ELK+Filebeat+kafka+zookeeper构建海量日志平台
根据上一篇文档了解了ELK,Filebeat,kafka,zookeeper组件的功能,也部署了elk,接下来测试一下elk集群的功能。
1. logstash
运行测试
在终端中,使用 logstash将信息写入elasticsearch:
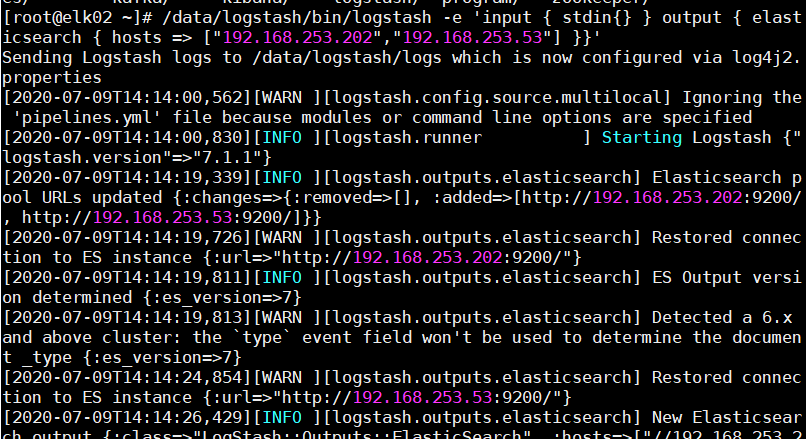
输入信息

在elasticsearch中查看logstash新添加索引
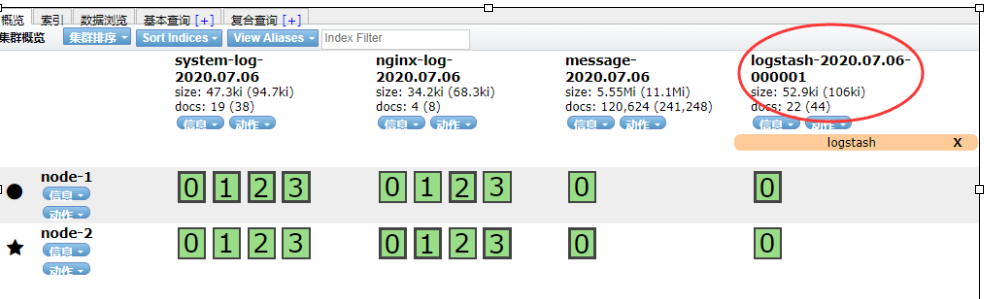
如果要修改elasticsearch的分片数量,使用以下命令
#修改elaticsearch的分片数和副本数,"number_of_shards": 4 分片数
curl -XPUT 'http://192.168.253.202:9200/_template/template_http_request_record' -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"settings": {"number_of_shards": 4,"number_of_replicas": 1}}'
pipeline文件,文件位置自定义,此处文件放置于/data/logstash/conf.d,没有则创建一个目录,可创建多个
2.elk实例
2.1收集系统日志
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.253.202:9200","192.168.253.53:9200"]
index => "message-system-%{+YYYY.MM.dd}"
}
}
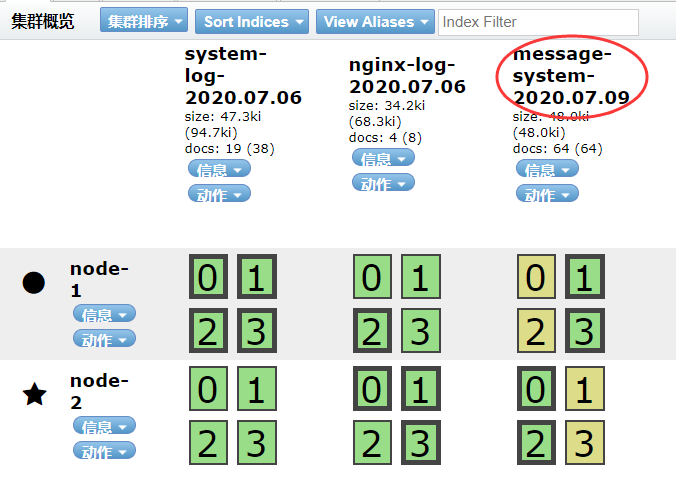
2.2 收集elsaticsearch的error日志
用if判断,两种日志分别写到不同的索引中。此处的type,不可以重复,也就是说日志的域不可以有type这个名称

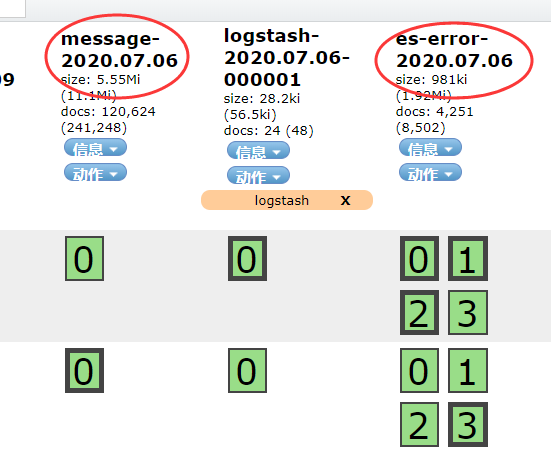
将日志添加到kibana上
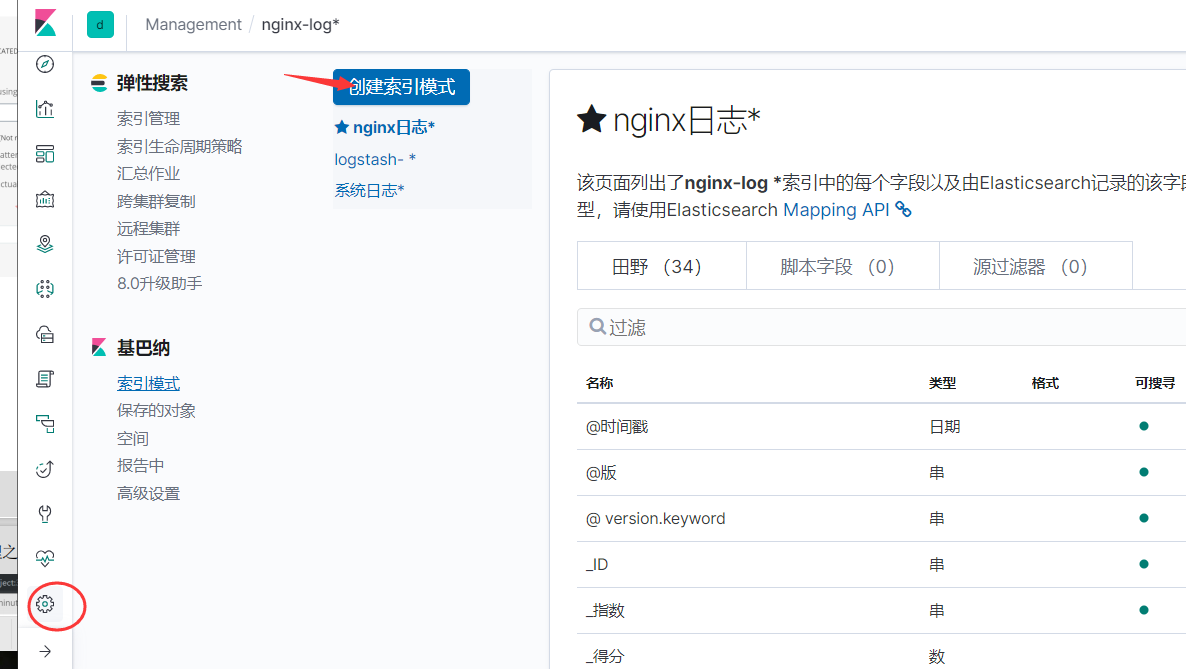

discover可看到内容
2.4收集nginx访问日志
这里使用codec的json插件将日志的域进行分段,使用key-value的方式,使日志格式更清晰,易搜索,还可以降低cpu负载
使用yum下载nginx
[root@elk01 conf.d]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
log_format json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"status":"$status"}';
access_log /var/log/nginx/access.log json;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
启动nginx
logstash抓取nginx日志
[root@elk01 conf.d]# cat test_nginx.conf
input {
syslog {
