
一、
建员工表 : d_id 是部门 id
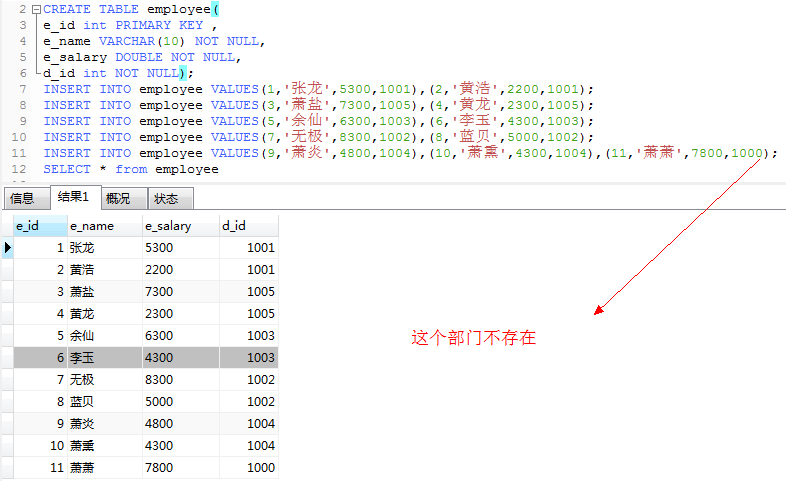
1.多字段进行排序,薪资一样,名字按字典顺序排
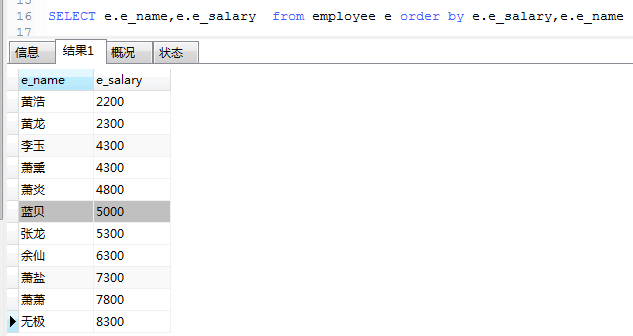
2.limit的使用
语法
limit [位置偏移量] 行数。 位置偏移量:就是从哪行开始显示,第一条记录是0,第二条为1,...
连接查询
(一)内连接 查询
使用比较运算符进行表之间某些列数据的比较操作,并列出这些表中与连接条件相匹配的数据行,组成新
的记录,就是只有满足条件的列才会出现在结果列表中。
建部门表department
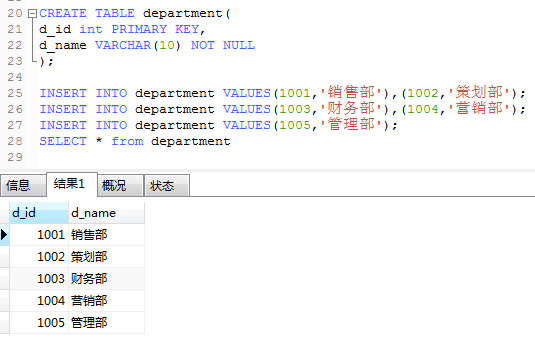
1.employee 和department 两个表有共同的字段d_id 可以建立连接,使用内连接查询
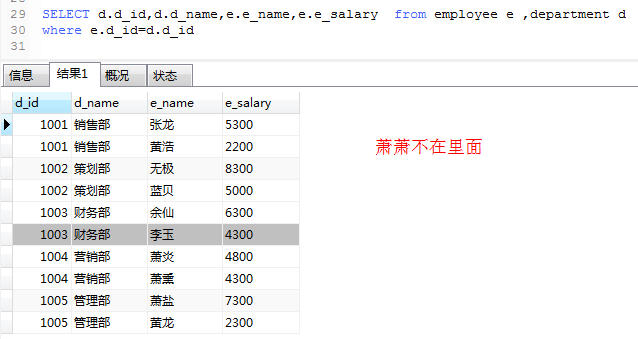
2.使用INNER JOIN 语句 和上面一样的效果
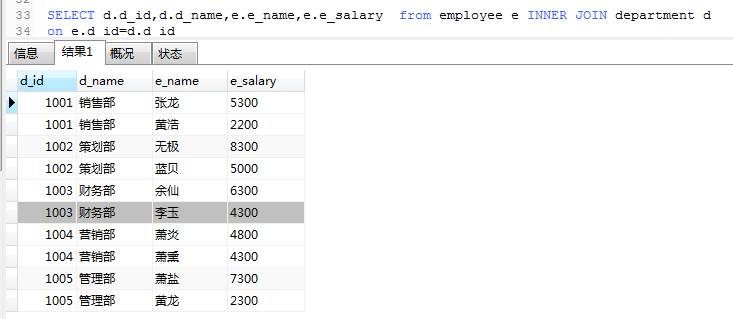
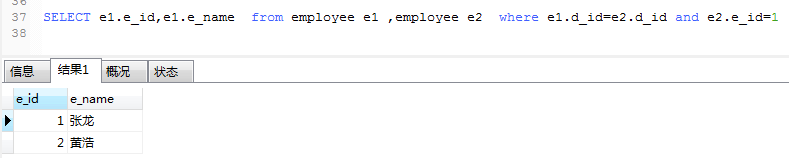
3. 如果一个连接查询中涉及到的表是同一张表,那就是自连接查询
查询e_id=1的员工在的部门中所有员工的编号。
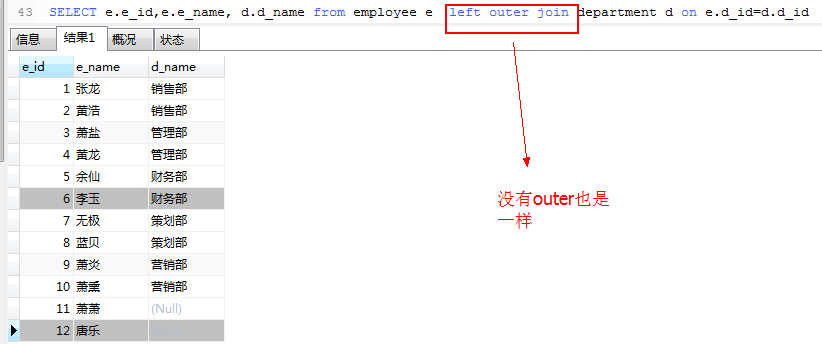
左外连接查询
1.查询所有员工所在部门,没有部门也列出。

右外连接查询
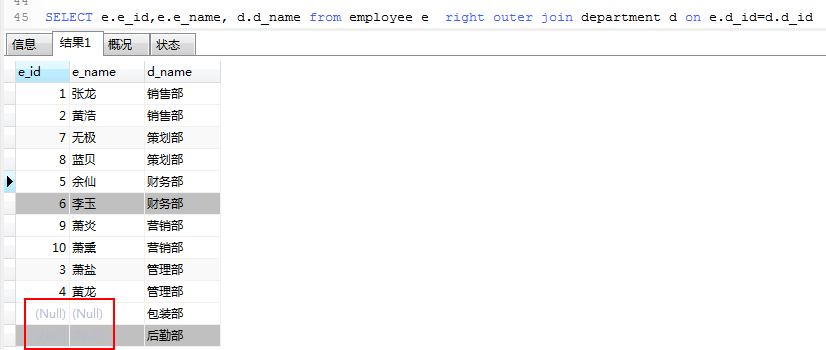
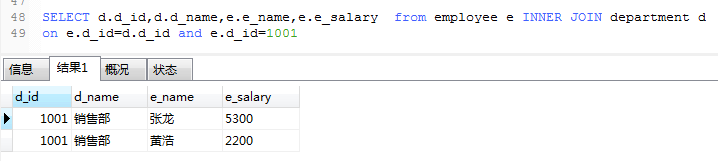
