Es学习笔记
 es学习笔记,主要介绍安装环境以及es相关概念学习笔记,以及基本的建库与新增数据与查询数据,es脑图总结分享等
es学习笔记,主要介绍安装环境以及es相关概念学习笔记,以及基本的建库与新增数据与查询数据,es脑图总结分享等
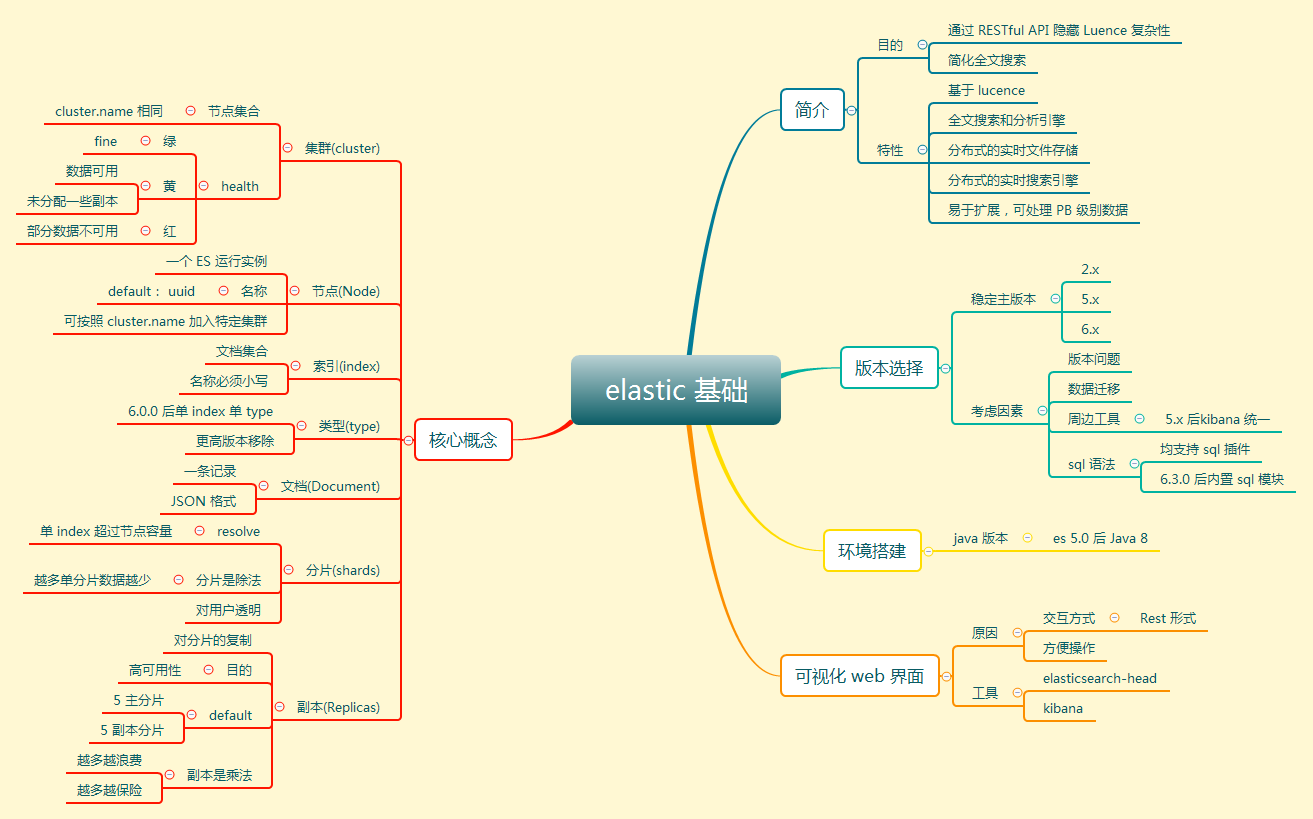
简介
Elasticsearch是一个高度可扩展的、开源的、基于 Lucene 的全文搜索和分析引擎。它允许您快速,近实时地存储,搜索和分析大量数据,并支持多租户。
Elasticsearch也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch 不仅仅是 Lucene 和全文搜索,我们还能这样去描述它:
1、分布式的实时文件存储,每个字段都被索引并可被搜索
2、分布式的实时分析搜索引擎
3、可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。

环境搭建
Elasticsearch5.0之后的版本至少需要Java 8。可通过如下命令检查Java版本,然后根据需要进行相应的安装/升级。
java -version
我们从 elastic.co/download 下载需要的版本的Elasticsearch,解压之后即可使用,我是下载的7.8.1版本的es,因为我现在公司采用的就是这个版本,下载该版本便于我学习并应用到工作。
目前,es官方已经更新到8.5.2版本了,关于es版本的选择可以从以下几个方面考虑:
稳定性
Elasticsearch 目前有三个常用的稳定的主版本:2.x,5.x,6.x,7.x(排除 0.x 和 1.x)
2.x 版本较老,无法体验新功能,且性能不如 5.x。
6.x 版本有点新,网上资料相对比较少(开发时间充足的可以研究)。
数据迁移
2.x 版本数据可以直接迁移到 5.x;
5.X 版本的数据可以直接迁移到 6.x; 但是 2.x 版本数据无法直接迁移到 6.x。
周边工具
2.x 版本周边工具版本比较混乱;Kibana 等工具的对应版本需要自己查,不好匹配。
5.x 之后 Kibana 等工具的主版本号进行了统一。
Sql 语法支持
2.x,5.x,6.x,7.x,8.x都可以安装 Elasticsearch-sql 插件,使用熟悉的SQL语法查询 Elasticsearch。
6.3.0 以后内置支持 SQL 模块,这个 SQL 模块是属于 X-Pack 的一部分。
如果是集群形式的,可在 ...\elasticsearch-7.8.1\config\elasticsearch.yml中配置一些你的集群信息:
cluster.name: my-application # 集群名称
path.data: /path/to/data # ES数据存储路径
path.logs: /path/to/logs # ES日志存储路径
node.name: node-1 # 当前节点的名称
network.host: 192.168.0.1 # 配置当前结点绑定的IP地址,可设置为0.0.0.0
http.port: 9200 # 设置对外服务的HTTP端口,默认为9200
运行 Elasticsearch
elasticsearch 准备好之后,在安装目录中执行以下命令可以启动运行:
Linux环境
./bin/elasticsearch
Windows环境
D:\...\elasticsearch-7.8.1\bin\elasticsearch.bat
运行成功之后(启动日志里面会有.. started标志),浏览器访问http://localhost:9200/?pretty,你能看到类似以下返回信息(各版本稍微不同):
{
"name" : "AGXQ3qy",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "mg9t4Yi2TRud1JNwRY0bPA",
