


Python+selenium WebDriver API
正文
2.1 操作元素基本方法
前言 前面已经把环境搭建好了,从这篇开始,正式学习selenium的webdriver框架。我们平常说的 selenium自动化,其实它并不是类似于QTP之类的有GUI界面的可视化工具,我们要学的是webdriver框架的API。 本篇主要讲如何用Python调用webdriver框架的API,对浏览器做一些常规的操作,如打开、前进、后退、刷新、设置窗口大小、截屏、退出等操作。
2.1.1 打开网页
1.从selenium里面导入webdriver模块 2.打开Firefox浏览器(Ie和Chrome对应下面的) 3.打开百度网址

2.1.2 设置休眠
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作 2.导入time模块,time模块是Python自带的,所以无需下载 3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数

2.1.3 页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新 2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮

2.1.4 页面切换
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮。
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮。
2.1.5 设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960 2.也可以最大化窗口

2.1.6 截屏
1. 打开网站之后,也可以对屏幕截屏 2.截屏后设置指定的保存路径+文件名称+后缀

2.1.7 退出
1.退出有两种方式,一种是close;另外一种是quit。 2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口。 3.quit用于结束进程,关闭所有的窗口。 4.最后结束测试,要用quit。quit可以回收c盘的临时文件。

掌握了浏览器的基本操作后,接下来就可以开始学习元素定位了,元素定位需要有一定的html基础。没有基础的可以按下浏览器的F12快捷键先看下html的布局,先了解一些就可以了。
2.1.8 加载浏览器配置
启动浏览器后,发现右上角安装的插件不见了,这是因为webdriver启动浏览器时候,是开的一个虚拟线程,跟手工点开是有区别的,selenium的一切操作都是模拟人工(不完全等于人工操作)。
加载Firefox配置
有小伙伴在用脚本启动浏览器时候发现原来下载的插件不见了,无法用firebug在打开的页面上继续定位页面元素,调试起来不方便 。加载浏览器配置,需要用FirefoxProfile(profile_directory)这个类来加载,profile_directory既为浏览器配置文件的路径地址。
一、遇到问题 1.在使用脚本打开浏览器时候,发现右上角原来下载的插件firebug不见了,到底去哪了呢? 2.用脚本去打开浏览器时候,其实是重新打开了一个进程,跟手动打开浏览器不是一个进程。 所以没主动加载插件,不过selenium里面其实提供了对应的方法去打开,只是很少有人用到。
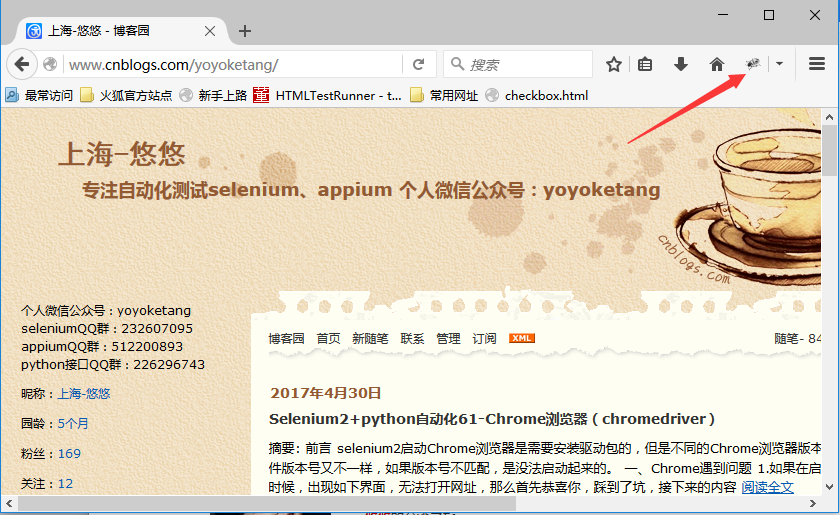
二、FirefoxProfile 1.要想了解selenium里面API的用法,最好先看下相关的帮助文档打开cmd窗口, 输入如下信息:
->python ->from selenium import webdriver ->help(webdriver.FirefoxProfile)
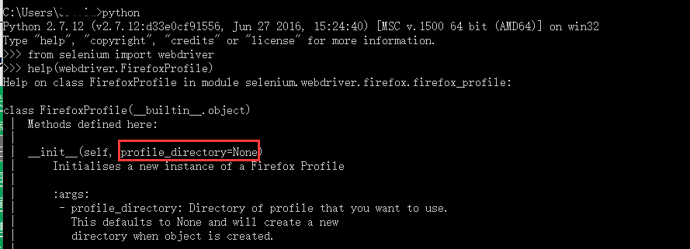
Help on class FirefoxProfile in module selenium.webdriver.firefox.firefox_profile: class FirefoxProfile(builtin.object) | Methods defined here:
| | init(self, profile_directory=None) | Initialises a new instance of a Firefox Profile | | :args: | - profile_directory: Directory of profile that you want to use. | This defaults to None and will create a new | directory when object is created.
2.翻译过来大概意思是说,这里需要profile_directory这个配置文件路径的参数 3.profile_directory=None,如果没有路径,默认为None,启动的是一个新的,有的话就加载指定的路径。
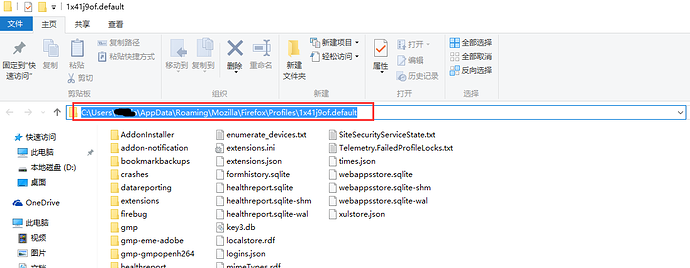
三、profile_directory 1.问题来了:Firefox的配置文件地址如何找到呢? 2.打开Firefox点右上角设置>?(帮助)>故障排除信息>显示文件夹
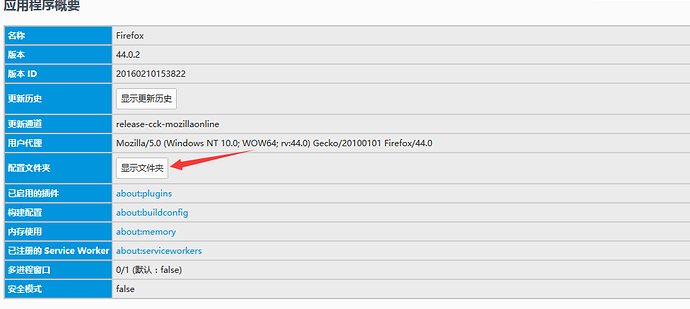
3.打开后把路径复制下来就可以了: C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default
四、启动配置文件 1.由于文件路径存在字符:\ ,反斜杠在代码里是转义字符,这个有点代码基础的应该都知道。 不懂什么叫转义字符的,自己翻书补下基础吧! 2.遇到转义字符,为了不让转义,有两种处理方式: 第一种:\ (前面再加一个反斜杠)
第二种:r”\"(字符串前面加r,使用字符串原型)

五、参考代码:


# coding=utf-8
from selenium import webdriver
# 配置文件地址
profile_directory = r'C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
# 加载配置配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
其实很简单,在调用浏览器的前面,多加2行代码而已,主要是要弄清楚原理。
2.2 常用8种元素定位(Firebug和firepath)
前言 元素定位在firefox上可以安装Firebug和firepath辅助工具进行元素定位。
2.2.1 环境准备
1.浏览器选择:Firefox 2.安装插件:Firebug和FirePath(设置》附加组件》搜索:输入插件名称》下载安装后重启浏览器) 3.安装完成后,页面右上角有个小爬虫图标 4.快速查看xpath插件:XPath Checker这个可下载,也可以不用下载 5.插件安装完成后,点开附加组件》扩展,如下图所示

2.2.2 查看页面元素
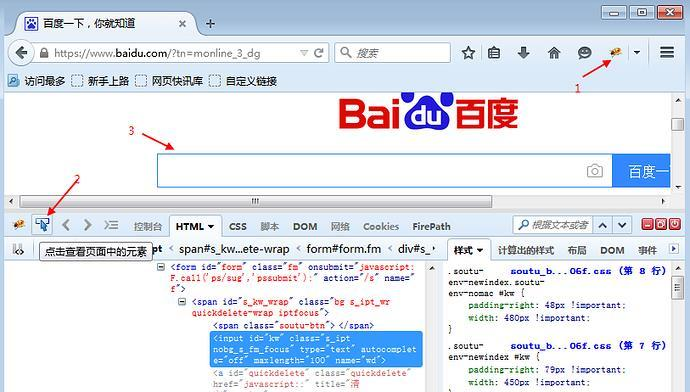
以百度搜索框为例,先打开百度网页 1.点右上角爬虫按钮 2.点左下角箭头 3.将箭头移动到百度搜索输入框上,输入框高亮状态 4.下方红色区域就是单位到输入框的属性:
<input id="kw" class="s_ipt" type="text" autocomplete="off" maxlength="100" name="wd">
2.2.3 find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素。 2.定位到搜索框后,用send_keys()方法,输入文本。

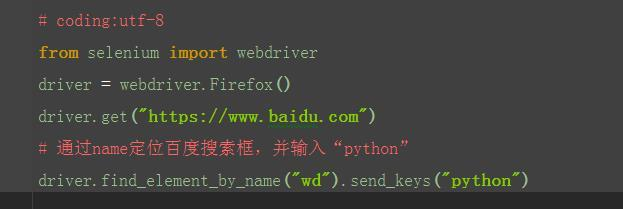
2.2.4 find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name="wd",这里可以通过它的name属性单位到这个元素。 说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
2.2.5 find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class="s_ipt",这里可以通过它的class属性定位到这个元素。

