

一、索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,
同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
二、索引类型
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
1. FULLTEXT
即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE ,ALTER TABLE ,
CREATE INDEX 使用,不过目前只有 CHAR、VARCHAR ,TEXT 列上可以创建全文索引。
全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE “%word%"
这类针对文本的模糊查询效率较低的问题。
2. HASH
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,
即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
3. BTREE
BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中(二叉树),
每次查询都是从树的入口root开始,依次遍历node,获取leaf。这是MySQL里默认和最常用的索引类型。
4. RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
相对于BTREE,RTREE的优势在于范围查找。
三、索引种类
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
四、创建和查看索引
建表时定义的主键约束,外键约束,唯一约束,这都相当于在指定列上创建浏览索引。
建表时创建的索引语法如下
CREATE TABLE table_name [col_name data_type]
[ UNIQUE | FULLTEXT | SPATIAL ] [ INDEX | KEY ] [ index_name ] ( col_name [length] ) [ASC | DESC]
UNIQUE | FULLTEXT | SPATIAL 为可选参数,分别是唯一索引、全文索引、空间索引。
INDEX | KEY 同义词,作用相同,
index_name 索引名称,为可选参数,如果不写,默认以col_name 为索引名称。
col_name 是创建索引的字段列
length是 可选参数,表示索引的长度 ,只有字符类型的索引才能指定长度
ASC | DESC 是降序或是升序的索引值存储。
补充:
--创建普通索引 CREATE INDEX index_name ON table_name(col_name);
--创建唯一索引 CREATE UNIQUE INDEX index_name ON table_name(col_name);
--创建普通组合索引 CREATE INDEX index_name ON table_name(col_name_1,col_name_2);
--创建唯一组合索引 CREATE UNIQUE INDEX index_name ON table_name(col_name_1,col_name_2);
(一)创建和查看普通索引 :作用只是加快数据的查询
1.在fruit表中的city_index字段上建立普通索引

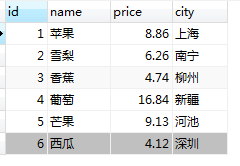
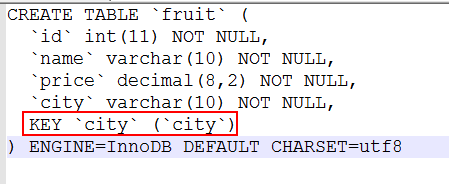
可以看成,fruit上city字段上成功创建了索引,七索引名称是city由mysql字段添加
使用explan查看一下是否在用

select_type 指定所使用的select查询类型,这里simple是简单select ,不使用union或是子查询,其他的还有primary 、union 、subquery
SIMPLE 简单查询
PRIMARY 最外层查询
SUBQUERY 映射为子查询
DERIVED 子查询
UNION 联合
UNION RESULT 使用联合的结果
table 读到的表,他们按被读取到的先后顺序排列
type 指定了本数据表与其他数据表之间的关联关系,可能取值有system、const、eq_ref 、ref、range、index、all
查询时的访问方式,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/constALL
possible_keys : mysql在搜索数据记录是可以选用的各个索引。
key :mysql实际选用的索引
key_len是 给出索引按字节计算的长度,越小表示越快。
ref 是行给出了关联关系中另一个数据表里的数据列的名字
rows 行是mysql在执行这个查询时预计会从这个数据表里读出的数据行的个数
(二)创建和查看唯一索引
唯一索引和普通索引类似,不同的是,索引列的值必须唯一,但允许为null ,如果是组合索引,列值的组合必须唯一。

SHOW CREATE TABLE newfruit
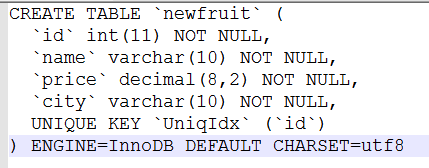
(三)创建和查看多列索引
在fruit2表上创建id ,name, price的组合索引