type => "system-log"
host => "192.168.253.202"
port => "514"
}
file {
path => "/var/log/nginx/access.log"
type => "nginx-log"
start_position => "beginning"
codec => "json"
}
file {
path => "/data/program/software/elasticsearch/elk_logs/my-cluster.log"
type => "es-error"
start_position => "beginning"
}
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
if [type] == "nginx-log" {
elasticsearch {
hosts => ["192.168.253.202:9200","192.168.253.53:9200"]
index => "nginx-log-%{+YYYY.MM.dd}"
}
}
if [type] == "es-error" {
elasticsearch {
hosts => ["192.168.253.202:9200","192.168.253.53:9200"]
index => "es-error-%{+YYYY.MM.dd}"
}
}
if [type] == "system-log" {
elasticsearch {
hosts => ["192.168.253.202:9200","192.168.253.53:9200"]
index => "system-log-%{+YYYY.MM.dd}"
}
}
if [type] == "system" {
elasticsearch {
hosts => ["192.168.253.202:9200","192.168.253.53:9200"]
index => "message-%{+YYYY.MM.dd}"
}
}
}
3.日志分析平台
3.1 架构图
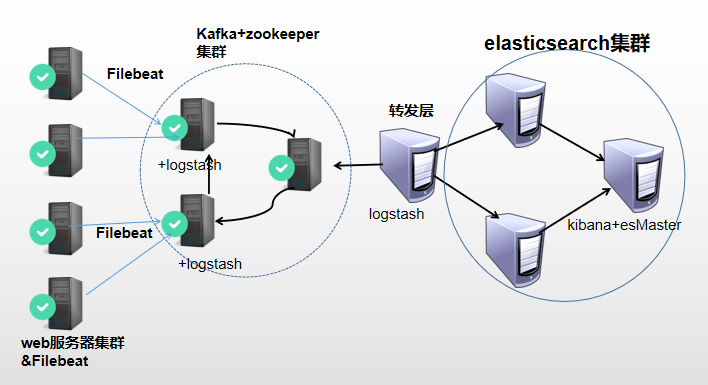
3.2 架构解读 : (整个架构从左到右,总共分为5层)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、数据处理层,数据缓存层
logstash服务把接受到的日志经过格式处理,转存到本地的kafka broker+zookeeper 集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层、数据持久化存储
ES DataNode 会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要 协调 ES集群,处理数据检索请求,数据展示。
3.3 各服务器角色分配 :
| IP | 角色 | 所属集群 |
| 192.168.253.202 | 采集层 | filebeat |
| 192.168.253.202 | 数据处理层,缓存层 | logstash+kafka+zookeeper |
| 192.168.253.53 | ||
| 192.168.253.54 | ||