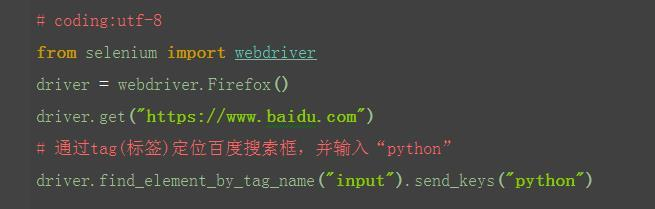
2.2.6 find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。 2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。
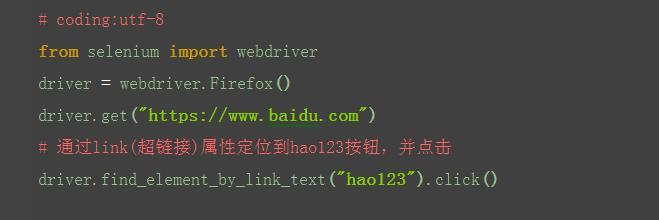
2.2.7 find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮

查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com">hao123</a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:
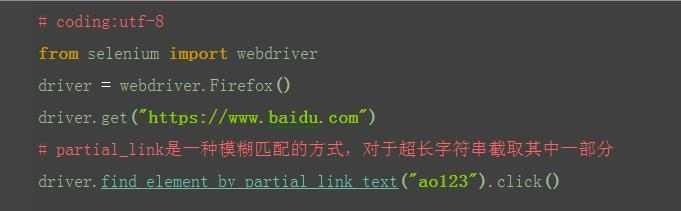
2.2.8 find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到
2.2.9 find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。 2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的xpath。

3.按照上图的步骤,在FirePath插件里copy对应的xpath地址。

2.2.10 find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解 2.打开FirePath插件选择css 3.定位到后如下图红色区域显示
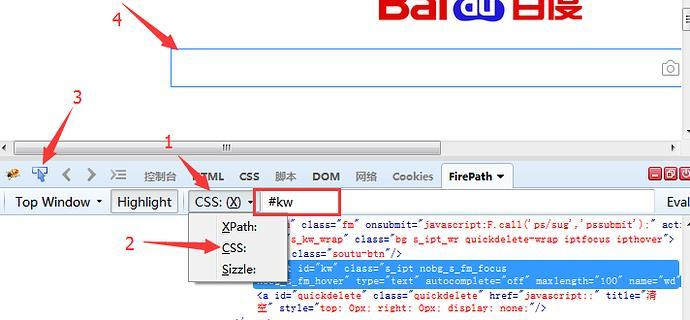
总结: selenium的webdriver提供了18种(注意是18种,不是8种)的元素定位方法,前面8种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。 前八种是大家都熟悉的,经常会用到的:
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式(2.8和2.27章节有介绍)
9.id复数定位find_elements_by_id(self, id_)
10.name复数定位find_elements_by_name(self, name)
11.class复数定位find_elements_by_class_name(self, name)
12.tag复数定位find_elements_by_tag_name(self, name)
13.link复数定位find_elements_by_link_text(self, text)
14.partial_link复数定位find_elements_by_partial_link_text(self, link_text)
15.xpath复数定位find_elements_by_xpath(self, xpath)
16.css复数定位find_elements_by_css_selector(self, css_selector
这两种是参数化的方法,会在以后搭建框架的时候,会经常用到PO模式,才会用到这个参数化的方法(将会在4.2有具体介绍)
17.find_element(self, by='id', value=None)
18.find_elements(self, by='id', value=None)
2.3 xpath定位
前言 在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到。这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法。 什么是xpath呢? 官方介绍:XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言。反正小编看这个介绍是云里雾里的,通俗一点讲就是通过元素的路径来查找到这个元素的。
2.3.1 xpath:属性定位
1.xptah也可以通过元素的id、name、class这些属性定位,如下图:
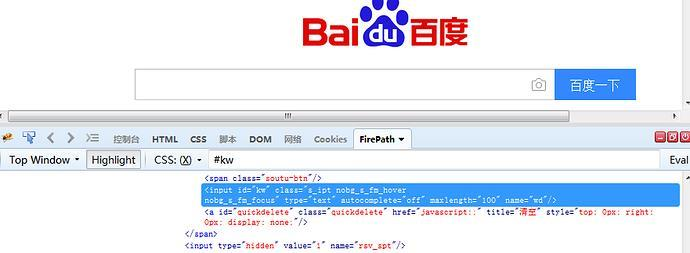
2.于是可以用以下xpath方法定位

2.3.2 xpath:其它属性
1.如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
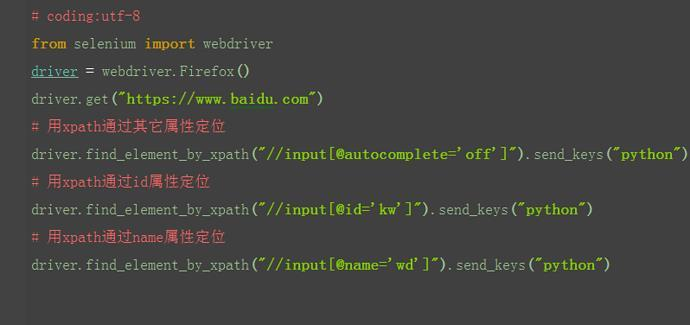
2.3.3 xpath:标签
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点 2.如果不想制定标签名称,可以用*号表示任意标签 3.如果想制定具体某个标签,就可以直接写标签名称
2.3.4 xpath:层级
1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)。 2.找到它老爸后,再找下个层级就能定位到了。
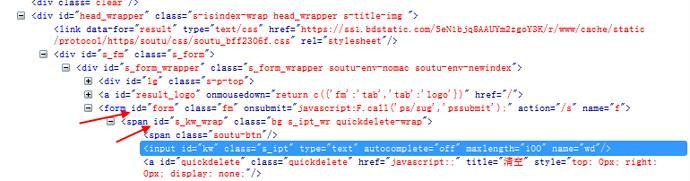
3.如上图所示,要定位的是input这个标签,它的老爸的id=s_kw_wrap。 4.要是它老爸的属性也不是很明显,就找它爷爷id=form。 5.于是就可以通过层级关系定位到。

2.3.5 xpath:索引
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。 2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。 3.如下图三胞胎兄弟。

4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)。

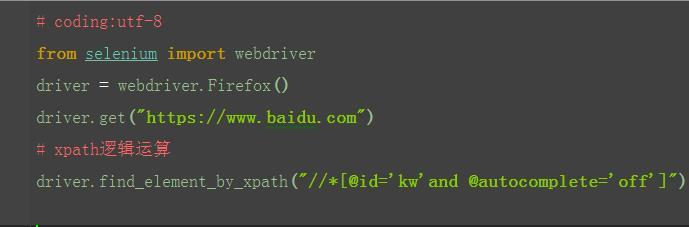
2.3.6 xpath:逻辑运算
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not) 2.一般用的比较多的是and运算,同时满足两个属性
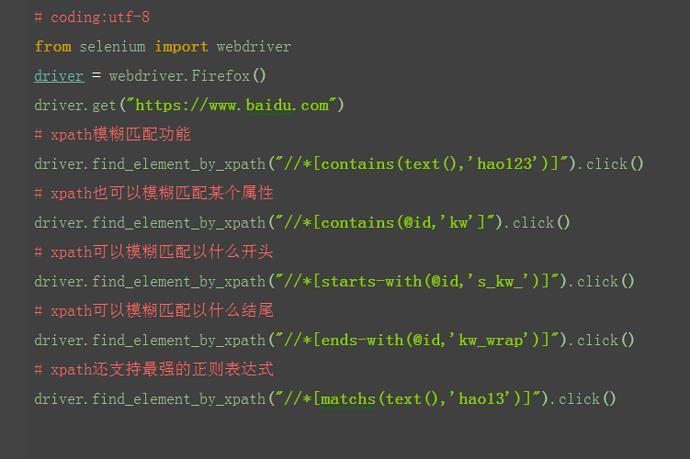
2.3.7 xpath:模糊匹配
1.xpath还有一个非常强大的功能,模糊匹配。 2.掌握了模糊匹配功能,基本上没有定位不到的。 3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。
可以把xpath看成是元素定位界的屠龙刀。武林至尊,宝刀xpath,css不出,谁与争锋?下节课将亮出倚天剑css定位。
2.4 CSS定位
前言 大部分人在使用selenium定位元素时,用的是xpath定位,因为xpath基本能解决定位的需求。css定位往往被忽略掉了,其实css定位也有它的价值,css定位更快,语法更简洁。 这一篇css的定位方法,主要是对比上一篇的xpath来的,基本上xpath能完成的,css也可以做到。两篇对比学习,更容易理解。 2.4.1 css:属性定位 1.css可以通过元素的id、class、标签这三个常规属性直接定位到 2.如下是百度输入框的的html代码:
<input id="kw" class="s_ipt" type="text" autocomplete="off" maxlength="100" name="wd"/>
3.css用#号表示id属性,如:#kw 4.css用.表示class属性,如:.s_ipt 5.css直接用标签名称,无任何标示符,如:input