"version" : {
"number" : "7.8.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "595516e",
"build_date" : "2022-12-18T14:18:47.308994Z",
"build_snapshot" : false,
"lucene_version" : "7.4.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
这说明你的 Elasticsearch 集群已经启动成功并且正常运行,接下来我们可以开始使用了。
至此,环境安装完毕,下面就是开始了解一下ES的基本概念
基本概念
Elasticsearch是一个近乎实时(NRT)的搜索平台。这意味着从索引文档到可搜索文档的时间有一点延迟(通常是一秒)。通常有集群,节点,分片,副本等概念。
集群(Cluster)
集群(cluster)是一组具有相同cluster.name的节点集合,他们协同工作,共享数据并提供故障转移和扩展功能,当然一个节点也可以组成一个集群。
集群由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入集群的话,则该节点只能是集群的一部分。
确保不同的环境中使用不同的集群名称,否则最终会导致节点加入错误的集群。
【集群健康状态】
集群状态通过 绿,黄,红 来标识
绿色 - 一切都很好(集群功能齐全)。
黄色 - 所有数据均可用,但尚未分配一些副本(集群功能齐全)。
红色 - 某些数据由于某种原因不可用(集群部分功能)。
注意:当群集为红色时,它将继续提供来自可用分片的搜索请求,但您可能需要尽快修复它,因为存在未分配的分片。
要检查群集运行状况,我们可以在 Kibana 控制台中运行以下命令GET /_cluster/health,得到如下信息:
{
"cluster_name": "elasticsearch",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 28,
"active_shards": 28,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 5,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 84.84848484848484
}
节点(Node)
节点,一个运行的 ES 实例就是一个节点,节点存储数据并参与集群的索引和搜索功能。
就像集群一样,节点由名称标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符(UUID)。如果不需要默认值,可以定义所需的任何节点名称。此名称对于管理目的非常重要,您可以在其中识别网络中哪些服务器与 Elasticsearch 集群中的哪些节点相对应。
可以将节点配置为按集群名称加入特定集群。默认情况下,每个节点都设置为加入一个名为 cluster 的 elasticsearch 集群,这意味着如果您在网络上启动了许多节点并且假设它们可以相互发现 - 它们将自动形成并加入一个名为 elasticsearch 的集群。
索引(Index)
索引是具有某些类似特征的文档集合。例如,您可以拥有店铺数据的索引,商品的一个索引以及订单数据的一个索引。
索引由名称标识(必须全部小写),此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。
类型(Type)
类型,曾经是索引的逻辑类别/分区,允许您在同一索引中存储不同类型的文档。
在 6.0.0 中弃用,以后将不再可能在索引中创建多个类型,并且将在更高版本中删除类型的整个概念。
文档(Document)