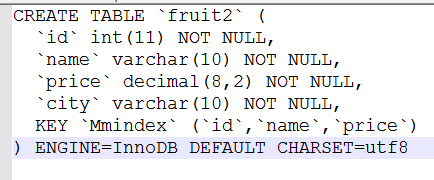
1.查询有没有使用索引 :使用

2. 未使用

3.未使用

4.使用

(四)创建和查看全文索引
全文索引只有MyISAM存储引擎支持,并且只为char varchar和text列,只能添加到整个字段上,不支持局部(前缀)索引。

全文索引适合大型数据集
(五)修改表结构创建索引
语法
ALTER TABLE table_name ADD INDEX index_name(col_name);
查看表的所有索引
#查看:
show indexes from `表名`;
#或
show keys from `表名`;

补充:
添加主键索引和唯一索引语法:
ALTER TABLE table_name ADD INDEX index_name(col_name);
- 查看执行时间
set profiling = 1;
SQL...
show profiles;
五、删除索引
语法一、
DROP INDEX index_name ON table_name
语法二、
ALTER TABLE table_name DROP INDEX index_name

六、其它注意事项
- 避免使用select *- count(1)或count(列) 代替 count(*)
- 创建表时尽量时 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(经常使用多个条件查询时)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 连表时注意条件类型需一致
- 索引散列值(重复多)不适合建索引,例:性别不适合
七、LIMIT分页
若需求是每页显示10条数据,如何建立分页?
我们可以先使用LIMIT尝试:
--第一页SELECT * FROM table_name LIMIT 0,10;
--第二页SELECT * FROM table_name LIMIT 10,10;
--第三页SELECT * FROM table_name LIMIT 20,10;
但是这样做有如下弊端:
每一条select语句都会从1遍历至当前位置,若跳转到第100页,则会遍历1000条记录
若记录的id不连续,则会出错
改善:
若已知每页的max_id和min_id,则可以通过主键索引来快速定位:
--下一页SELECT * FROM table_name WHERE id in (SELECT id FROM table_name WHERE id > max_id LIMIT 10); --上一页SELECT * FROM table_name WHERE id in (SELECT id FROM table_name WHERE id < min_id ORDER BY id DESC LIMIT 10); --当前页之后的某一页 SELECT * FROM table_name WHERE id in (SELECT id FROM (SELECT id FROM (SELECT id FROM table_name WHERE id < min_id ORDER BY id desc LIMIT (页数差*10)) AS N ORDER BY N.id ASC LIMIT 10) AS P ORDER BY P.id ASC);
--当前页之前的某一页SELECT * FROM table_name WHERE id in (SELECT id FROM (SELECT id FROM (SELECT id FROM table_name WHERE id > max_id LIMIT (页数差*10)) AS N ORDER BY N.id DESC LIMIT 10) AS P) ORDER BY id ASC;
八、索引的机制
1.为什么我们添加完索引后查询速度为变快?
传统的查询方法,是按照表的顺序遍历的,不论查询几条数据,mysql需要将表的数据从头到尾遍历一遍
在我们添加完索引之后,mysql一般通过BTREE算法生成一个索引文件,在查询数据库时,
找到索引文件进行遍历(折半查找大幅查询效率),找到相应的键从而获取数据
2.索引的代价
2.1创建索引是为产生索引文件的,占用磁盘空间
2.2索引文件是一个二叉树类型的文件,可想而知我们的dml操作同样也会对索引文件进行修改,所以性能会下降
3.在哪些column上使用索引?
3.1较频繁的作为查询条件字段应该创建索引
3.2唯一性太差的字段不适合创建索引,尽管频繁作为查询条件,例如gender性别字段
3.3更新非常频繁的字段不适合作为索引
3.4不会出现在where子句中的字段不该创建索引
总结: 满足以下条件的字段,才应该创建索引.
a: 肯定在where条经常使用
b: 该字段的内容不是唯一的几个值
c: 字段内容不是频繁变化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号