2.4.2 css:其它属性
1.css除了可以通过标签、class、id这三个常规属性定位外,也可以通过其它属性定位 2.以下是定位其它属性的格式
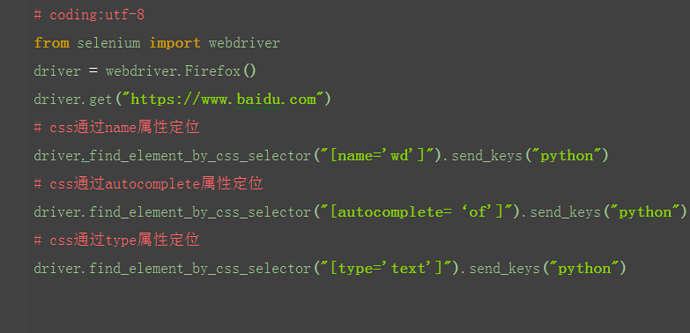
2.4.3 css:标签
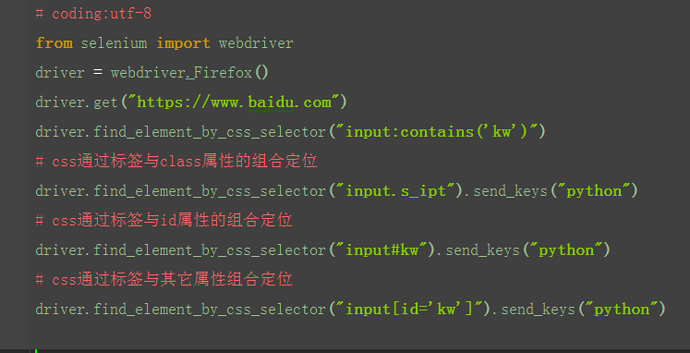
1.css页可以通过标签与属性的组合来定位元素
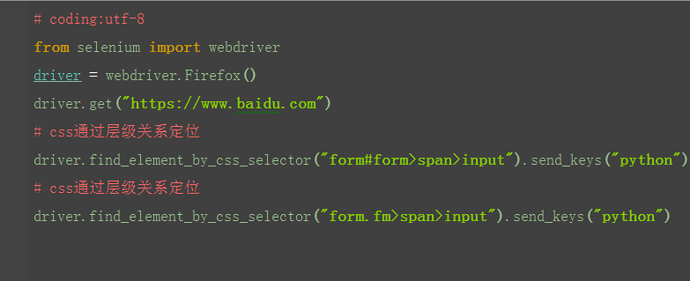
2.4.4 css:层级关系
1.在前面一篇xpath中讲到层级关系定位,这里css也可以达到同样的效果 2.如xpath:
//form[@id='form']/span/input和 //form[@class='fm']/span/input也可以用css实现
2.4.5 css:索引
1.以下图为例,跟上一篇一样:
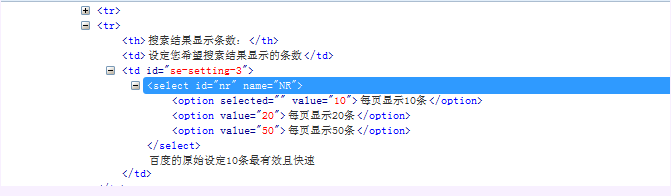
2.css也可以通过索引option:nth-child(1)来定位子元素,这点与xpath写法用很大差异,其实很好理解,直接翻译过来就是第几个小孩。
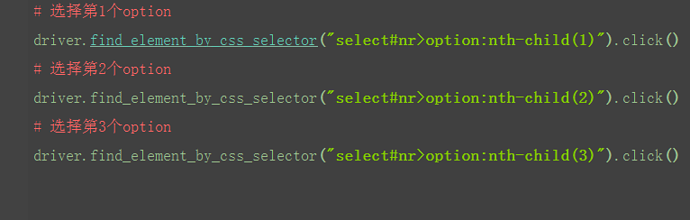
2.4.6 css:逻辑运算
1.css同样也可以实现逻辑运算,同时匹配两个属性,这里跟xpath不一样,无需写and关键字

2.4.7 css:模糊匹配
1.css的模糊匹配contains('xxx'),网上虽然用各种资料显示能用,但是小编亲自试验了下,一直报错。 2.在各种百度后找到了答案:you can't do this withCSS selectors, because there is no such thing as:contains() in CSS. It was a proposal that was abandoned years ago. 非常遗憾,这个语法已经被抛弃了,所以这里就不用管这个语法了。 css语法远远不止上面提到的,还有更多更强大定位策略,有兴趣的可以继续深入研究。官方说法,css定位更快,语法更简洁,但是xpath更直观,更好理解一些。
2.5 SeleniumBuilder辅助定位元素
前言 对于用火狐浏览器的小伙伴们,你还在为定位元素而烦恼嘛? 上古神器Selenium Builder来啦,哪里不会点哪里,妈妈再也不用担心我的定位元素问题啦!(但是也不是万能,基本上都能覆盖到)
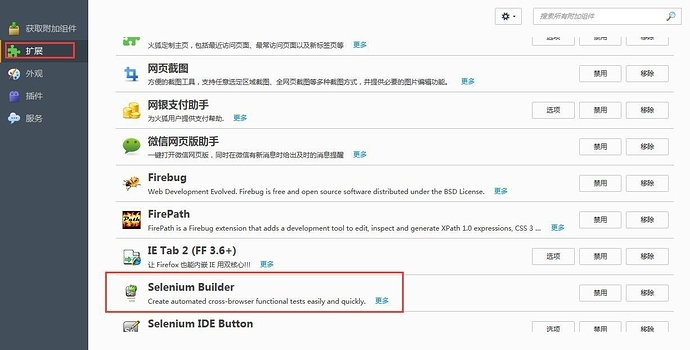
2.5.1 安装Selenium Builder
在火狐浏览器的附加组件中搜索添加Selenium Builder即可。安装好后如下图所示:
2.5.2 直接运用
1.打开你要测试的URL或者打开插件后输入你要测试的URL,如下图

2.点击后弹出一个弹窗,如下图:
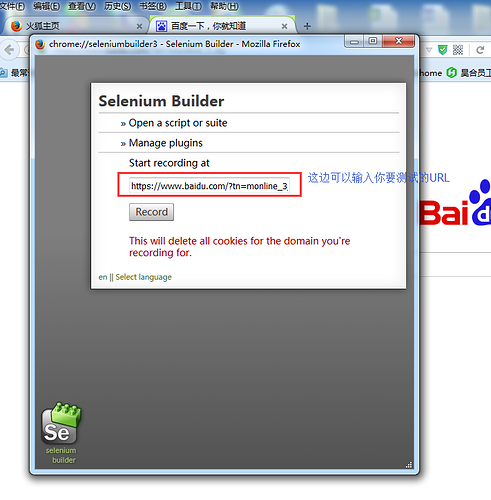
注:如果你是直接在你要测的网页页面打开这个插件时,selenium builder会直接获取你要测的URL
3.点击record:
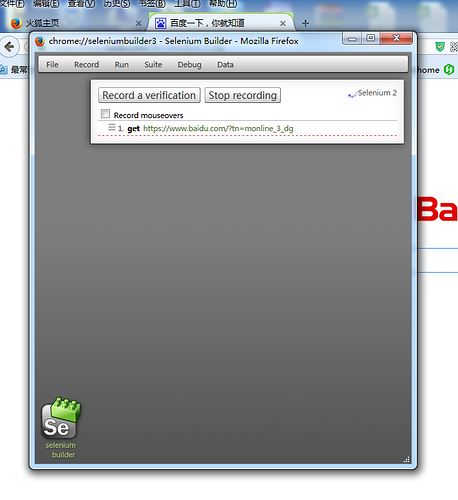
然后你就可以哪里不会点哪里了。这里举个例子:
2.5.3 实践案例
1.百度首页,点击百度一下,然后点击登录,再一次点击账号和密码输入框,让我们来看看结果。
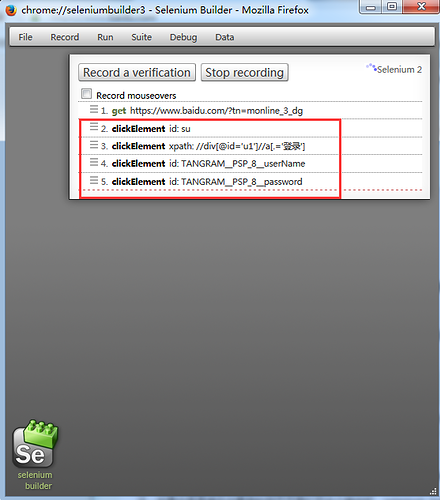
2.这里没有展开,点击展开后可以发现定位该元素的多种方法
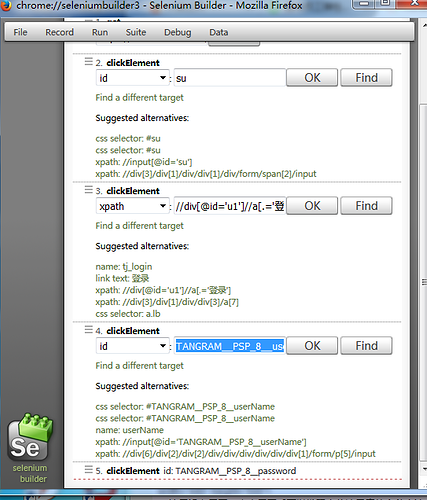
直接选择你想要的方法复制粘贴即可,不用的话直接关掉弹窗即可。
2.6 操作元素(键盘和鼠标事件)
前言 在前面的几篇中重点介绍了一些元素的定位方法,定位到元素后,接下来就是需要操作元素了。本篇总结了web页面常用的一些操作元素方法,可以统称为行为事件 有些web界面的选项菜单需要鼠标悬停在某个元素上才能显示出来(如百度页面的设置按钮)。
2.6.1 简单操作
1.点击(鼠标左键)页面按钮:click() 2.清空输入框:clear() 3.输入字符串:send_keys() 4.send_keys()如果是发送中文的,前面需加u,如:u"中文",因为这里是输入到windows系统了,windows系统是GBK编码,我们的脚本是utf-8,需要转码为Unicode国际编码,这样才能识别到。
2.6.2 submit提交表单
1.在前面百度搜索案例中,输入关键字后,可以直接按回车键搜索,也可以点搜索按钮搜索。 2.submit()一般用于模拟回车键。

2.6.3 键盘操作
1.selenium提供了一整套的模拟键盘操作事件,前面submit()方法如果不行的话,可以试试模拟键盘事件 2.模拟键盘的操作需要先导入键盘模块:from selenium.webdriver.common.keysimport Keys 3.模拟enter键,可以用send_keys(Keys.ENTER)

