hadoop以及hdfs概括
大数据技术生态架构
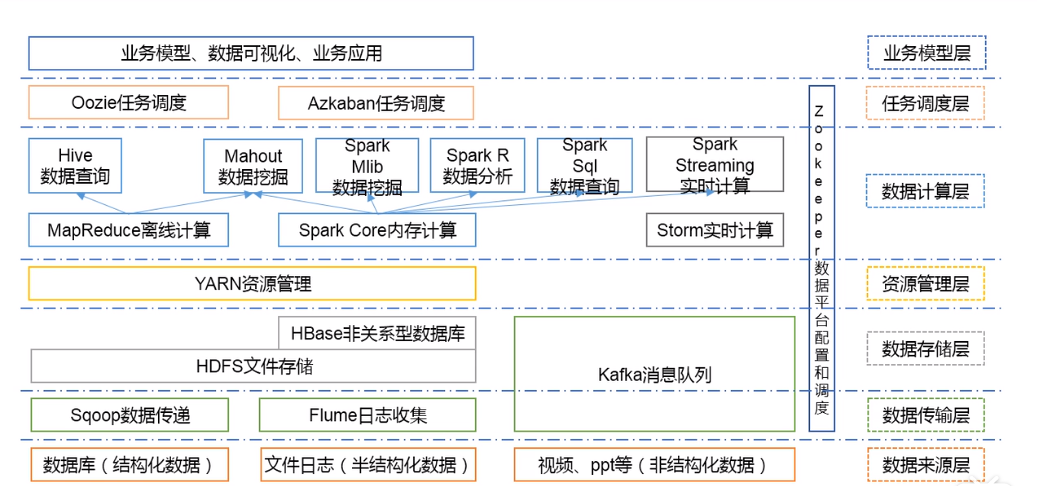
1)来源层:1.数据库 2.日志信息 3.视频、ppt
2)传输层:1.Sqoop:数据库导入导出2.Flume处理读写日志 3.Kafka缓存数据
3)存储层:1.HDFS 存储数据 2.kafka也能存储一部分 3.hbase 键值对
4)资源管理层:yarn负责调度磁盘、内存。
5)数据计算层:1.MapReduce(hadoop核心)2.spark CORE内存计算(缺点宕机丢失)
在mapreduce下两个数据分析:1.Hive(查询)2.Mahout(挖掘)
spark下:1.S milib 挖掘
2.S R分析 3.S sql查询mapreduce和spark都是离线计算,适合年月日活等的统计。
3.实时计算:1.strom 2.主流 spark-streaming(继承功能强大)
6)任务调度层:1.Oozie任务调度 2.Azkaban任务调度
7)业务模型层:数据可视化等
mysql和hbase(非关系数据库)的区别:hbase存储数据是以k-v键值对的形式。
spqarksql类似于hive:写sql可以实现复杂的分析计算过程。
mapreduce:离线计算,月日年的消费情况。
zookeeper:数据平台配置和调度(改zookeeper配置可以一下更改所有spark的配置)
来源-----传输------存储-------调度------分析(1.离线2.实时)-----对job调度-------配置管理-----业务模型层。
三、hdfs(分布式文件系统):
1.适合处理大数据(超大文件)
2.流式数据访问:一次写入,多次读取。
3.可构建在廉价机器
4.不适合低延时,hbase适合低延时
5.无法高效对小文件修改
6.hdfs只支持追加不支持修改
数据块:块一般为64M或者128MB,hdfs上的文件也被划分为多个块,小于一个块的文件不会占据整个块的空间。
hdfs的块比磁盘的块大,目的是为了最小化寻址开销。
数据块好处:
1)一个文件的大小可以大于任意一个磁盘的容量
2)使用抽象块而非文件作为存储单元,大大简化了存储子系统设计
3)提高数据容错率,提高可用性
namenode(管理者):管理文件系统命名空间,维护文件系统树内所有文件和目录。这些信息以两个形式保存在本地磁盘:命名空间镜像文件和编辑日志文件。
client:代表用户通过namenode和datanode交互访问系统
datenode:文件系统的工作节点。存储并检索数据块(受nn调度)
namenode毁坏所有文件将丢失,保护机制:1备份组成文件系统元数持久状态的文件。2运行secondnamenode,防止编辑日志过大。一般在另一台计算机上运行。
工作机制:客户端要有增删改要求------namenode先记录到编辑日志-----然后再修改元数据----编辑日志逐渐增大-------secondnamenode向namenode请求是否需要合并(checkpoint)------1、定时时间到(1小时)2、数据满了100万条【任意一条件】------滚动正在写的日志-------edits001 再生成一个002空的 有增删改要求写到002--------然后加载到内存合并------生成新的Fsimage-------拷贝到nn------再命名Fsimage
shell操作:
hadoop dfs -put xiaokeai.txt /languid 上传
hadoop dfs -cat /languid/xiaokeai.txt查看
hadoop dfs -rm -r /languid/xiaokeai.txt删除
hadoop fs -moveFromLocal xiaokeai.txt /languid从本地传上
hadoop fs -get /languid/xiaokeai.txt /usr/local/hadoop从hdfs下载
hadoop dfs -ls /languid 查看目录
hdfs写数据流程:数据来了----hdfs客户端访问集群----创建FS客户端对象----向namenode申请(如果存在就直接不让申请)------响应上传-----返回datenode三个节点表示这三个节点存储-----创建fsoutput-----向datenode申请建立传输通道----应答成功-----传输packet
读数据流程: 访问集群----创建fs客户端对象----向namenode申请-------返回目标文件元数据----------向datenode1请求blk_1----传输数据-----向datanode2申请blk_2-----传输数据-----变成文件
yarn:将资源管理和作业调度分解为单独的进程,一个全局的ResourceManager和应用程序的ApplicationMaster
Rs和nodeManager构成计算框架。
Rs:处理client请求,监控NS、AM,启动AM,资源总分配调度