文档是可以建立索引的基本信息单元。例如,您可以为单个客户提供文档,为单个产品提供一个文档,为单个订单提供一个文档。该文档以JSON(JavaScript Object Notation)表示,JSON是一种普遍存在的互联网数据交换格式。
在索引/类型中,您可以根据需要存储任意数量的文档。请注意,尽管文档实际上驻留在索引中,但实际上必须将文档编入索引/分配给索引中的类型。
分片(Shards)
索引可能存储大量可能超过单个节点的硬件限制的数据。例如,占用1TB磁盘空间的十亿个文档的单个索引可能不适合单个节点的磁盘,或者可能太慢而无法单独从单个节点提供搜索请求。
为了解决这个问题,Elasticsearch 提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
设置分片的目的及原因主要是:
它允许您水平拆分/缩放内容量
它允许您跨分片(可能在多个节点上)分布和并行化操作,从而提高性能/吞吐量
分片的分布方式以及如何将其文档聚合回搜索请求的机制完全由 Elasticsearch 管理,对用户而言是透明的。
在可能随时发生故障的网络/云环境中,分片非常有用,建议使用故障转移机制,以防分片/节点以某种方式脱机或因任何原因消失。为此,Elasticsearch 允许您将索引的分片的一个或多个副本制作成所谓的副本分片或简称副本。
副本(Replicasedit)
副本,是对分片的复制。目的是为了当分片/节点发生故障时提供高可用性,它允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,每个索引可以拆分为多个分片。索引也可以复制为零次(表示没有副本)或更多次。复制之后,每个索引将具有主分片(从原始分片复制而来的)和复制分片(主分片的副本)。
可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您也可以随时动态更改副本数。您可以使用_shrink 和 _splitAPI 更改现有索引的分片数,但这不是一项轻松的任务,所以预先计划正确数量的分片是最佳方法。
默认情况下,Elasticsearch 中的每个索引都分配了5个主分片和1个副本,这意味着如果集群中至少有两个节点,则索引将包含5个主分片和另外5个副本分片(1个完整副本),总计为每个索引10个分片。
小结
我们假设有一个集群由三个节点组成(Node1 , Node2 , Node3)。 它有两个主分片(P0 , P1),每个主分片有两个副本分片(R0 , R1)。相同分片的副本不会放在同一节点,所以我们的集群看起来如下图所示 “有三个节点和一个索引的集群”。
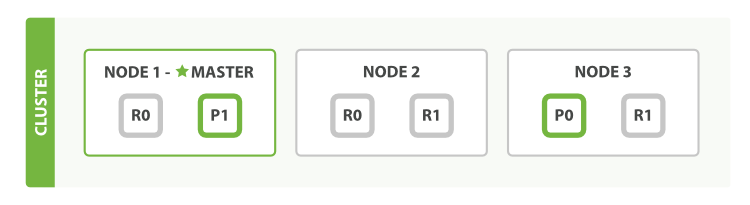
类似于关系型数据库:数据库集群,假如有个用户表,我担心数据量过大,我新建了多个用户表(即 Shard),将用户信息数据切分成多份,然后根据某种规则分到这些用户表中,我又担心某个表会出现异常造成数据丢失,我又将每个表分别备份了一次(即 Replica )。
副本是乘法,越多越浪费,但也越保险。分片是除法,分片越多,单分片数据就越少也越分散。
我们可以画一个对比图来类比传统关系型数据库:
关系型数据库 -> Databases(库) -> Tables(表) -> Rows(行) -> Columns(列)。
Elasticsearch -> Indeces(索引) -> Types(类型) -> Documents(文档) -> Fields(属性)。
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型 (Types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
索引(index)这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分:
「索引」含义的区分