复合条件连接诶查询
1.使用INNER JOIN 查询employee 中部门编号为1001的客户名称
子查询
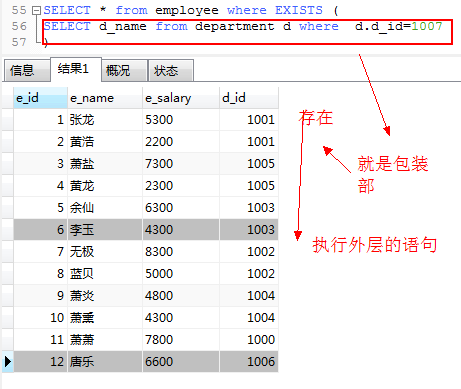
带exists关键字的子查询
exists后面的是任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,则exists返回为true,
此时外层查询语句将进行查询,反之,exists发回false,则外层语句将不进行查询。
1. 查询department中是否存在d_id=1007的员工,如果存在则查询employee表的员工。
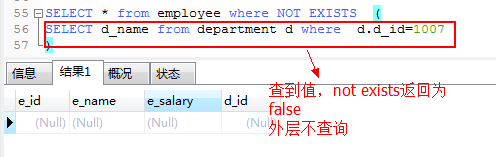
2.not exists和上面相反,原理一样
合并查询
UNION 和UNION ALL
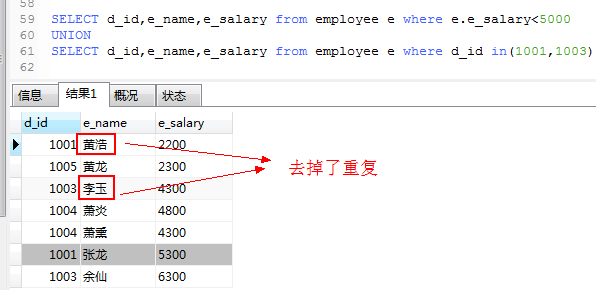
使用union关键字可以给出多条select语句,并将它们的结果合成单个结果集,合并时两个表对应的列数和数据类型必须相同,
各个select之间用union或是union all 相隔离,union 没有all时,执行的时候会删除重复的记录,所有返回的都是唯一的,
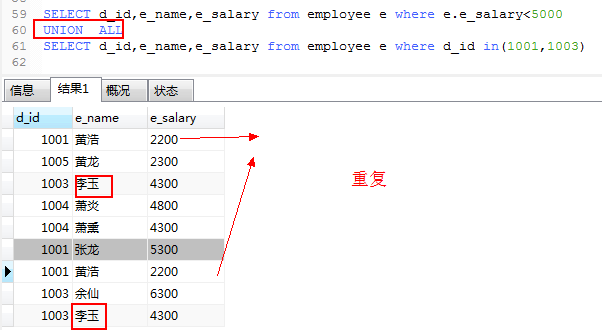
有all 的话,不删除重复,且不对结果进行排序。
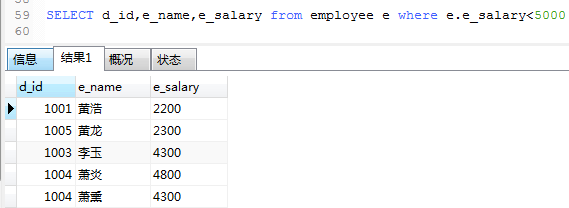
1. 查询所有工资小于5000的员工信息,查询d_id等于1001和1003的所有员工信息使用UNION连接查询。