| 192.168.253.202 | 日志展示 | logstash+elasticsearch+kibana |
软件包版本:
jdk-8u101-linux-x64.rpm
elasticsearch-7.7.1-linux-x86_64.tar.gz
logstash-7.1.1.tar.gz
kibana-7.1.1-linux-x64.tar.gz
filebeat-6.2.3-linux-x86.tar.gz
kafka_2.11-2.2.1.tgz
因为kafka此版本含有zookeeper,为了版本统一,直接用kafka带有的zookeeper版本
3.4 部署安装
3.4.1节点初始化
关闭防火墙,时间同步。
3.4.2 部署elk集群
出门左拐,查看上一篇文章 https://www.cnblogs.com/lanist/p/13259046.html
3.4.3 配置logstash
[root@elk01 conf.d]# cat logstash_to_filebeat.conf
input {
beats {
port => 5044
}
}
output {
kafka {
bootstrap_servers => "192.168.253.202:9092,192.168.253.53:9092"
topic_id => "lanist01"
}
}
[root@elk01 conf.d]# cat logstash_to_es.conf input { kafka { bootstrap_servers => "192.168.253.202:9092,192.168.253.53:9092" topics => ["lanist01"] } } output { elasticsearch { hosts => ["192.168.253.202:9200","192.168.253.53:9200"] index => "dev-log-%{+YYYY.MM.dd}" } }
3.4.5 部署kafka,zookeeper(为了方便起见,所有加压过的目录都放在/data下),202,53,54节点都要配置
解压:略
创建logs目录
[root@elk01 kafka]# ls bin config libs LICENSE logs NOTICE site-docs
(1)zookeeper配置
[root@elk01 config]# grep -vE "^#|^$" zookeeper.properties dataDir=/var/zookeeper clientPort=2181 maxClientCnxns=0 initLimit=5 syncLimit=2 server.1=0.0.0.0:2888:3888 server.2=elk02:2888:3888 server.3=elk03:2888:3888
对应节点,做对应的的修改
创建zookeeper的日志目录

启动zookeeper集群--三个节点一样
nohup /data/kafka/bin/zookeeper-server-start.sh /data/kafka/config/zookeeper.properties >> /tmp/zookeep.nohup &
(2)kafka配置