索引(名词) 如上文所述,一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是 indices 或 indexes。
索引(动词) 「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。
与Elasticsearch交互
目前与 elasticsearch 交互主要有两种方式:Client API 和 RESTful API。
Client API方式:
Elasticsearch 为以下语言提供了官方客户端 --Groovy、JavaScript、.NET、 PHP、 Perl、 Python 和 Ruby--还有很多社区提供的客户端和插件,所有这些都可以在 Elasticsearch Clients 中找到。后面再开一篇来详细说明。
RESTful API with JSON over HTTP:
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。事实上,正如你所看到的,你甚至可以使用 curl 命令来和 Elasticsearch 交互。
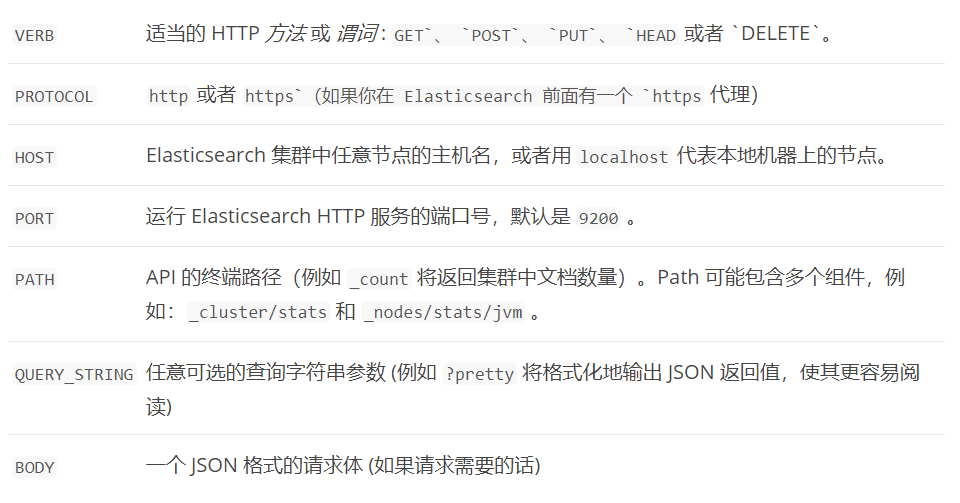
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
被< >标记的部件:
数据格式
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。几乎所有的语言都有相应的模块可以将任意的数据结构或对象 转化成 JSON 格式,只是细节各不相同。
Elasticsearch 是面向文档的,意味着它存储整个对象或文档。Elasticsearch 不仅存储文档,而且 每个文档的内容可以被检索。在 Elasticsearch 中,你对文档进行索引、检索、排序和过滤而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
索引的应用
GET _search
{
"query": {
"match_all": {}
}
}
得到如下结果信息:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": ".kibana",
"_type": "config",
"_id": "5.6.0",
"_score": 1,
"_source": {
"buildNum": 15523
}
}
]
}
}
可以发现,当前只有一个索引,是.kibana,当然这不是我们自己的,这是kibana的。
PS: 以下测试均在postman内进行测试,使用如下:
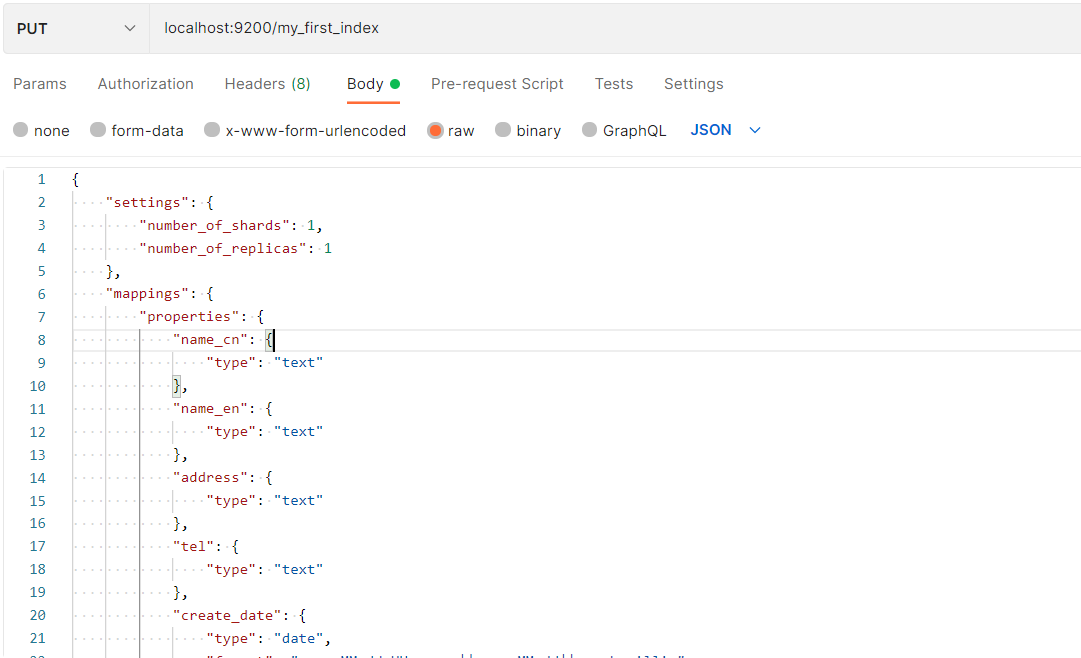
创建第一个索引库
PUT请求
localhost:9200/my_first_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name_cn": {
"type": "text"
},
"name_en": {
"type": "text"
},
"address": {
"type": "text"
},
"tel": {
"type": "text"
},
"create_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss|| yyy-MM-dd||epoch_millis"
}
}
}
}
字段说明
| 字段名称 | 字段说明 |
|---|---|
| my_first_index | 索引 |
| number_of_shards | 分片数 |
| number_of_replicas | 副本数 |
| name_cn | 测试中文名 |
| name_en | 测试英文名 |
| address | 地址 |
| tel | 电话号码 |
| date | 创建日期 |