先看所有工资小于5000的员工信息的数据
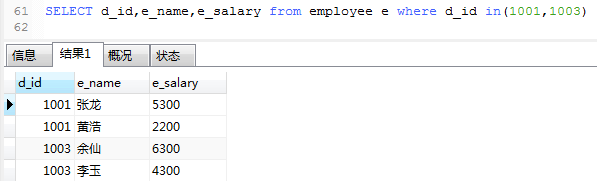
查询d_id等于1001和1003的所有员工信息
用union
2.使用UNION ALL
正则表达式
mysql使用regexp 关键字指定正则表达式的字符匹配模式,以下列出regexp操作符后常用的匹配字符

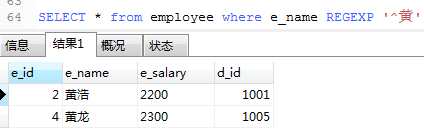
1.查询employee中,e_name以黄子开头的员工
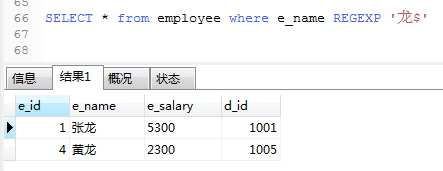
2.查询employee中,e_name以龙字结束的员工
3.为了达到效果重新建emp表
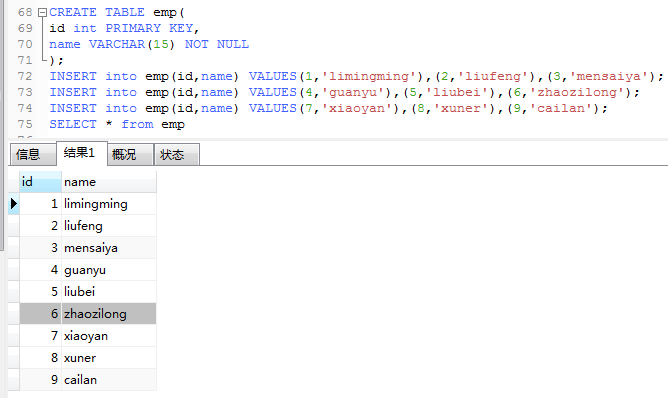
查询emp中name里面有i 和a且两个字母之间只有一个字母的记录。

4. 查询name中,以字母x开头,且x后出现字母 i 的记录
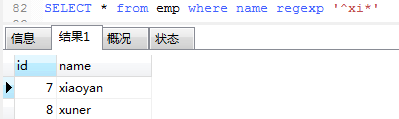
因为*是匹配零次或是多次,所以x后没有i也会匹配
5.4.查询name中,以字母x开头,且x后出现字母 i 至少一次的记录
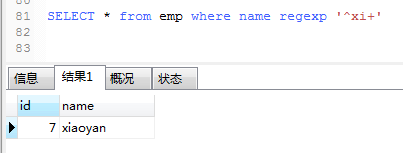
6..查询name中,包含en的名字
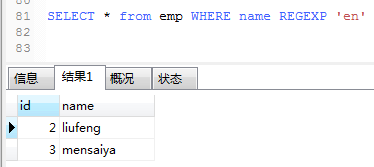
7. 查询name中,包含en或是ao的名字 :会删除重复的项
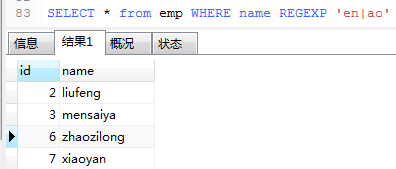
8. 用like查询name字段中包含en 的名字