cd config [root@elk01 config]# grep -vE "^#|^$" server.properties broker.id=1 listeners=PLAINTEXT://elk01:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/data/program/software/kafka/logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=elk01:2181,elk02:2181,elk03:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
其他两个节点只修改broker.id和listeners即可
启动kafka--三个节点都要启动
nohup /data/kafka/bin/kafka-server-start.sh /data/kafka/config/server.properties >/tmp/kafka.nohup 2>&1 &

3.4.6 部署filebeat(日志采集)
解压包
filebeat配置
[root@elk01 filebeat]# vim filebeat.yml
filebeat.prospectors: - type: log enabled: true paths: - /var/log/*.log fields: type: log_common - type: log enabled: true paths: - /var/log/nginx/access.log fields: log_topics: nginx
output.logstash:
hosts: ["localhost:5044"]
启动filebeat
[root@elk01 filebeat]# ./filebeat -e -c filebeat.yml & [2] 11964
启动logstash,filebeat收集的日志转发到kafka上
[root@elk01 filebeat]# nohup /data/program/software/logstash/bin/logstash -f /data/program/software/logstash/conf.d/logstash_to_filebeat.conf>>/tmp/logstash.nohup 2>&1 & [1] 11985
在kafka终端上消费测试。
[root@elk03 ~]# /data/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.253.202:9092 --topic lanist01 --from-beginning
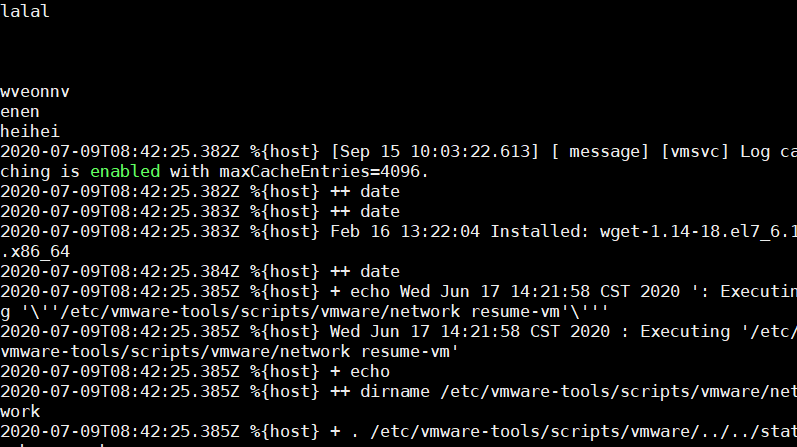
启动logstash转发
/data/program/software/logstash/bin/logstash -f /data/program/software/logstash/conf.d/logstash_to_es.conf
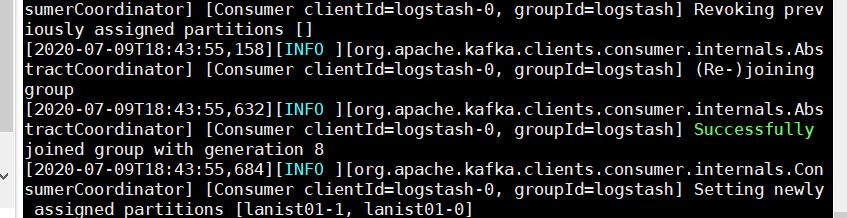
在es上测试结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号