HBase学习笔记
一、HBase是什么,为什么要使用HBase?
Hbase简介
- HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
- HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable使用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为协同服务。
HBase使用场景及应用
使用场景
- 写密集型应用,每天写入量巨大,而相对读数量较小的应用
- 不需要复杂查询条件来查询数据的应用
1.使用rowkey,单条记录或者小范围的查询性能不错,大范围的查询由于分布式的原因,可能在性能上有点影响。
2.使用HBase的过滤器的话性能比较差。 - 不需要关联的场景,HBase为NoSQL无法支持join
- 可靠性要求高
1.master支持主备热切。
2.regionServer宕机,region会分配给在线的机器。
3.数据持久化在HDFS,默认3份,HDFS保证数据可靠性。
4.内存的数据若丢失可以通过Wal预写日志恢复。 - 数据量较大,而且增长量无法预估的应用
HBase支持在线扩展,即使在一段时间内数据量呈井喷式增长,也可以通过HBase横向 扩展来满足功能。
应用
- 对象存储系统(Medium Object Storage)
- OLAP的存储(Kylin、Phoenix)
- 时序型数据(openTsDB应用)
- 用户画像系统(动态列)
- 消息/订单系统
- feed流系统存储(微博)
二、Hbase数据模型
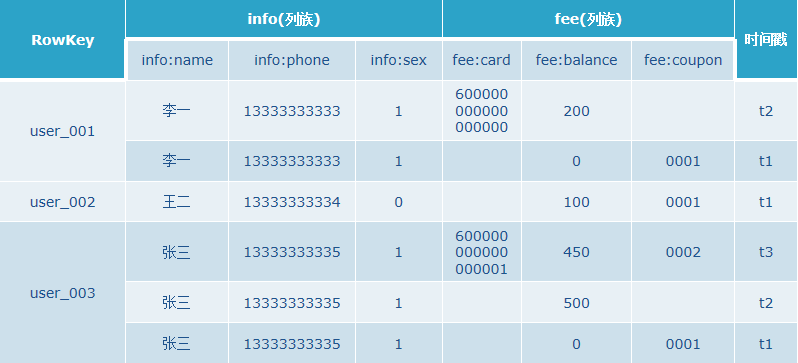
逻辑视图
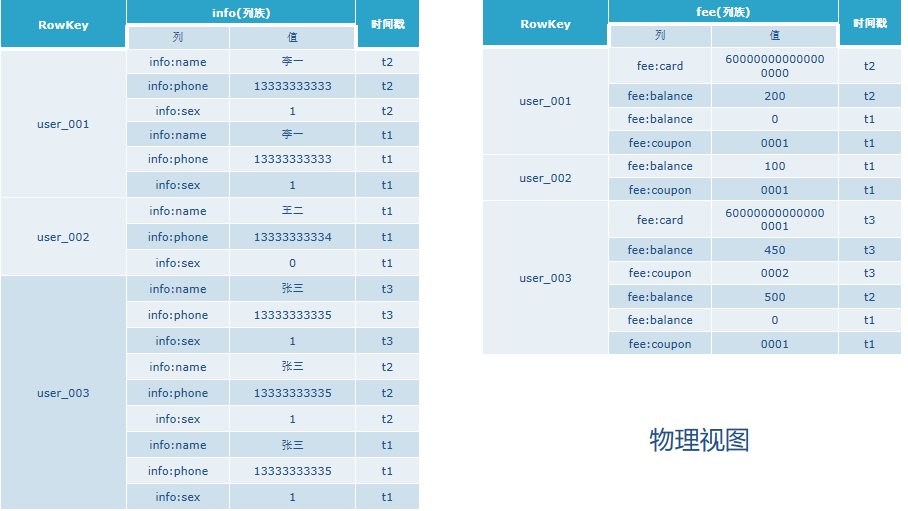
物理视图
表(table)
- HBase用表来组织数据,表名是字符串,由可以在文件系统路径里使用的字符组成。
行(row)
- 在表里,数据按行存储,行由行键(rowkey)唯一标识。行键没有数据类型,总是视为字节数据byte[]。
列族(column family)
- 行里的数据按照列族分组,列族也影响到HBase数据的物理存放。因此,他们必须事先定义并且不轻易修改。
- 表中每行拥有相同列族,尽管行不需要在每个列族里存储数据。
- 列族名字是字符串,由可以再文件系统路径里使用的字符组成。
列 (column )
- 列名由列族和列修饰符组成,列族内列可任意扩展
列限定符(column qualifier)
- 列族里的数据通过列限定符或列来定位。
- 列限定符不必事先定义,列限定符不必在不同行之前保持一致。就像行键一样,列限定符没有数据类型,总是视为字节数组byte[]。
单元(cell)
- 行键、列族和列限定符一起确定一个单元,存储在单元里的数据称为单元值(value)。
- 值也没有数据类型,总是视为字节数组byte[]。
时间版本(version)
- 单元值有时间版本,时间版本用时间戳标识,是一个long。
- 没有指定时间版本时,当时时间戳作为操作的基础。
- HBase保留单元值时间版本的数量基于列族进行配置。默认数量是3个。
三、HBase的特性
大:
- 一个表可以有上亿行,上百万列。
面向列:
- 面向列表(簇)的存储和权限控制,列(簇)独立检索。
稀疏:
- 对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:
- 每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:
- 每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:
- 数据类型单一。
与传统数据库对比:

四、HBase操作
存取数据
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("mytable"));
//行键
Put p = new Put(Bytes.toBytes("HBaseTest01"));
//列族 + 列限定符 + value
p.add(Bytes.toBytes("info"), Bytes.toBytes("username"),Bytes.toBytes("Poul"));
p.add(Bytes.toBytes("info"), Bytes.toBytes("age"),Bytes.toBytes(18));
p.add(Bytes.toBytes("info"), Bytes.toBytes("password"),Bytes.toBytes("123456"));
table.put(p);
table.close();
修改数据
Put p = new Put(Bytes.toBytes("HBaseTest01"));
p.add(Bytes.toBytes("info"), Bytes.toBytes("password"),Bytes.toBytes("abc123"));
table.put(p);
table.close();
读数据
####### 返回行中所有列族的所有列:
Get g = new Get(Bytes.toBytes("HBaseTest01"));
Result r = table.get(g);
####### 返回指定列族的所有列:
Get g = new Get(Bytes.toBytes("HBaseTest01"));
g.addColumn(Bytes.toBytes("info"),Bytes.toBytes("password"));
Result r = table.get(g);
####### 返回指定值,从字节转换回字符串:
Get g = new Get(Bytes.toBytes("HBaseTest01"));
g.addFamily(Bytes.toBytes("info"));
byte[] b = r.getValue(Bytes.toBytes("info"),Bytes.toBytes("password"));
String password = Bytes.toString(b);
删除数据
####### 删除行中所有列族的所有列:
Delete d = new Delete(Bytes.toBytes("HBaseTest01"));
table.delete(d);
####### 指定坐标删除行的一部分:
Delete d = new Delete(Bytes.toBytes("HBaseTest01"));
d.deleteColumns(Bytes.toBytes("info"),Bytes.toBytes("password"));
table.delete(d);
注意:deleteColumn是删除某一个列族里的最新时间戳版本。
deleteColumns是删除某个列族里的所有时间戳版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号