如果格式书写正确,我们会得到如下返回信息,表示创建成功
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_first_index"
}
插入测试数据
不指定id插入
POST请求
http://127.0.0.1:9200/my_first_index/_doc
{
"name_en":"蓝闪一号",
"name_cn":"lanshan one",
"address":"中国南京",
"tel": "17888888888",
"date":"2022-12-18"
}
结果返回
{
"_index": "my_first_index",
"_type": "_doc",
"_id": "xXAlJIUB4RUIXK6QgpAN",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
索引创建完成之后,我们往索引中加入数据,不写ID,ES 会默认ID,_id为xXAlJIUB4RUIXK6QgpAN
指定id插入
POST请求
http://127.0.0.1:9200/my_first_index/_doc/2
{
"name_en":"蓝闪二号",
"name_cn":"lanshan two",
"address":"中国南京",
"tel": "17888888888",
"date":"2022-12-18"
}
返回结果
{
"_index": "my_first_index",
"_type": "_doc",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
可以看到,_id此时就是我们指定的值2。
查询索引数据
下面我们来查询一下刚才插入的测试数据
GET请求
http://127.0.0.1:9200/my_first_index/_search
返回结果
{
"took": 142,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_first_index",
"_type": "_doc",
"_id": "xXAlJIUB4RUIXK6QgpAN",
"_score": 1.0,
"_source": {
"name_en": "蓝闪一号",
"name_cn": "lanshan one",
"address": "中国南京",
"tel": "17888888888",
"date": "2022-12-18"
}
},
{
"_index": "my_first_index",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"name_en": "蓝闪二号",
"name_cn": "lanshan two",
"address": "中国南京",
"tel": "17888888888",
"date": "2022-12-18"
}
}
]
}
}
响应的数据结果分为两部分
{
----------------first part--------------------
"took": 0,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
---------------second part---------------------
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
第一部分为:分片副本信息,第二部分 hits 包装的为查询的数据集。
注意:响应内容不仅会告诉我们哪些文档被匹配到,而且这些文档内容完整的被包含在其中—我们在给用户展示搜 索结果时需要用到的所有信息都有了。
小结
本次学习笔记暂时写到这里,后续将再出篇幅总结详细介绍ES查询相关。
下附一张在其他博客文章学习到的es脑图,感觉总结的挺好的,与君共享。