
C 语言实现抽象数据类型(ADT)之链表
C 语言实现抽象数据类型(ADT)之链表
1 什么是链表?(懂跳)
C 语言本身自带了很多基本数据类型,每种基本数据类型的变量总是代表着某个数据,比如:我们通常用整型变量来计数,用浮点型变量来保存价格这样的数据……
int count; double price;
而有时候我们需要表示的数据很复杂,比如我们想要保存一件商品的价格的同时,也能够保存这件商品的名称,这个时候结构体就派上用场了。
struct Book { char bookName[100]; double bookPrice; }
而像这样的多元数据,往往不止一个,我们通常的做法是使用结构体数组。
struct Book books[100];
但结构体数组的元素个数是有上限的,而且数组开辟的内存空间是连续的,这样内存利用率不高。在实际开发过程中,数据个数通常都是不确定的,都是动态变化的。
所以可以使用C 语言的动态内存分配在程序运行期间,动态的为每个这样的数据开辟空间。
(struct Book*)malloc(sizeof(struct Book));
但这样又有一个问题,就是每为一个数据开辟内存空间,就需要使用一个指针变量来保存它的地址,而如果使用数组来保存这些指针,虽说指针数组占用空间比较小,但显然又回到了最初的问题,就是数据的个数是有上限的。
而如果也使用动态内存分配的方式存储指针,那么存储这些指针的内存空间又需要新的指针“跟踪”。
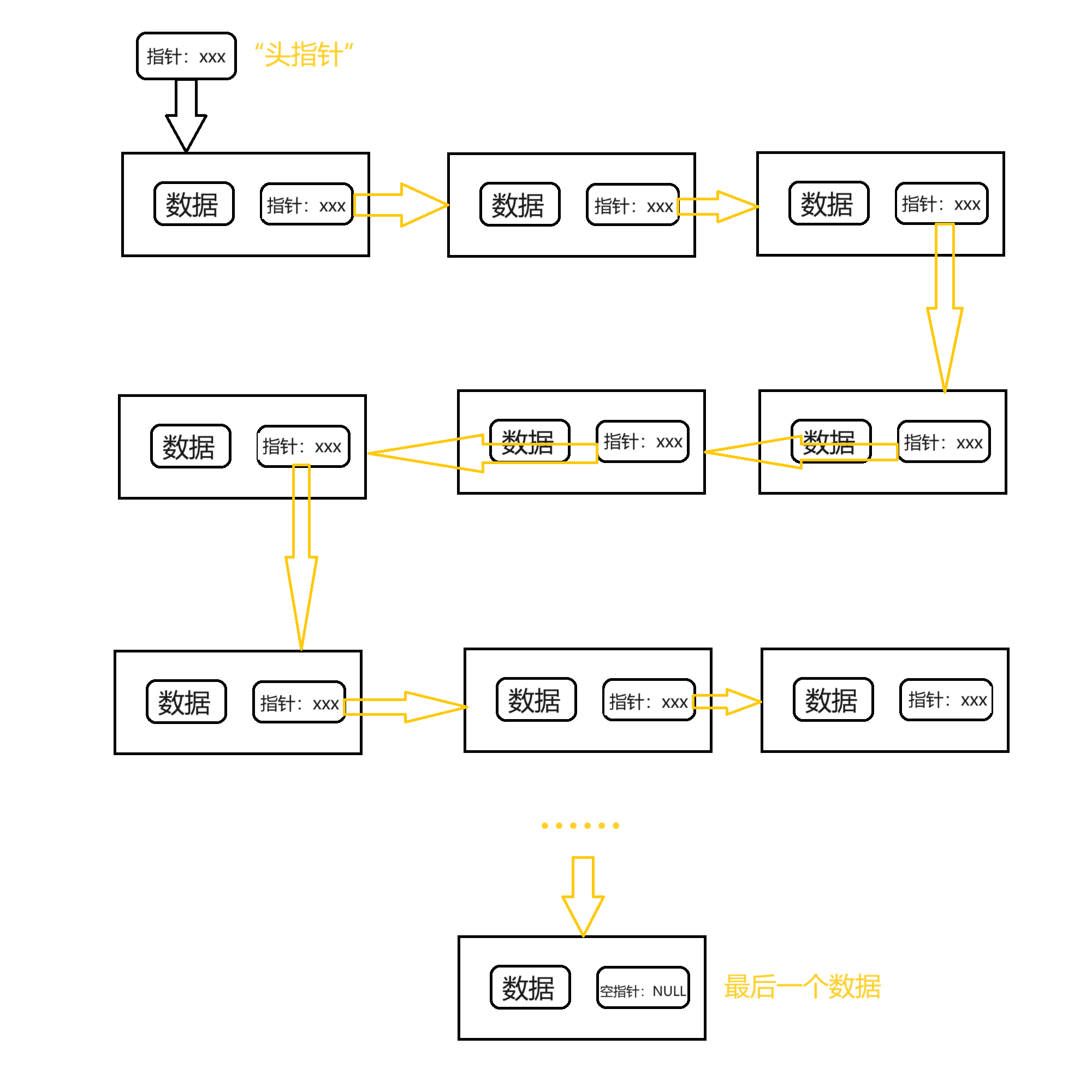
于是就有了链表。
我们可以在每为一个数据开辟空间的时候,把这个数据的内存地址保存在上一个数据中,这样一来,只有第一个数据的指针需要另外保存,这个指针叫做头指针。
struct Book { char bookName[100]; double bookPrice; struct Book* next; } //每一个块数据中都存储着下一个数据的内存地址 //如果是最后一个,把其中“下一个”的指针赋为NULL即可 struct Book* head; //只需要一个头指针定位整条链表的头即可
这样一来,通过动态内存分配为每一个数据分配的内存空间,都被巧妙的链接了起来,于是把这种数据结构称为链表。把其中的每一块内存空间又形象的称为一个节点。
2 数据的封装
为了提高代码的复用性,我们在创建链表之前,应该对元数据进行封装。
我们可以将元数据的定义放在一个头文件中。
/*MyType.h*/ #pragma once struct MyType { /*......*/ }; typedef struct MyType Item;
这样元数据就被封装成了Item类型。后面如果我们想要修改元数据类型,只需要需改此文件中的定义即可。
然后分别通过LinkedList.h和LinkedList.c两个文件来实现链表。
/*LinkedList.h*/ #pragma once #include "MyType" //包含Item的定义 #include <stdbool.h> //使用bool //封装节点 typedef struct listNode { Item item; struct listNode* next; }Node; //抽象:链表类型,用于存储链表头指针和其他信息 typedef struct linkedList { Node* head; //头指针,必须,不仅定位头节点,也定位整个链表 Node* tail; //尾指针:为了方便在链表末尾追加节点,不是必须 bool isNull; //存储一个链表是否为空的布尔值 unsigned nodeCount; //存储链表中的节点数 }List;
如此一来,就完成了从元数据到链表的封装,封装不是必须的。
3 实现接口API
为什么要把链表封装成一种抽象数据类型(ADT)?在开发中,数据结构就像是,在造汽车中的轮胎一样,几乎是开发过程中必然会使用的工具,我们为了追求开发效率,必然不可能每次开发都去“造轮子”,所以把链表封装成一种抽象数据类型(ADT)可以大大简化后续的开发工作。
所以我们把对链表的所有操作都抽象得封装成函数,即把它当成一种数据类型,就如同C语言的内置类型一样。
每一种数据类型,都有属性和相关操作这两个特征,比如int类型的属性就是表示一个整数,相关操作有加减乘除等。
