Scalable Approaches for Test Suite Reduction 文献阅读笔记
该论文的特殊之处
能够将大型的测试套件进行排序,提出了FAST系列测试套件排序方法,基于相似度,以及minhashing and locality-sensitive hashing algorithms
FAST-R测试套件缩减,来自大数据的技术,k-means++、
。。。好困啊 不想写了
random projection technique,降维的同时维持了两个点之间的距离
摘要关键词
启发式算法heuristics
大数据 big data
均匀分布的子集 evenly spread subset
输入:test source code or command line input
固定预算: fixed budget
如果存在的话: if any
名词解释
测试用例排序:将最有可能失效的测试用例放到前面来执行,意思就是给测试套件进行排序
测试用例选择(也叫测试用例缩减):选择一个测试套件的子集,这个子集尽可能地包括会失效地测试用例
历史上常用的评价指标
检错的效率 fault detection effectiveness
平均错误检测率
缩减后的测试套件的错误检测损失
和原先的测试套件相比所节省的时间
测试方法本身:如排序或者缩减需要花费的时间,花费的额外资源、金钱等等
作者与发展历程
Orso and coauthors 2004年【29】:在效率和准确率之间做好平衡
Gligoric and coauthors 【16】:提出回归测试技术应该包括3个阶段,每个阶段都耗时:analysis phase, an execution phase, and a collection phase,认为前人有少部分会关注分析的时间,但是没有人会关注最后一个阶段
Elbaum and coauthors【15】:
at scale industries need approaches “that are relatively inexpensive and do not rely on code coverage information”. In fact, for white-box techniques, the cost of collecting and saving up-to-date code
coverage information should also be considered as part of the collection phase. This is confirmed by Herzig [19], who observes that code coverage is not for free as assumed in many works, and can cause up to 30% of time overhead!
论文的方法概述
把每个测试用例看作d维空间的一个点,那么问题就变成了找到空间里的子集(子集是缩减的测试套件)的一个中心点。
将能够代表一个测试用例的那些代码转换为向量,比如源代码、命令行的输入(比如shell命令)
each dimension corresponds to a different term of the source code
n is equal to the total number of terms used in the whole test suite
这2句话没有懂
根据下面这张图可以看出,作者提出的方法,有点像one hot,但是这里统计的是单词出现频率。
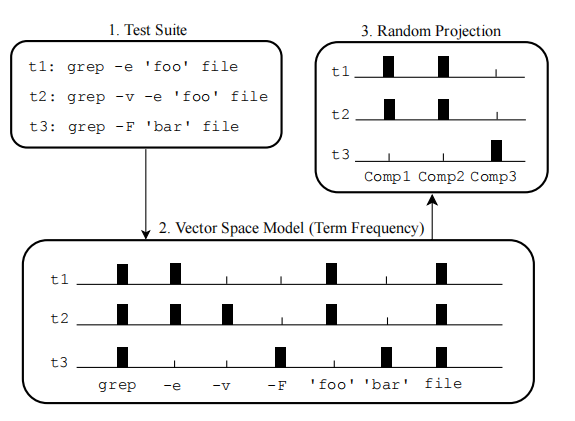
这个时候一个向量可能会比较长,所以使用了一种技术叫做随机投影技术,这种技术可以将向量的维度降低,但是不会影响两两向量之间的距离。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号