4.其它常见的键盘操作: 键盘F1到F12:send_keys(Keys.F1)把F1改成对应的快捷键:
复制Ctrl+C:send_keys(Keys.CONTROL,'c')
粘贴Ctrl+V:send_keys(Keys.CONTROL,'v')
全选Ctrl+A:send_keys(Keys.CONTROL,'a')
剪切Ctrl+X:send_keys(Keys.CONTROL,'x')
制表键Tab: send_keys(Keys.TAB)
这里只是列了一些常用的,当然除了键盘事件,也有鼠标事件。
2.6.4 鼠标悬停事件
1.鼠标不仅仅可以点击(click),鼠标还有其它的操作,如:鼠标悬停在某个元素上,鼠标右击,鼠标按住某个按钮拖到 2.鼠标事件需要先导入模块:from selenium.webdriver.common.action_chainsimport ActionChains perform() 执行所有ActionChains中的行为; move_to_element() 鼠标悬停。 3.这里以百度页面设置按钮为例:
4.除了常用的鼠标悬停事件外,还有 右击鼠标:context_click() 双击鼠标:double_click() 依葫芦画瓢,替换上面案例中对应的鼠标事件就可以了 selenium提供了一整套完整的鼠标和键盘行为事件,功能还是蛮强大滴。下一篇介绍多窗口的情况下如何处理。
2.7 多窗口、句柄(handle)
前言 有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就得先切换窗口了。获取窗口的唯一标识用句柄表示,所以只需要切换句柄,我们就能在多个页面上灵活自如的操作了。 一、认识多窗口 1.打开赶集网:http://bj.ganji.com/,点击招聘求职按钮会发现右边多了一个窗口标签
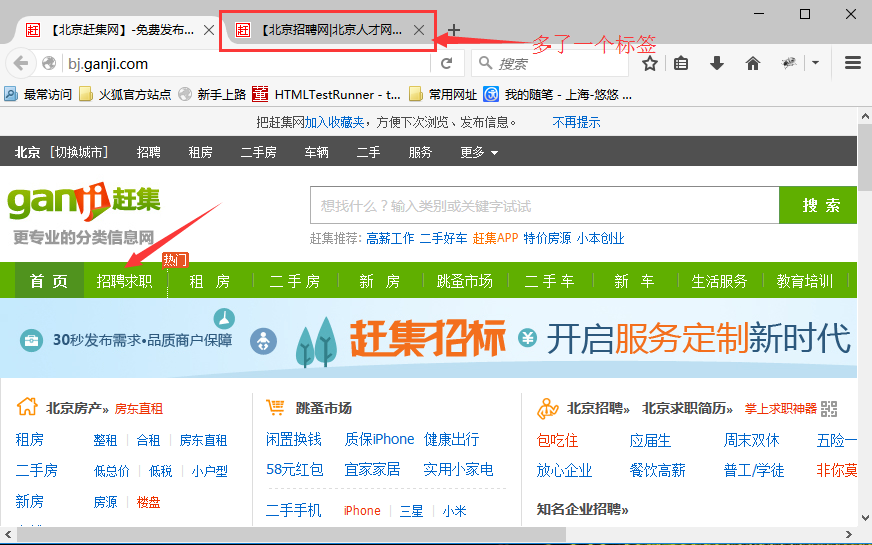
2.我们用代码去执行点击的时候,发现界面上出现两个窗口,如下图这种情况就是多窗口了。
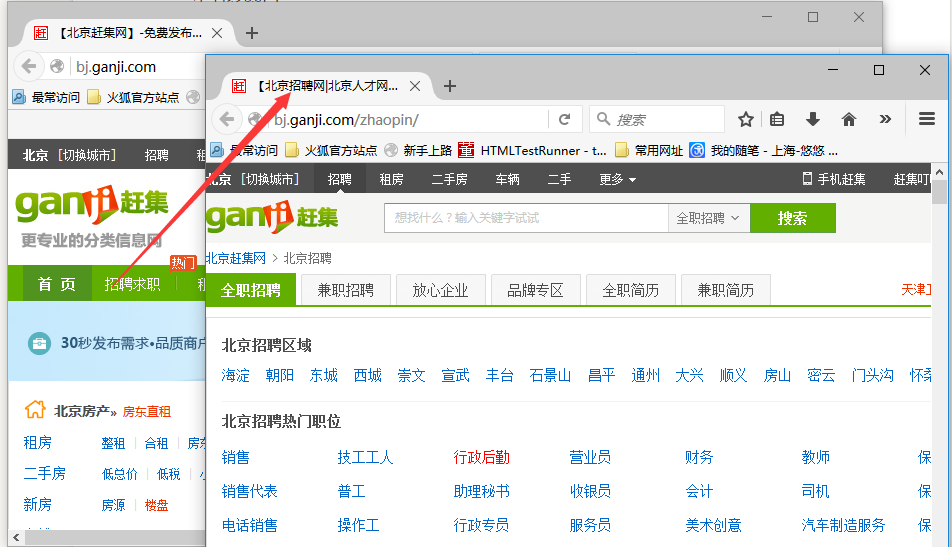
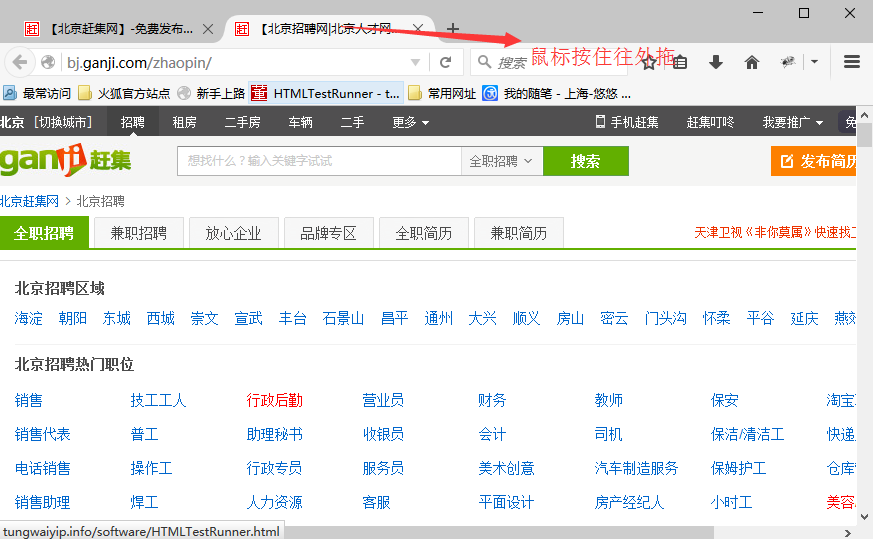
3.到这里估计有小伙伴纳闷了,手工点击是2个标签,怎么脚本点击就变成2个窗口了,这个在2.1里面讲过,脚本执行是不加载配置的,手工点击是浏览器默认设置了新窗口打开方式为标签,这里用鼠标按住点二个标签,拖拽出来,也就变成2个标签了,是一回事。
二、获取当前窗口句柄
1.元素有属性,浏览器的窗口其实也有属性的,只是你看不到,浏览器窗口的属性用句柄(handle)来识别。
2.人为操作的话,可以通过眼睛看,识别不同的窗口点击切换。但是脚本没长眼睛,它不知道你要操作哪个窗口,这时候只能句柄来判断了。
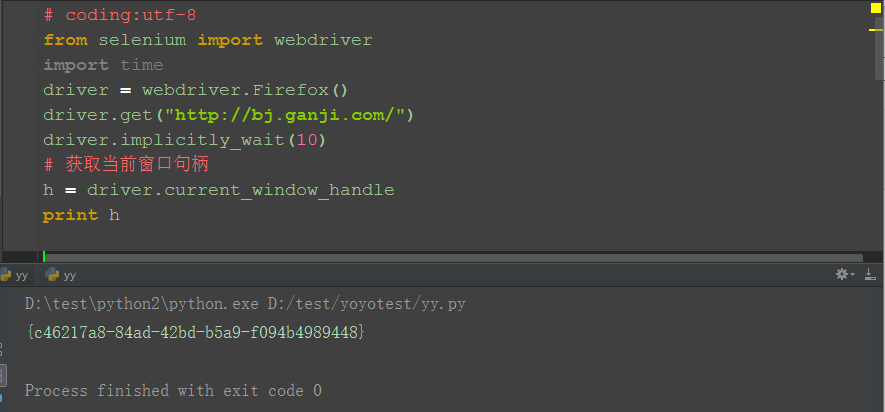
3.获取当前页面的句柄:driver.current_window_handle
三、获取所有句柄 1.定位赶集网招聘求职按钮,并点击 2.点击后,获取当前所有的句柄:window_handles

四、切换句柄
网上大部分教程都是些的第一种方法,小编这里新增一个更简单的方法,直接从获取所有的句柄list里面取值。
方法一(不推荐):
1.循环判断是否与首页句柄相等
2.如果不等,说明是新页面的句柄
3.获取的新页面句柄后,可以切换到新打开的页面上
4.打印新页面的title,看是否切换成功
方法二:
1.直接获取all_h这个list数据里面第二个hand的值:all_h[1]
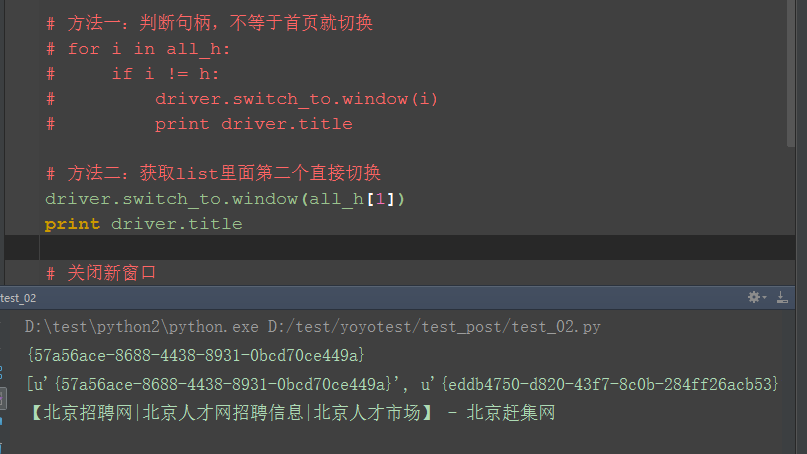
五、关闭新窗口,切回主页 1.close是关闭当前窗口,因为此时有两个窗口,用close可以关闭其中一个,quit是退出整个进程(如果当前有两个窗口,会一起关闭)。 2.切换到首页句柄:h 3.打印当前页面的title,看是否切换到首页了

