

Hashmap扩容时死循环问题
hashmap扩容时死循环问题
源码如下 ——–Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//计算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//各种校验吧
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}这里添加一个节点需要检查是否超出容量,出现了一个负载因子。
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize(2 * table.length);//扩容都是2倍2倍的来的,
}
1.奇数不行的解释很能被接受,在计算hash的时候,确定落在数组的位置的时候,计算方法是(n - 1) & hash ,奇数n-1为偶数,偶数2进制的结尾都是0,经过&运算末尾都是0,会 增加hash冲突。
2.为啥要是2的幂,不能是2的倍数么,比如6,10? 2.1 hashmap 结构是数组,每个数组里面的结构是node(链表或红黑树),正常情况下,如果你想放数据到不同的位置,肯定会想到取余数确定放在那个数据里,
计算公式: hash % n,这个是十进制计算。在计算机中, (n - 1) & hash,当n为2次幂时,会满足一个公式:(n - 1) & hash = hash % n,计算更加高效。
2.2 只有是2的幂数的数字经过n-1之后,二进制肯定是 ...11111111 这样的格式,这种格式计算的位置的时候,完全是由产生的hash值类决定,而不受n-1(组数长度) 影响。
你可能会想, 受影响不是更好么,又计算了一下,类似于扰动函数,hash冲突可能更低了,这里要考虑到扩容了,2的幂次方*2,在二进制中比如4和8,代表2的2次方和3次方,他们的2进制结构相 似,
比如 4和8 00000100 0000 1000 只是高位向前移了一位,这样扩容的时候,只需要判断高位hash,移动到之前位置的倍数就可以了,免去了重新计算位置的运算。
既然新建了一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}好,重点在这里面的transfer()!
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}假设有一个hashMap数组(正常是2的N次长度,这里方便举例), 节点3上存有abc元素,此时发生扩容
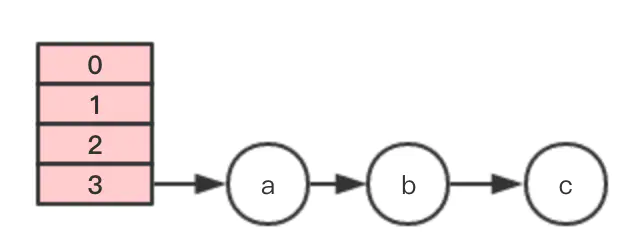