而链表的属性就是表示多个、内存空间不连续的相同类型的数据。和数组的概念类似(数组也是一种数据结构),只不过链表要比数据灵活,将其抽象封装的一个目的,就是能像使用数组那样简单而高效的使用链表这种数据结构。
链表的操作和数组有所不同,它更加复杂。它所有的操作都需要借助函数来完成。
- 初始化链表
void initList(List* const pList);//const 表示这个函数不会改变plist的值
- 判断一个链表是否为空
bool isListEmpty(const List* const pList);//const分别表示不会改变*pList和pList的值
- 获取一个链表中元数据的数量(节点数)
unsigned itemsCountOfList(const List* const pList);
- 在链表末尾添加一个元素
bool appendItemToList(List* const pList, const Item* const pItem);
- 清空一个链表
void clearList(List* const pList);
- 对链表中的每一项都执行某个函数(遍历链表)
void traverseList(const List* const pList, void(*pfun)(Item* pItem));
由于元数据的不同,所以不涉及任何对元数据的操作,这必须由实现元数据的人来写,或者说与元数据的定义写在一起。
等等……
关于链表的操作不止这些,这里只演示这些。
将这些接口函数的声明写在LinkedList.h中,然后在LinkedList.c中实现。这样做的好处是,隐藏具体实现,将接口对外公开;后续使用链表时,只需查看头文件即可一目了然。
/*LinkedList.c*/ #include "LinkedList.h" #include <stdlib.h> #include <stdbool.h> void initList(List* const pList) { if (pList != NULL) { //防止访问空指针 pList->head = NULL; pList->tail = NULL; pList->isNull = true; pList->nodeCount = 0; } } bool isListEmpty(const List* const pList) { return pList->isNull; } unsigned itemsCountOfList(const List* const pList) { return pList->nodeCount; } bool appendItemToList(List* const pList, const Item* const pNewItem) { if (pList != NULL) { Node* pNewNode = (Node*)malloc(sizeof(Node)); if (pNewNode != NULL) { pNewNode->item = *pNewItem; pNewNode->next = NULL; if (pList->head == NULL) { pList->head = pNewNode; pList->isNull = false; } else { pList->tail->next = pNewNode; } pList->tail = pNewNode; pList->nodeCount++; return true; } } return false; } void traverseList(const List* const pList, void(*pfun)(Item* item)) { Node* pNode = pList->head; while (pNode != NULL) { pfun(&pNode->item); pNode = pNode->next; } } void clearList(List* const pList) { if (pList != NULL) { Node* pNode = pList->head; while (pList->head != NULL) { pList->head = pNode->next; free(pNode); pNode = pList->head; } } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】