六、参考代码
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://bj.ganji.com/")
h = driver.current_window_handle
print h # 打印首页句柄
driver.find_element_by_link_text("招聘求职").click()
all_h = driver.window_handles
print all_h # 打印所有的句柄
# 方法一:判断句柄,不等于首页就切换(不推荐此方法,太繁琐)
# for i in all_h:
# if i != h:
# driver.switch_to.window(i)
# print driver.title
# 方法二:获取list里面第二个直接切换
driver.switch_to.window(all_h[1])
print driver.title
# 关闭新窗口
driver.close()
# 切换到首页句柄
driver.switch_to.window(h)
# 打印当前的title
print driver.title
2.8 定位一组元素elements
前言 前面的几篇都是讲如何定位一个元素,有时候一个页面上有多个对象需要操作,如果一个个去定位的话,比较繁琐,这时候就可以定位一组对象。 webdriver 提供了定位一组元素的方法,跟前面八种定位方式其实一样,只是前面是单数,这里是复数形式:find_elements
本篇拿百度搜索作为案例,从搜索结果中随机选择一条搜索结果,然后点击查看。
一、定位搜索结果 1.在百度搜索框输入关键字“测试部落”后,用firebug查看页面元素,可以看到这些搜索结果有共同的属性。
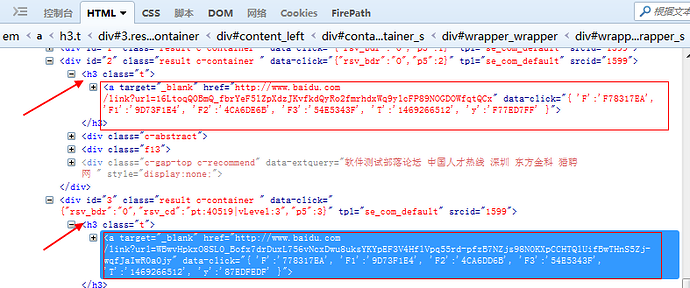
2.从搜索的结果可以看到,他们的父元素一样:<h3 class="t"> 3.标签都一样,且target属性也一样:<a target="_blank" /> 4.于是这里可以用css定位(当然用xpath也是可以的)

二、确认定位结果 1.前面的定位策略只是一种猜想,并不一定真正获取到自己想要的对象的,也行会定位到一些不想要的对象。 2.于是可以获取对象的属性,来验证下是不是定位准确了。这里可以获取href属性,打印出url地址。

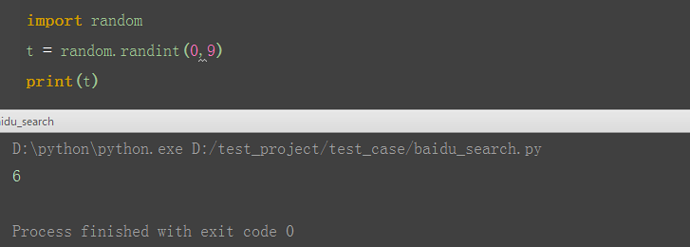
三、随机函数 1.搜索结果有10条,从这10条中随机取一个就ok了 2.先导入随机函数:import random 3.设置随机值范围为0~9:a=random.randint(0~9)
四、随机打开url 1.从返回结果中随机取一个url地址 2.通过get方法打卡url 3.其实这种方式是接口测试了,不属于UI自动化,这里只是开阔下思维,不建议用这种方法

五、通过click点击打开 1.前面那种方法,是直接访问url地址,算是接口测试的范畴了,真正模拟用户点击行为,得用click的方法
# coding:utf-8
from selenium import webdriver
import random
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
driver.find_element_by_id("kw").send_keys(u"测试部落")
driver.find_element_by_id("kw").submit()
s = driver.find_elements_by_css_selector("h3.t>a")
# 设置随机值
t = random.randint(0, 9)
# 随机取一个结果点击鼠标
s[t].click()
不知道有小伙伴有没注意一个细节,前面在搜索框输入关键字后,我并没有去点击搜索按钮,而是用的submit的方法,submit相当于回车键。 具体的操作对象方法,下篇详细介绍。本篇主要学会定位一组对象,然后随机操作其中的一个。
2.9 iframe
一、frame和iframe区别 Frame与Iframe两者可以实现的功能基本相同,不过Iframe比Frame具有更多的灵活性。 frame是整个页面的框架,iframe是内嵌的网页元素,也可以说是内嵌的框架 Iframe标记又叫浮动帧标记,可以用它将一个HTML文档嵌入在一个HTML中显示。它和Frame标记的最大区别是在网页中嵌入 的<Iframe></Iframe>所包含的内容与整个页面是一个整体,而<Frame>< /Frame>所包含的内容是一个独立的个体,是可以独立显示的。另外,应用Iframe还可以在同一个页面中多次显示同一内容,而不必重复这段内 容的代码。
二、案例操作:163登录界面 1.打开http://mail.163.com/登录页面
2.用firebug定位登录框
3.鼠标停留在左下角(定位到iframe位置)时,右上角整个登录框显示灰色,说明iframe区域是整个登录框区域
4.左下角箭头位置显示iframe属性<iframe id="x-URS-iframe" frameborder="0" name=""

三、切换iframe 1.由于登录按钮是在iframe上,所以第一步需要把定位器切换到iframe上 2.用switch_to_frame方法切换,此处有id属性,可以直接用id定位切换
四、如果iframe没有id怎么办? 1.这里iframe的切换是默认支持id和name的方法的,当然实际情况中会遇到没有id属性和name属性为空的情况,这时候就需要先定位iframe元素对象 2.定位元素还是之前的八种方法同样适用,这里我可以通过tag先定位到,也能达到同样效果
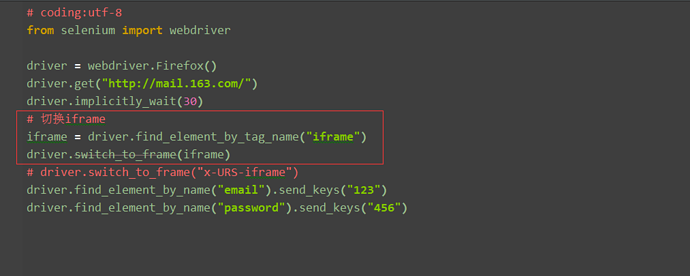
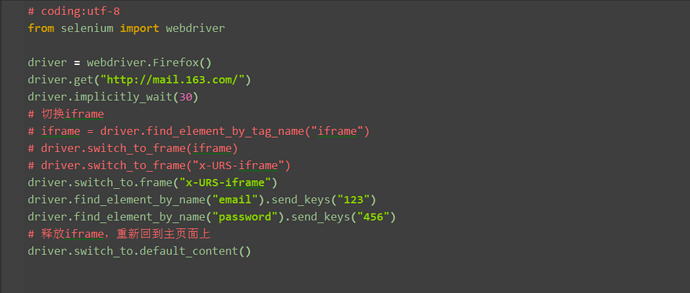
五、释放iframe 1.当iframe上的操作完后,想重新回到主页面上操作元素,这时候,就可以用switch_to_default_content()方法返回到主页面
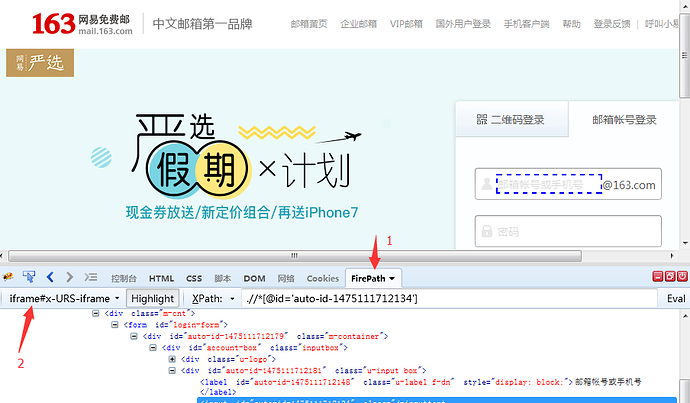
六、如何判断元素是否在iframe上? 1.定位到元素后,切换到firepath界面 2.看firebug工具左上角,如果显示Top Window说明没有iframe 3.如果显示iframe#xxx这样的,说明在iframe上,#后面就是它的id
七、如何解决switch_to_frame上的横线呢? 1.先找到官放的文档介绍
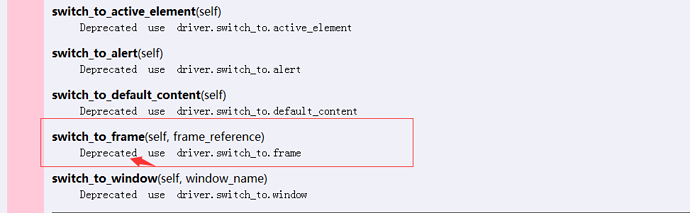
2.python的脚本上面划一横线,是说这个语法已经过时了(也可以继续用,只是有部分人有强迫症)。上面文档介绍说官方已经不推荐上面的写法了,用这个写法就好了driver.switch_to.frame()
八、参考代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://mail.163.com/")
driver.implicitly_wait(30)
# 切换iframe
# iframe = driver.find_element_by_tag_name("iframe")
# driver.switch_to_frame(iframe)
# driver.switch_to_frame("x-URS-iframe")
driver.switch_to.frame("x-URS-iframe")
driver.find_element_by_name("email").send_keys("123")
driver.find_element_by_name("password").send_keys("456")
# 释放iframe,重新回到主页面上
driver.switch_to.default_content()
2.10 select下拉框
本篇以百度设置下拉选项框为案例,详细介绍select下拉框相关的操作方法。
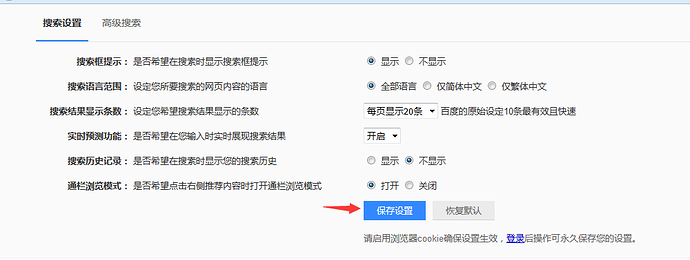
一、认识select 1.打开百度-设置-搜索设置界面,如下图所示
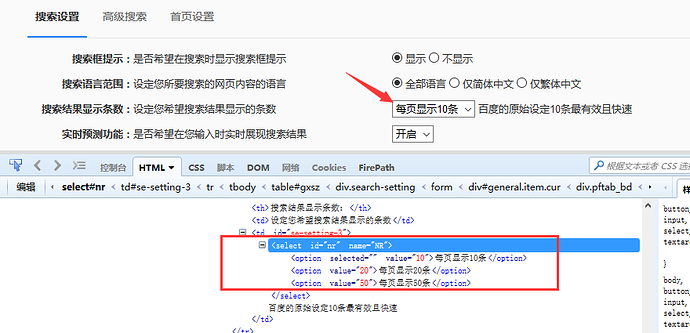
2.箭头所指位置,就是select选项框,打开页面元素定位,下方红色框框区域,可以看到select标签属性:
<select id="nr" name="NR">
3.选项有三个。
<option selected="" value="10">每页显示10条</option>
<option value="20">每页显示20条</option>
<option value="50">每页显示50条</option>
二、二次定位 1.定位select里的选项有多种方式,这里先介绍一种简单的方法:二次定位 2.基本思路,先定位select框,再定位select里的选项 3.代码如下:
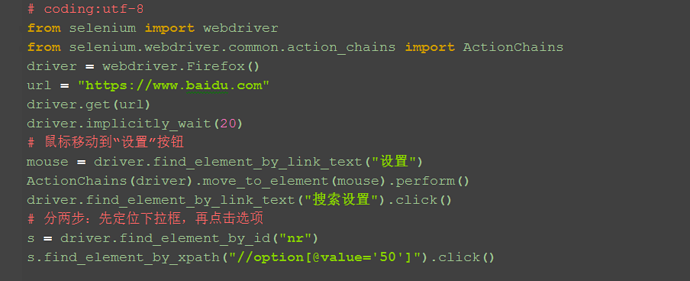
4.还有另外一种写法也是可以的,把最下面两步合并成为一步:
driver.find_element_by_id("nr").find_element_by_xpath("//option[@value='50']").click()
三、直接定位 1.有很多小伙伴说firebug只能定位到select框,不能定位到里面的选项,其实是工具掌握的不太熟练。小编接下来教大家如何定位里面的选项。 2.用firebug定位到select后,下方查看元素属性地方,点select标签前面的+号,就可以展开里面的选项内容了。