Ns:管理单节点资源,监控---返回给Rs/Scheduler,处理RM和AM的命令
AM:数据切分,为任务申请资源,任务监控容错
Container:资源抽象,封装多维度资源,内存、cpu、磁盘
Flume:大规模流数据导入Hdfs的工具,允许任何拓扑方式进行组织。
基于事物,保证数据传送和接受的一致性
可靠的,高容错,可升级,易管理可定制的
外结构:facebook产生的数据----被单个运行在服务器上的agent收集----各个agent汇集数据存入hdfs或Hbase
Flume事件:Flume数据传输最基本单元,一个转载数据字节和一个可选头部组成。
Flume Agent:独立的守护进程,从客户端或其他agent手机,迅速传给下个目的节点sink。
Agent由Source、Channel、sink组成,
Channel:短暂的存储容器,在source和sink间作为桥梁,保证数据收发的一致性,可以和任意数量source,sink组合,支持jdbc,file System
source:facebook等 sin:hdfs hbase
插件:Interceptors拦截器:source和channel之间 ,检查或更改FLume数据
channels Selectors:默认管道选择器:传递相同events,多路复用管道选择器:依据event头部选择管道
sink线程:用于负载平衡
可以和Kafka结合使用
Sqoop:为了从结构化存储设备批量导入HDFS中设计的,例如关系数据库。
底层用MqpReduce程序实现抽取、转换、加载,相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少ETl服务器资源使用,性能提升。
#!coding:utf-8 import sys from hdfs.client import Client import importlib importlib.reload(sys) client = Client("http://localhost:50070") # 读取hdfs文件内容,将每行存入数组返回 def read_hdfs_file(client, filename): # with client.read('samples.csv', encoding='utf-8', delimiter='\n') as reader: # for line in reader: # pass lines = [] with client.read(filename, encoding='utf-8', delimiter='\n') as reader: for line in reader: # pass # print line.strip() lines.append(line.strip()) return lines # 创建目录 def mkdirs(client, hdfs_path): client.makedirs(hdfs_path) # 删除hdfs文件 def delete_hdfs_file(client, hdfs_path): client.delete(hdfs_path) # 上传文件到hdfs def put_to_hdfs(client, local_path, hdfs_path): client.upload(hdfs_path, local_path, cleanup=True) # 从hdfs获取文件到本地 def get_from_hdfs(client, hdfs_path, local_path): client.download(hdfs_path, local_path, overwrite=False) # 追加数据到hdfs文件 def append_to_hdfs(client, hdfs_path, data): client.write(hdfs_path, data, overwrite=False, append=True) # 覆盖数据写到hdfs文件 def write_to_hdfs(client, hdfs_path, data): client.write(hdfs_path, data, overwrite=True, append=False) # 移动或者修改文件 def move_or_rename(client, hdfs_src_path, hdfs_dst_path): client.rename(hdfs_src_path, hdfs_dst_path) # 返回目录下的文件 def list(client, hdfs_path): return client.list(hdfs_path, status=False) get_from_hdfs(client,'/languid/xiaokeai.txt','/usr/local/hadoop')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号