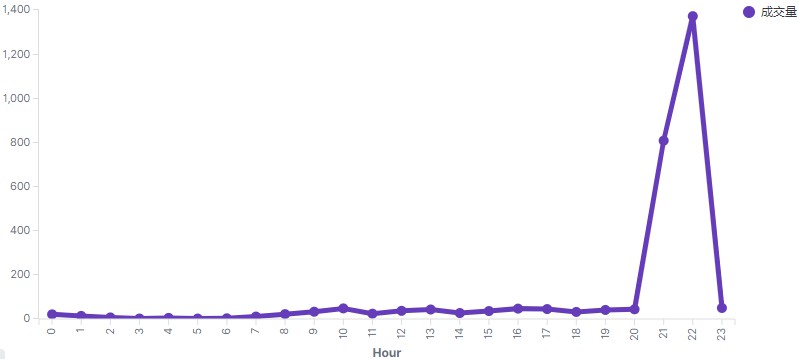
3.2 场景2:分析每小时购买量
创建es index和写入es的表;
CREATE TABLE buy_cnt_per_hour (
hour_of_day BIGINT,
buy_cnt BIGINT
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'buy_cnt_per_hour'
);
查询 user_behavior 表,将数据写入es;
INSERT INTO
buy_cnt_per_hour
SELECT
HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM
user_behavior
WHERE
behavior='buy'
GROUP BY
TUMBLE(ts, INTERVAL '1' HOUR);
- HOUR 为内置函数,从一个 TIMESTAMP 列中提取出一天中第几个小时的值
- TUMBLE 为窗口函数,按设定的时间切窗
首先通过(behavior='buy') 过滤出购买数据,再通过窗口函数(TUMBLE)按一小时切窗,统计出每小时共有多少"buy"的用户行为。
3.3 场景3:分析top浏览商品类目
由于kafka数据存储的是商品id,商品id对应的商品类目名称存储在mysql数据库,需先创建连接mysql的数据表;
CREATE TABLE category (
category_id BIGINT,
category_name STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/test',
'table-name' = 'category',
'username' = 'sywu',
'password' = 'sywu',
'lookup.cache.max-rows' = '5000',
'lookup.cache.ttl' = '10min'
);
为了后续查询方便,创建kafka数据表和mysql数据表关联视图;
CREATE VIEW rich_user_behavior
AS
SELECT
U.user_id, U.item_id, U.behavior, case when C.category_name is null then 'other' else C.category_name end as category_name
FROM
user_behavior AS U LEFT JOIN category FOR SYSTEM_TIME AS OF U.proctime AS C
ON
U.category_id = C.category_id;
现在 kafka 数据表和 mysql数据表通过视图表 rich_user_behavior 关联在一起;分析top浏览商品类目只需要知道商品类目名和浏览数即可,所以在此创建一张包含商品类目名和浏览数的表;
CREATE TABLE top_category (
category_name STRING PRIMARY KEY NOT ENFORCED,
buy_cnt BIGINT
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'top_category'
);
查询视图表 rich_user_behavior表,过滤分组统计数据;
INSERT INTO
top_category
SELECT
category_name, COUNT(*) buy_cnt
FROM
rich_user_behavior
WHERE
behavior='buy'
GROUP BY
category_name;
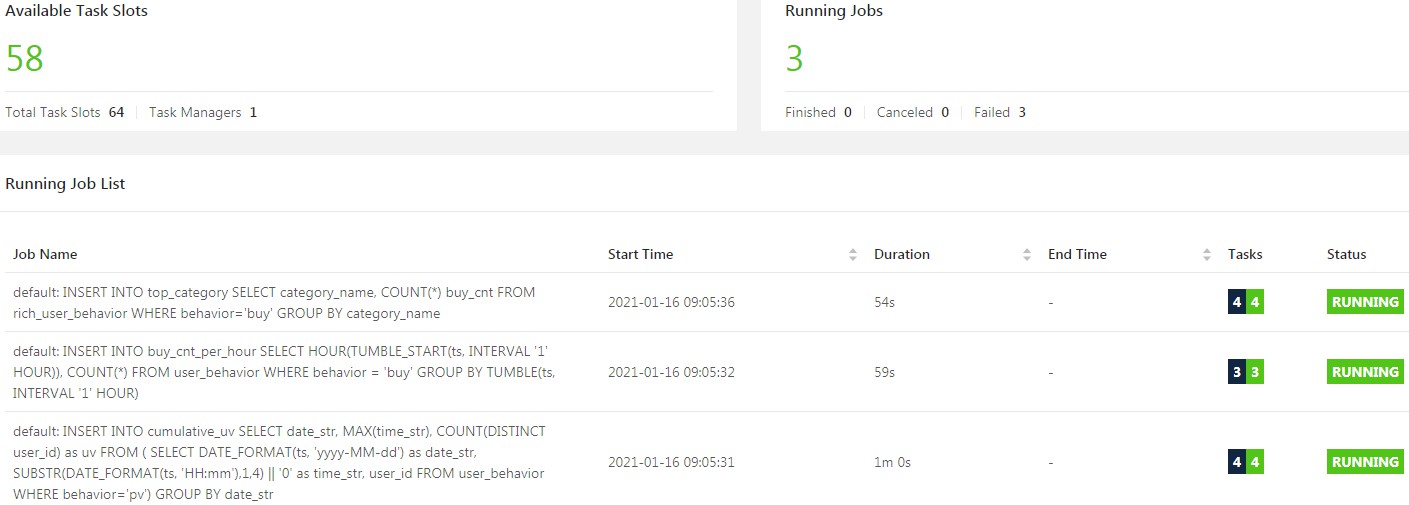
到此3个分析需求实现,作业正常实时运行。
4 总结
通过Flink 提供的Table API和SQL,以及处理数据的窗口、读写各类程序的connector接口和函数,使用上面的SQL DML操作,flink即实现了用户行为数据的实时分析需求;从开发角度看,代码量和开发难度大大降低;从维护角度看,维护成本也大大降低。
参考文献
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/ - Table API & SQL
- https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/sql/queries.html#group-windows - flink group windows
- https://tianchi.aliyun.com/dataset/dataDetail?dataId=649 - taobao UserBehavior

 浙公网安备 33010602011771号
浙公网安备 33010602011771号