3.然后自己写xpath定位或者css,一次性直接定位到option上的内容。(不会自己手写的,回头看前面的元素定位内容)

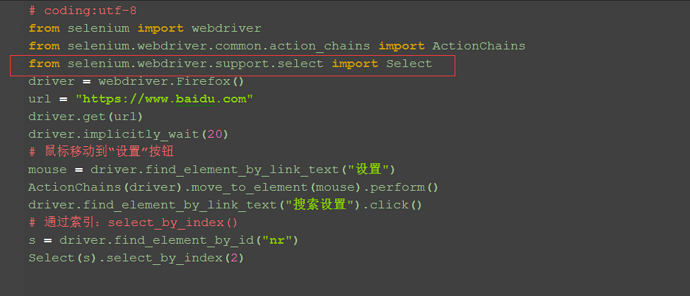
四、Select模块(index)
1.除了上面介绍的两种简单的方法定位到select选项,selenium还提供了更高级的玩法,导入Select模块。直接根据属性或索引定位。 2.先要导入select方法: from selenium.webdriver.support.select import Select 3.然后通过select选项的索引来定位选择对应选项(从0开始计数),如选择第三个选项:select_by_index(2)
五、Select模块(value)
1.Select模块里面除了index的方法,还有一个方法,通过选项的value值来定位。每个选项,都有对应的value值,如
<select id="nr" name="NR">
<option selected="" value="10">每页显示10条</option>
<option value="20">每页显示20条</option>
<option value="50">每页显示50条</option>
</select>
2.第二个选项对应的value值就是"20":select_by_value("20")

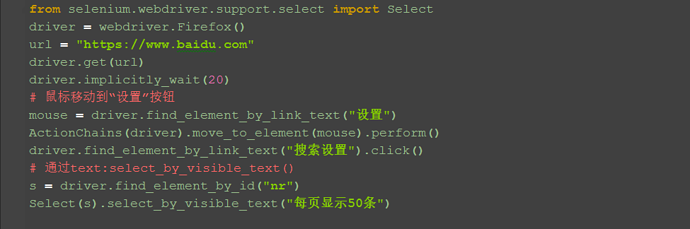
六、Select模块(text) 1.Select模块里面还有一个更加高级的功能,可以直接通过选项的文本内容来定位。 2.定位“每页显示50条”:select_by_visible_text("每页显示50条")
七、Select模块其它方法 1.select里面方法除了上面介绍的三种,还有更多的功能如下:

select_by_index() :通过索引定位 select_by_value() :通过value值定位 select_by_visible_text() :通过文本值定位 deselect_all() :取消所有选项 deselect_by_index() :取消对应index选项 deselect_by_value() :取消对应value选项 deselect_by_visible_text() :取消对应文本选项
first_selected_option() :返回第一个选项 all_selected_options() :返回所有的选项
八、整理代码如下:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
driver.implicitly_wait(20)
# 鼠标移动到“设置”按钮
mouse = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(mouse).perform()
driver.find_element_by_link_text("搜索设置").click()
# 通过text:select_by_visible_text()
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示50条")
# # 分两步:先定位下拉框,再点击选项s = driver.find_element_by_id("nr")s.find_element_by_xpath("//option[@value='50']").click()
# # 另外一种写法
driver.find_element_by_id("nr").find_element_by_xpath("//option[@value='50']").click()
# # 直接通过xpath定位
driver.find_element_by_xpath(".//*[@id='nr']/option[2]").click()
# # 通过索引:select_by_index()
s = driver.find_element_by_id("nr")
Select(s).select_by_index(2)
# # 通过value:select_by_value()
s = driver.find_element_by_id("nr")
Select(s).select_by_value("20")
2.11 alert\confirm\prompt
前言 不是所有的弹出框都叫alert,在使用alert方法前,先要识别出到底是不是alert。先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决。 alert\confirm\prompt弹出框操作主要方法有: text:获取文本值 accept() :点击"确认" dismiss() :点击"取消"或者叉掉对话框 send_keys() :输入文本值 --仅限于prompt,在alert和confirm上没有输入框
一、认识alert\confirm\prompt 1.如下图,从上到下依次为alert\confirm\prompt,先认清楚长什么样子,以后遇到了就知道如何操作了。

2.html源码如下(有兴趣的可以copy出来,复制到txt文本里,后缀改成html就可以了,然后用浏览器打开):
<html>
<head>
<title>Alert</title>
</head>
<body>
<input id = "alert" value = "alert" type = "button" onclick = "alert('您关注了yoyoketang吗?');"/>
<input id = "confirm" value = "confirm" type = "button" onclick = "confirm('确定关注微信公众号:yoyoketang?');"/>
<input
id = "prompt" value = "prompt" type = "button" onclick = "var name =
prompt('请输入微信公众号:','yoyoketang'); document.write(name) "/>
</body>
</html>
二、alert操作
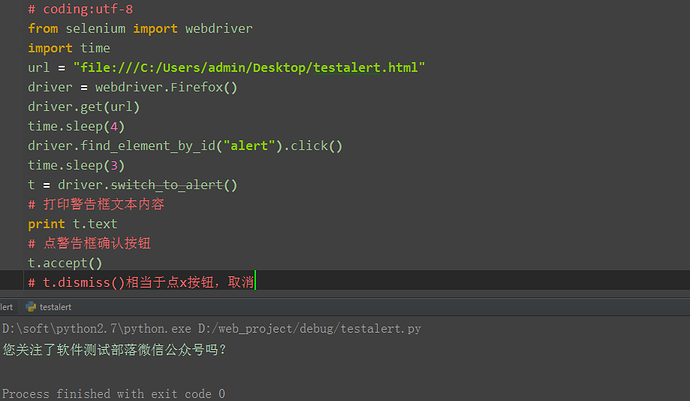
1.先用switch_to_alert()方法切换到alert弹出框上 2.可以用text方法获取弹出的文本 信息 3.accept()点击确认按钮 4.dismiss()相当于点右上角x,取消弹出框 (url的路径,直接复制浏览器打开的路径)
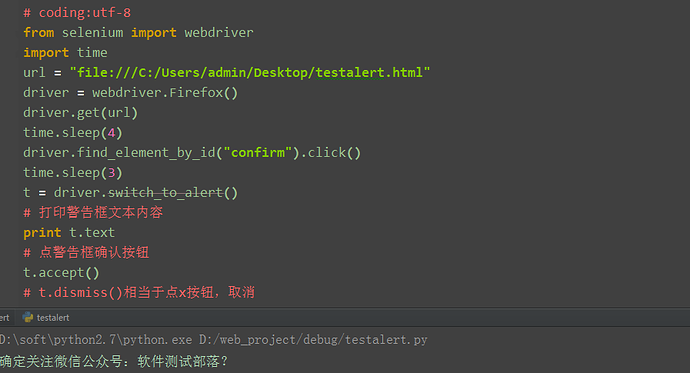
三、confirm操作 1.先用switch_to_alert()方法切换到alert弹出框上 2.可以用text方法获取弹出的文本 信息 3.accept()点击确认按钮 4.dismiss()相当于点取消按钮或点右上角x,取消弹出框 (url的路径,直接复制浏览器打开的路径)
四、prompt操作 1.先用switch_to_alert()方法切换到alert弹出框上 2.可以用text方法获取弹出的文本 信息 3.accept()点击确认按钮 4.dismiss()相当于点右上角x,取消弹出框 5.send_keys()这里多个输入框,可以用send_keys()方法输入文本内容 (url的路径,直接复制浏览器打开的路径)

五、select遇到的坑 1.在操作百度设置里面,点击“保存设置”按钮时,alert弹出框没有弹出来。(Ie浏览器是可以的) 2.分析原因:经过慢慢调试后发现,在点击"保存设置"按钮时,由于前面的select操作后,失去了焦点 3.解决办法:在select操作后,做个click()点击操作
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示20条")
time.sleep(3)
s.click()
六、最终代码
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import time
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
driver.implicitly_wait(20)
# 鼠标移动到“设置”按钮
mouse = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(mouse).perform()
driver.find_element_by_link_text("搜索设置").click()
# 通过text:select_by_visible_text()
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示20条")
time.sleep(3)
s.click()
driver.find_element_by_link_text("保存设置").click()
time.sleep(5)
# 获取alert弹框
t = driver.switch_to_alert()
print t.text
t.accept()
这一篇应该比较简单,alert相关的内容比较少,虽然有一些页面也有弹窗,但不是所有的弹窗都叫alert。
alert的弹出框界面比较简洁,调用的是Windows系统弹窗警告框,没花里胡哨的东西,还是很容易区分的。
2.12 单选框和复选框(radiobox、checkbox)
本篇主要介绍单选框和复选框的操作 一、认识单选框和复选框 1.先认清楚单选框和复选框长什么样