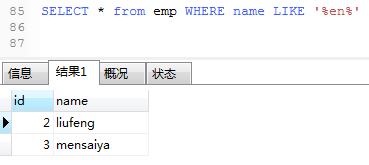
9.数据库添加mao这个名字,查询名字中包含m或o,或是两者都有的名字
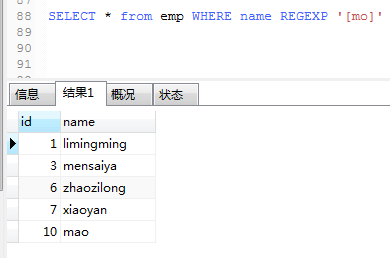
10.查询id字段中包含2或是3,或是4的情况
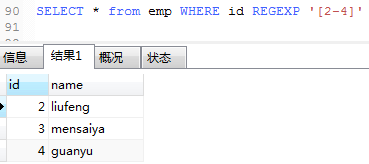
也可以写成[234]
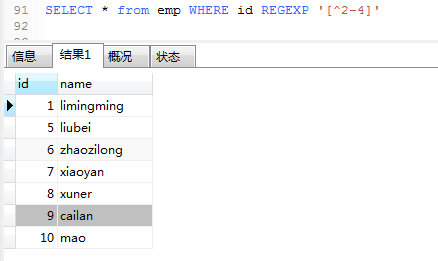
10.查询id字段中包含2,3以外的情况
11.查询name中字母 i至少出现一次的情况
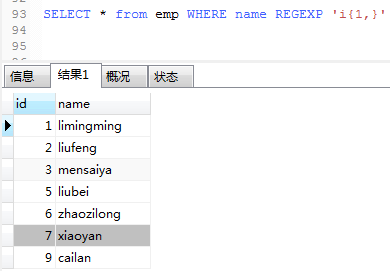
总结:regexp和like
当like 查询以包含en字母的时,like ‘%en%’ ,这样的情况,regexp和 like一样的效果。
关于LIKE和REGEXP的区别:LIKE匹配整个列。如果被匹配的文本仅在列值中出现,LIKE并不会找到它,
相应的行也不会返回(当然,使用通配符除外)。而REGEXP在列值内进行匹配,如果被匹配的匹配的文本在列值中出现,
REGEXP将会找到它,相应的行将被返回,这时一个非常重要的差别(当然,如果适应定位符号^和$,可以实现REGEXP匹配整个列而不是列的子集)。
关于大小写的区分:MySQL中正则表达式匹配(从版本3.23.4后)不区分大小写 。
如果要区分大小写,应该使用BINARY关键字,如where post_name REGEXP BINARY 'Hello .000'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号