此时假设有两个线程
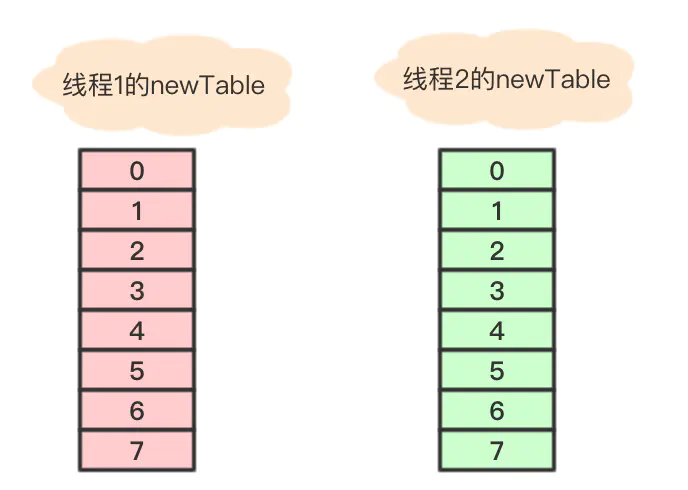
线程B在执行到Entry<K,V> next = e.next;后挂起,此时e指向元素a,e.next指向元素b
到线程A在new table的数组7位置依次用头插法插入3个元素后
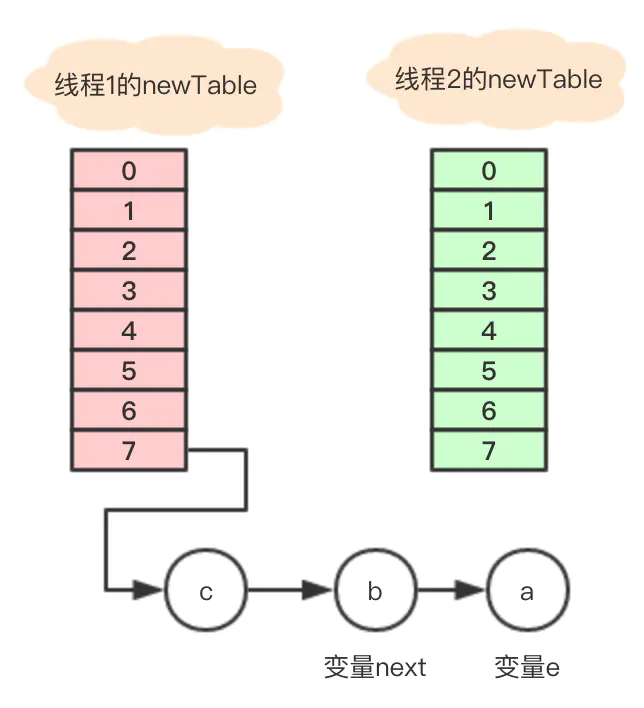
此时线程B继续执行以下代码
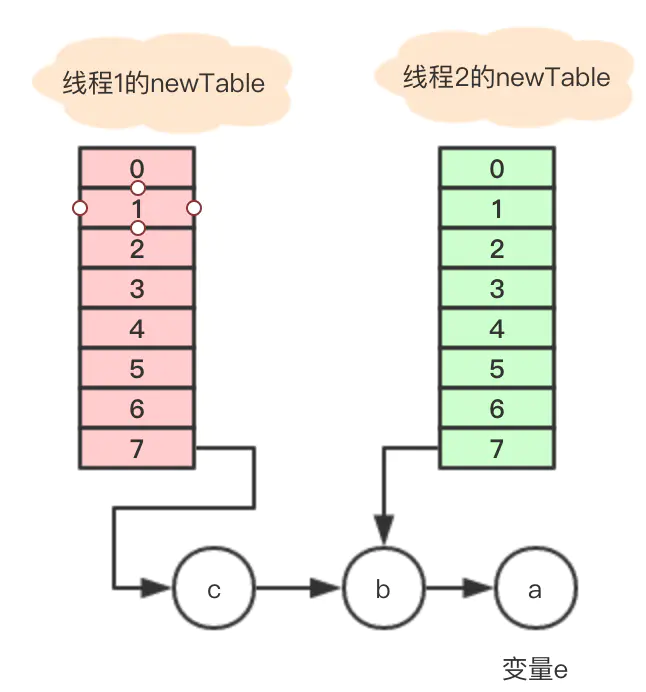
Entry<K,V> next = e.next; //next = b e.next = newTable[i]; //将数组7的地址赋予变量e.nextnewTable[i] = e; //将a放到数组7的位置e = next; // e = next = b
执行结束的关系如图
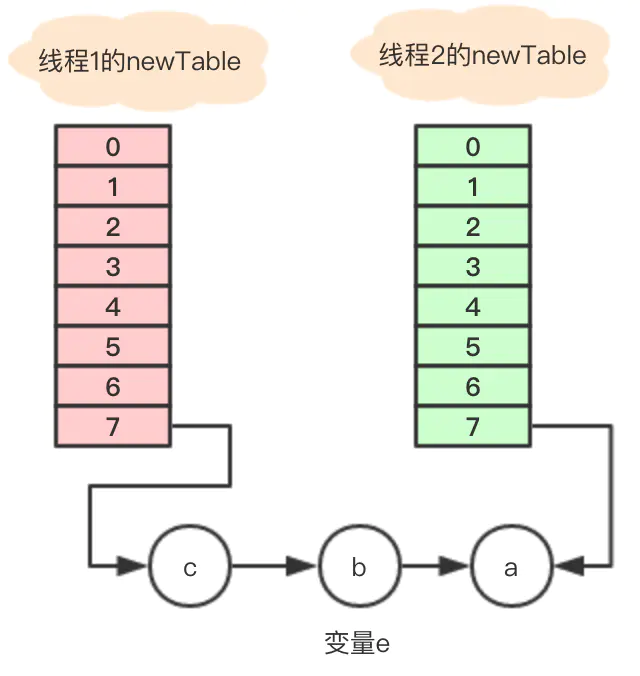
变量e = b不是null,循环继续执行,
Entry<K,V> next = e.next; // next = a e.next = newTable[i]; //数组7地址指向e.next
newTable[i] = e; //将b放到数组7的位置
e = next; //e =next = a执行后引用关系图
此时变量e = a仍旧不为空,继续循环。。
Entry<K,V> next = e.next; // 变量a没有next,所以next = null e.next = newTable[i]; // 因为newTable[i]存的是b,这一步相当于将a的next指向了b,于是问题出现了
newTable[i] = e; //将变量a放到数组7的位置
e = next; // e= next = null
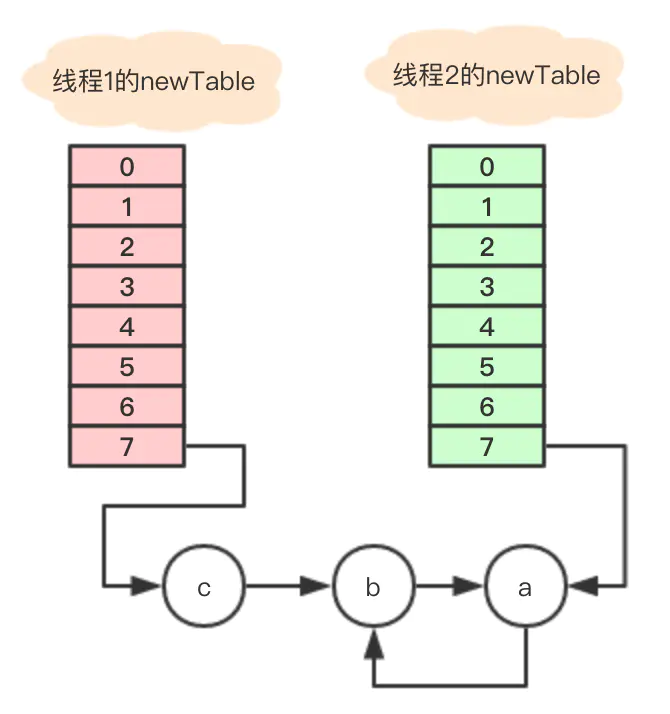
当在数组7遍历节点寻找对应的key时, 节点a和b就发生了死循环, 直到cpu被完全耗尽。
另外,如果最终线程2执行了table = newTable;那元素C就发生了数据丢失问题
四.总结
通过解读HashMap源码并结合实例可以发现,HashMap扩容导致死循环的主要原因在于扩容过程中使用头插法将oldTable中的单链表中的节点插入到newTable的单链表头中,所以newTable中的单链表会倒置oldTable中的单链表。那么在多个线程同时扩容的情况下就可能导致扩容后的HashMap中存在一个有环的单链表,从而导致后续执行get操作的时候,会触发死循环,引起CPU的100%问题。所以一定要避免在并发环境下使用HashMap。