2.各位小伙伴看清楚哦,上面的单选框是圆的;下图复选框是方的,这个是业界的标准,要是开发小伙伴把图标弄错了,可以先抽他了。 二、radio和checkbox源码 1.上图的html源码如下,把下面这段复制下来,写到文本里,后缀改成.html就可以了。
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8"/>
<title>单选和复选</title>
</head>
<body>
<h4>单选:性别</h4>
<form>
<label value="radio">男</label>
<input name="sex" value="male"id="boy" type="radio"><br>
<label value="radio1">女</label>
<input name="sex" value="female"id="girl" type="radio">
</form>
<h4>微信公众号:从零开始学自动化测试</h4>
<form>
<!-- <labelfor="c1">checkbox1</label> -->
<input id="c1"type="checkbox">selenium<br>
<!-- <labelfor="c2">checkbox2</label> -->
<input id="c2"type="checkbox">python<br>
<!-- <labelfor="c3">checkbox3</label> -->
<input id="c3"type="checkbox">appium<br>
<!-- <form>
<input type="radio" name="sex" value="male"/> Male
<br />
<input type="radio" name="sex"value="female" /> Female
</form> -->
</body>
</html>
三、单选:radio 1.首先是定位选择框的位置
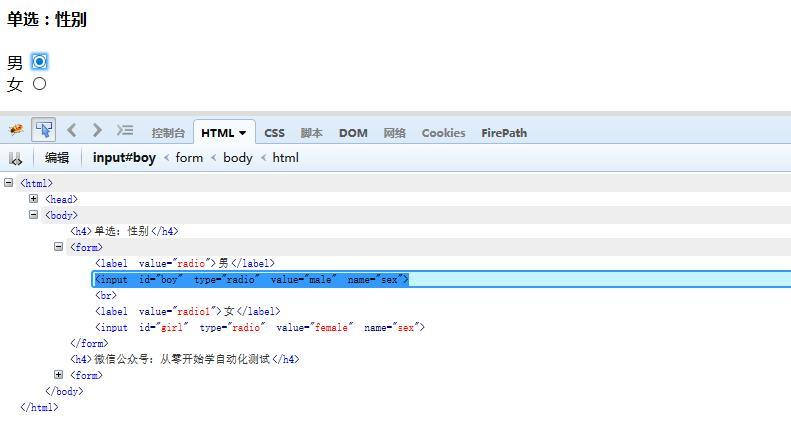
2.定位id,点击图标就可以了,代码如下(获取url地址方法:把上面源码粘贴到文本保存为.html后缀后用浏览器打开,在浏览器url地址栏复制出地址就可以了) 3.先点击boy后,等十秒再点击girl,观察页面变化
四、复选框:checkbox 1.勾选单个框,比如勾选selenium这个,可以根据它的id=c1直接定位到点击就可以了。
2.那么问题来了:如果想全部勾选上呢?
五、全部勾选: 1.全部勾选,可以用到定位一组元素,从上面源码可以看出,复选框的type=checkbox,这里可以用xpath语法:.//*[@type='checkbox']
2.这里注意,敲黑板做笔记了:find_elements是不能直接点击的,它是复数的,所以只能先获取到所有的checkbox对象,然后通过for循环去一个个点击操作
六、判断是否选中:is_selected() 1.有时候这个选项框,本身就是选中状态,如果我再点击一下,它就反选了,这可不是我期望的结果,那么可不可以当它是没选中的时候,我去点击下;当它已经是选中状态,我就不点击呢?那么问题来了:如何判断选项框是选中状态? 2.判断元素是否选中这一步才是本文的核心内容,点击选项框对于大家来说没什么难度。获取元素是否为选中状态,打印结果如下图。 3.返回结果为bool类型,没点击时候返回False,点击后返回True,接下来就很容易判断了,既可以作为操作前的判断,也可以作为测试结果的判断。

七、参考代码:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("file:///C:/Users/Gloria/Desktop/checkbox.html")
# 没点击操作前,判断选项框状态
s = driver.find_element_by_id("boy").is_selected()
print s
driver.find_element_by_id("boy").click()
# 点击后,判断元素是否为选中状态
r = driver.find_element_by_id("boy").is_selected()
print r
# 复选框单选
driver.find_element_by_id("c1").click()
# 复选框全选
checkboxs = driver.find_elements_by_xpath(".//*[@type='checkbox']")
for i in checkboxs:
i.click()
2.13 table表格定位
前言 在web页面中经常会遇到table表格,特别是后台操作页面比较常见。本篇详细讲解table表格如何定位。 一、认识table 1.首先看下table长什么样,如下图,这种网状表格的都是table
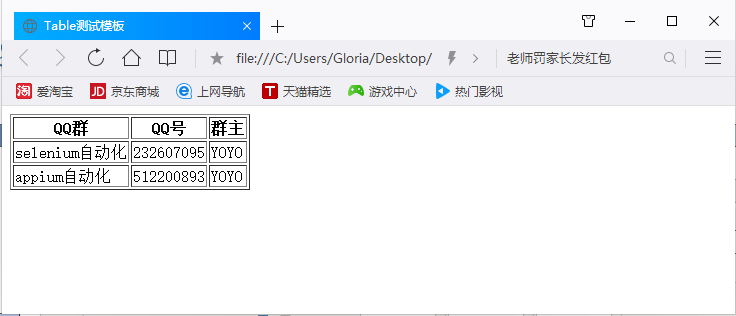
2.源码如下:(用txt文本保存,后缀改成html)
<!DOCTYPE html>
<meta charset="UTF-8"> <!-- for HTML5 -->
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<html>
<head>
<title>Table测试模板</title>
</head>
<body>
<table border="1" id="myTable">
<tr>
<th>QQ群</th>
<th>QQ号</th>
<th>群主</th>
</tr>
<tr>
<td>selenium自动化</td>
<td>232607095</td>
<td>YOYO</td>
</tr>
<tr>
<td>appium自动化</td>
<td>512200893</td>
<td>YOYO</td>
</tr>
</table>
</body>
</html>
二、table特征 1.table页面查看源码一般有这几个明显的标签:table、tr、th、td 2.<table>标示一个表格 3.<tr>标示这个表格中间的一个行 4.</th> 定义表头单元格 5.</td> 定义单元格标签,一组<td>标签将将建立一个单元格,<td>标签必须放在<tr>标签内
三、xpath定位table 1.举个例子:我想定位表格里面的“selenium自动化”元素,这里可以用xpath定位:.//*[@id='myTable']/tbody/tr[2]/td[1]
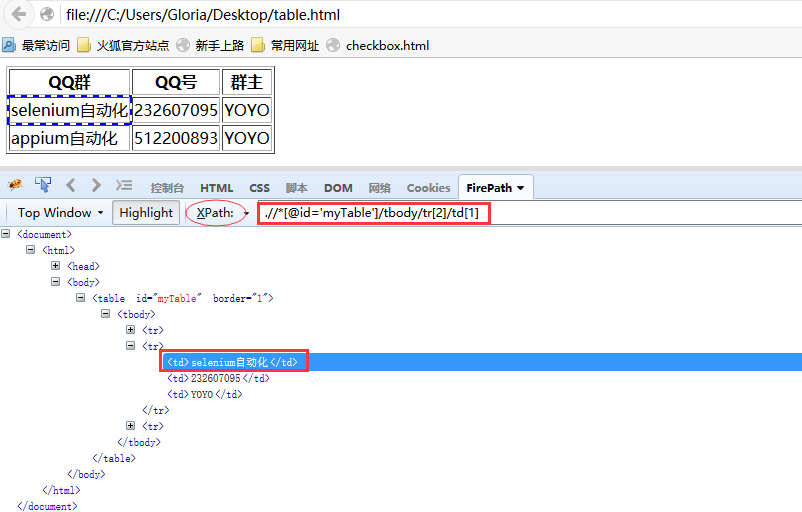
2.这里定位的格式是固定的,只需改tr和td后面的数字就可以了.如第二行第一列tr[2]td[1]. 对xpath语法不熟悉的可以看这篇Selenium2+python自动化7-xpath定位 四、打印表格内容 1.定位到表格内文本值,打印出来,脚本如下:

五、参考代码:
# coding:utf-8
from selenium import webdriver
import time
url = 'file:///C:/Users/Gloria/Desktop/table.html'
driver = webdriver.Firefox()
driver.get(url)
time.sleep(3)
t = driver.find_element_by_xpath(".//*[@id='myTable']/tbody/tr[2]/td[1]")
print t.text
补充说明:有些小伙伴可能会遇到table在ifame上的情况,这时候就需要先切换iframe了。
2.14 加载Firefox配置(略,已在2.1.8讲过,请查阅2.1.8节课)
2.14-1 加载Chrome配置
一、加载Chrome配置 chrome加载配置方法,只需改下面一个地方,username改成你电脑的名字(别用中文!!!)
'--user-data-dir=C:\Users\username\AppData\Local\Google\Chrome\User Data'
# coding:utf-8
from selenium import webdriver
# 加载Chrome配置
option = webdriver.ChromeOptions()
option.add_argument('--user-data-dir=C:\Users\Gloria\AppData\Local\Google\Chrome\User Data')
driver = webdriver.Chrome(chrome_options=option)
driver.implicitly_wait(30)
driver.get("http://www.cnblogs.com/yoyoketang/")
二、Wap测试 1.做Wap测试的可以试下,伪装成手机访问淘宝,会出现触屏版
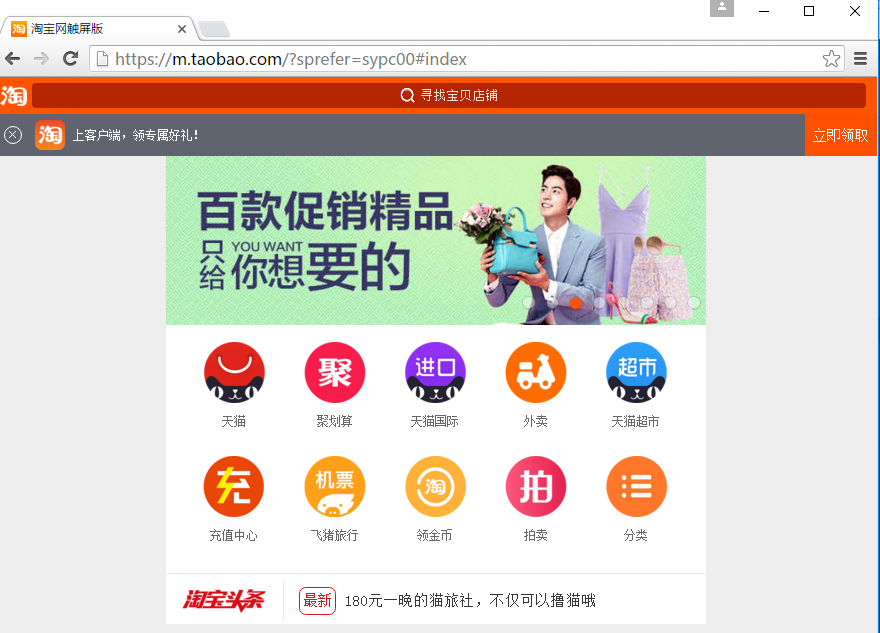
# coding:utf-8
from selenium import webdriver
option = webdriver.ChromeOptions()
# 伪装iphone登录
# option.add_argument('--user-agent=iphone')
# 伪装android
option.add_argument('--user-agent=android')
driver = webdriver.Chrome(chrome_options=option)
driver.get('http://www.taobao.com/')
2.15 富文本(richtext)
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴不知从何下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一、加载配置 1.打开博客园写随笔,首先需要登录,这里为了避免透露个人账户信息,我直接加载配置文件,免登录了。 
二、打开编辑界面 1.博客首页地址:bolgurl = "http://www.cnblogs.com/" 2.我的博客园地址:yoyobolg = bolgurl + "yoyoketang" 3.点击“新随笔”按钮,id=blog_nav_newpost

