
当源代码“素颜”上镜:Go/Python编译器逆向工程线索链
背景
本文主要探讨在编程中遇到的某些疑难杂症,可以通过查看编译生成的低级别语言,来逆向解释上层语言的困惑。在纷繁复杂的代码世界中,源码分析是我们工具箱的一把利器,帮助我们解开代码底层的本质,去探寻真实的计算机实现。
本文以Golang和Python为例,各探寻一个简单的案例,抛出逆向分析的方法。
Python 逆向分析
a = 1
def test1():
print("test1-1", a)
def test2():
print("test2-1", a)
a = 3
print("test2-2", a)
test1()
test2()
看这个简单的案例,不妨停留一下,猜一下test1、test2执行结果是什么?
test1-1 1
test2-1 1
test2-2 3
这应该是大多数人的想法,我们接触Python,直观感受Python是解释执行,一行一行的执行,在执行test2的时候,第一次输出a用的全局变量a=1,第二次由于局部变量优先输出a=3。
下面来揭晓答案:
test1-1 1
Traceback (most recent call last):
File "local_var.py", line 11, in <module>
test2()
File "local_var.py", line 6, in test2
print("test2-1", a)
UnboundLocalError: local variable 'a' referenced before assignment
非常意外! test1的结果毫无疑问,test2执行报错,报错指明a变量在分配之前就被引用了,这是什么问题呢?我们可以借助Python生成的字节码了解Python底层的机制来探寻这个问题。
生成.pyc字节码
生成python字节码指令:
python -m py_compile local_var.py
加载和分析.pyc字节码
import marshal
import dis
import sys
# 加载.pyc文件
with open('local_var.cpython-39.pyc', 'rb') as f:
f.seek(16) # 跳过Python字节码文件的头部信息
code_obj = marshal.load(f)
# 反汇编代码对象
dis.dis(code_obj)
字节码内容分析
Disassembly of <code object test1 at 0x1046895b0, file "local_var.py", line 3>:
4 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('test1-1')
4 LOAD_GLOBAL 1 (a)
6 CALL_FUNCTION 2
8 POP_TOP
10 LOAD_CONST 0 (None)
12 RETURN_VALUE
Disassembly of <code object test2 at 0x1046929d0, file "local_var.py", line 5>:
6 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('test2-1')
4 LOAD_FAST 0 (a)
6 CALL_FUNCTION 2
8 POP_TOP
7 10 LOAD_CONST 2 (3)
12 STORE_FAST 0 (a)
8 14 LOAD_GLOBAL 0 (print)
16 LOAD_CONST 3 ('test2-2')
18 LOAD_FAST 0 (a)
20 CALL_FUNCTION 2
22 POP_TOP
24 LOAD_CONST 0 (None)
26 RETURN_VALUE
阅读字节码,找到并对比test1、test2的代码,我们可以得知:
- 同样加载a变量的数据,
test1用的LOAD_GLOBAL用来加载全局变量,test2用的LOAD_FAST加载局部变量。 - python并非逐行执行,而是通过编译(语法分析、语意分析、构造抽象语法树等)确定语意,确定a变量的来源
而test2中通过编译确定a为局部变量,但定义和赋值在使用之后,于是报错。
Golang逆向分析
性能优化,按照经验将循环中c.b.a这种访问,提前储存,循环中直接访问可以提高效率。但在Golang中做了这个优化,通过Benchmark测试后,发现并没有效果,于是猜测,Golang在编译过程中将这种访问做了存储优化。为了验证这个猜想,编写如下Golang代码:
package main
import (
"testing"
)
type TA struct {
a int
}
type TB struct {
a TA
}
type TC struct {
b TB
}
func getAdd(n int, m int) int {
return n*n*n + m
}
func Benchmark_direct(b *testing.B) {
s := 0
c := TC{b: TB{a: TA{a: 2}}}
for n := 0; n < b.N; n++ {
s = getAdd(c.b.a.a, s)
}
b.Log("Benchmark_direct", s)
}
func Benchmark_cache(b *testing.B) {
s := 0
c := TC{b: TB{a: TA{a: 2}}}
tmp := c.b.a.a
for n := 0; n < b.N; n++ {
s = getAdd(tmp, s)
}
b.Log("Benchmark_cache", s)
}
测试
benchmark测试结果如下
Mac go % go test -bench=. duration_test.go
goos: darwin
goarch: arm64
cpu: Apple M4
Benchmark_direct-10 1000000000 0.2397 ns/op
--- BENCH: Benchmark_direct-10
duration_test.go:27: Benchmark_direct 8
duration_test.go:27: Benchmark_direct 800
duration_test.go:27: Benchmark_direct 80000
duration_test.go:27: Benchmark_direct 8000000
duration_test.go:27: Benchmark_direct 800000000
duration_test.go:27: Benchmark_direct 8000000000
Benchmark_cache-10 1000000000 0.2279 ns/op
--- BENCH: Benchmark_cache-10
duration_test.go:37: Benchmark_cache 8
duration_test.go:37: Benchmark_cache 800
duration_test.go:37: Benchmark_cache 80000
duration_test.go:37: Benchmark_cache 8000000
duration_test.go:37: Benchmark_cache 800000000
duration_test.go:37: Benchmark_cache 8000000000
Benchmark_noop-10 1000000000 0.2276 ns/op
运行结果:
Benchmark_direct、Benchmark_cache中循环一次的执行平均分别为0.2279ns、0.2276ns,两个函数运行时间结果几乎没有差别。
生成代码分析
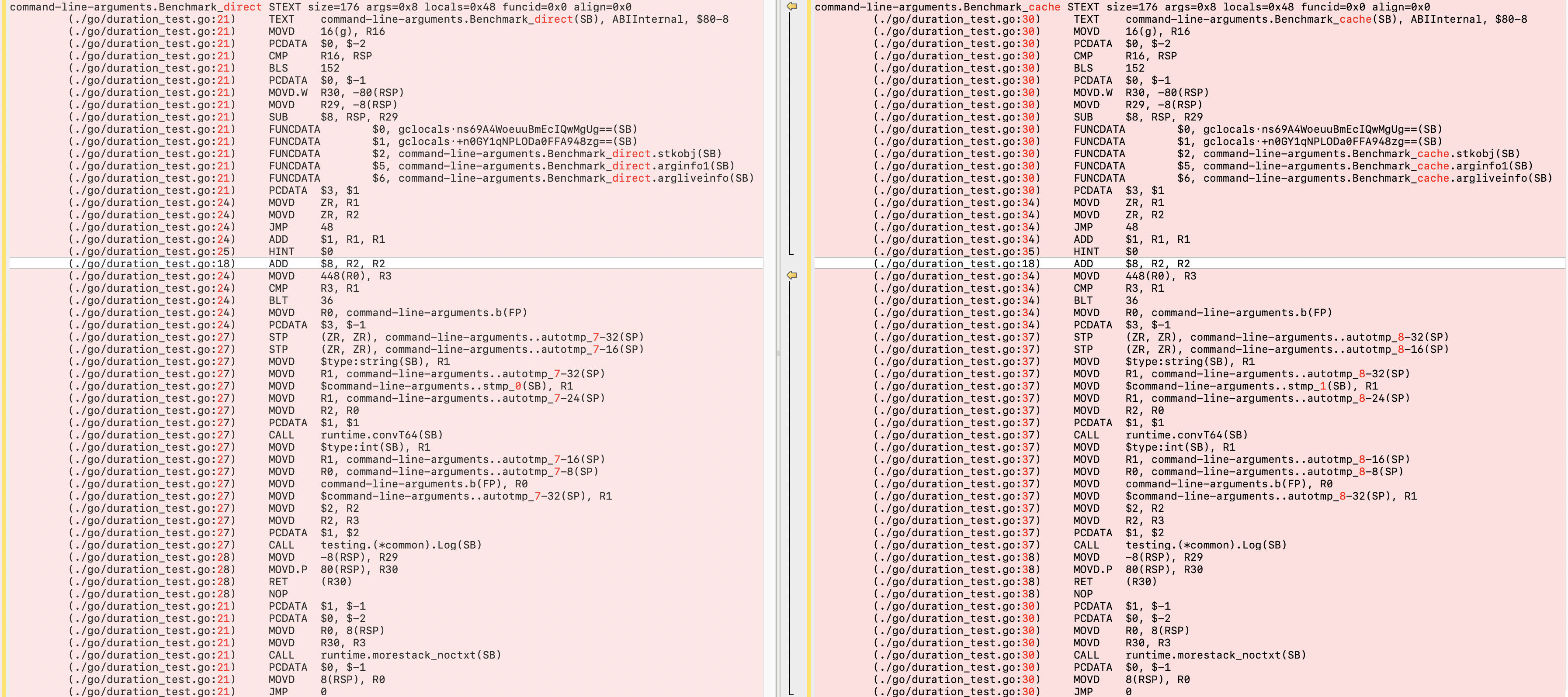
c.b.a这个操作有缓存,我们从Golang编译后的低级代码找答案,生成指令:
nohup go test -gcflags="-S" duration_test.go > duration_test_src.txt
两个函数diff结果如下图,除了函数名称、代码行号、变量位置外,源代码一致,说明编译器在编译环节所有优化,对a.b.c循环中的访问做了优化,另外还对getAdd函数做了内联处理,更多细节这里不继续展开(可以通过LLM来解析解释后的结果),从而缓存优化问题得到确认。
逆向分析其它用途
从黑盒到白盒
编译结果分析打破了高级语言与机器代码之间的抽象层,使开发者能够以“机器视角”理解代码的真实行为,推动优化从经验驱动转向数据驱动。
逆向调试
在无法通过源码调试时(如生产环境崩溃),直接分析汇编定位问题。
性能分析
结合编译分析、性能剖析(Profiling)和基准测试,构建从源码到落地的全链路优化体系,覆盖开发、测试、部署全生命周期。
源代码加密
通过对编译、可执行文件加载的控制,可以实现对产生的编译结果加密,防止源代码泄露。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号