三、iframe切换 1.打开编辑界面后先不要急着输入内容,先sleep几秒钟 2.输入标题,这里直接通过id就可以定位到,没什么难点 3.接下来就是重点要讲的富文本的编辑,这里编辑框有个iframe,所以需要先切换
(关于iframe不懂的可以看前面这篇:<iframe>)
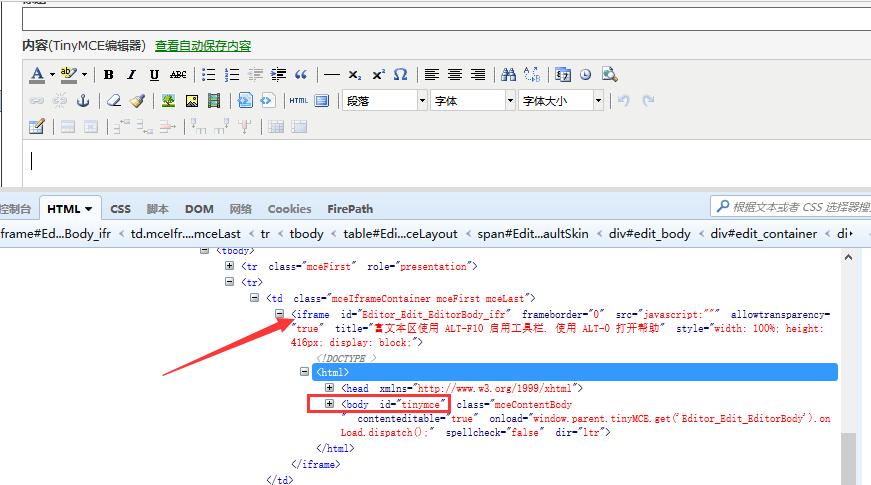
四、输入正文 1.这里定位编辑正文是定位上图的红色框框位置body部分,也就是id=tinymce
2.定位到之后,直接send_keys()方法就可以输入内容了
3.有些小伙伴可能输入不成功,可以在输入之前先按个table键,send_keys(Keys.TAB)

五、参考代码:
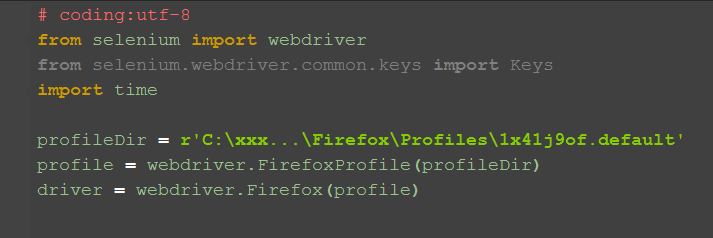
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
profileDir = r'C:\Users\Gloria\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
profile = webdriver.FirefoxProfile(profileDir)
driver = webdriver.Firefox(profile)
bolgurl = "http://www.cnblogs.com/"
yoyobolg = bolgurl + "yoyoketang"
driver.get(yoyobolg)
driver.find_element_by_id("blog_nav_newpost").click()
time.sleep(5)
edittile = u"Selenium2+python自动化23-富文本"
editbody = u"这里是发帖的正文"
driver.find_element_by_id("Editor_Edit_txbTitle").send_keys(edittile)
driver.switch_to.frame("Editor_Edit_EditorBody_ifr")
driver.find_element_by_id("tinymce").send_keys(Keys.TAB)
driver.find_element_by_id("tinymce").send_keys(editbody)
2.16-1 非input文件上传(SendKeys)
前言 不少小伙伴问非input标签如何上传文档,这个本身就是一坑,无奈很多小伙伴非要跳坑里去,那就介绍一个非主流的上传文件方法吧,用第三方库SendKeys. 一、SendKeys安装 1.pip安装SendKeys >pip install SendKeys

2.在安装的时候如果你出现上面保存,先别急着截图贴群求大神,上面已经告诉解决办法了:Get it from http://aka.ms/vcpython27 3.按上面给的地址下载文件,一路傻瓜式安装就行 4.出现如下界面,说明安装成功了
二、参考代码 1.以下代码在Chrom浏览器上是运行通过的,要先登录博客园记住密码,然后加载配置免登录 2.chrome加载配置方法,只需改下面一个地方,username改成你电脑的名字(别用中文!!!)
'--user-data-dir=C:\Users\username\AppData\Local\Google\Chrome\User Data'
3.后面两次回车,是因为搜狗输入法,第一个回车是确认输入,第二个是确定选中的文件
4.这里点文件上传按钮也是一个坑,用工具定位的这个元素,点击有问题,所以我改用它父元素定位了
# coding:utf-8
from selenium import webdriver
import SendKeys
import time
# 加载Firefox配置
# profileDir = r'C:\Users\xxxAppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
# profile = webdriver.FirefoxProfile(profileDir)
# driver = webdriver.Firefox(profile)
# 加载Chrome配置
option = webdriver.ChromeOptions()
option.add_argument('--user-data-dir=C:\Users\xxxAppData\Local\Google\Chrome\User Data')
driver = webdriver.Chrome(chrome_options=option)
driver.implicitly_wait(30)
driver.get("http://www.cnblogs.com/yoyoketang/")
driver.find_element_by_link_text("新随笔").click()
time.sleep(3)
# 点开编辑器图片
driver.find_element_by_css_selector("img.mceIcon").click()
time.sleep(3)
# 定位所有iframe,取第二个
iframe = driver.find_elements_by_tag_name('iframe')[1]
# 切换到iframe上
driver.switch_to_frame(iframe)
# 文件路径
time.sleep(2)
driver.find_element_by_class_name("qq-upload-button").click()
# driver.find_element_by_name("file").click() # 这里点文件上传按钮也是一个坑,我用它父元素定位了,参考上面一行
time.sleep(5)
# SendKeys方法输入内容
SendKeys.SendKeys("D:\\test\\jie1\\blog\\12.png") # 发送文件地址
time.sleep(1)
SendKeys.SendKeys("{ENTER}") # 发送回车键
time.sleep(1)
SendKeys.SendKeys("{ENTER}") # 因为我的电脑是搜索输入法,所以多看一次回车
# driver.quit()
(备注:这里Firefox上运行有个坑,第二次回车失效了,这个暂时没想到好的解决办法) 只能说处处都是坑,且用且珍惜!
2.16 文件上传(send_keys)
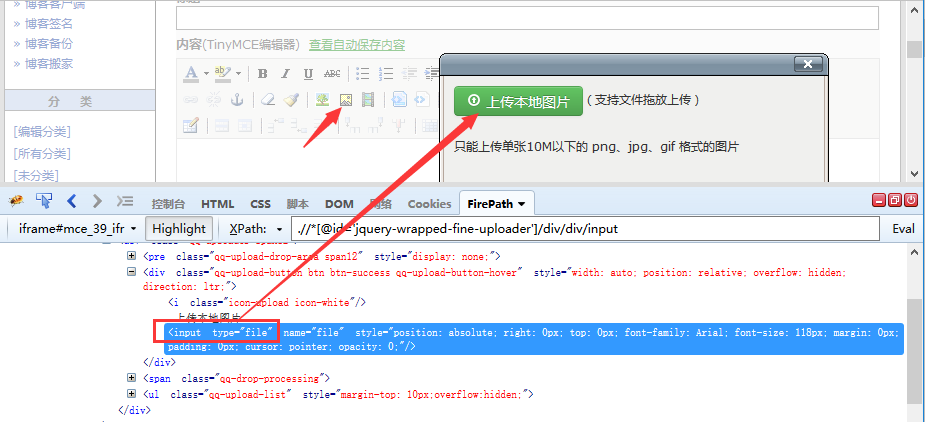
前言 文件上传是web页面上很常见的一个功能,用脚本去实现文件上传却不是那么简单。 一般分两个场景:一种是input标签,这种可以用selenium提供的send_keys()方法轻松解决; 另外一种非input标签实现起来比较困难,可以借助autoit工具或者SendKeys第三方库。 本篇以博客园的上传图片为案例,通过send_keys()方法解决文件上传问题 一、识别上传按钮 1.点开博客园编辑器里的图片上传按钮,弹出”上传本地图片”框。 2.用firebug查看按钮属性,这种上传图片按钮有个很明显的标识,它是一个input标签,并且type属性的值为file。只要找到这两个标识,我们就可以直接用send_keys()方法上传文件了。
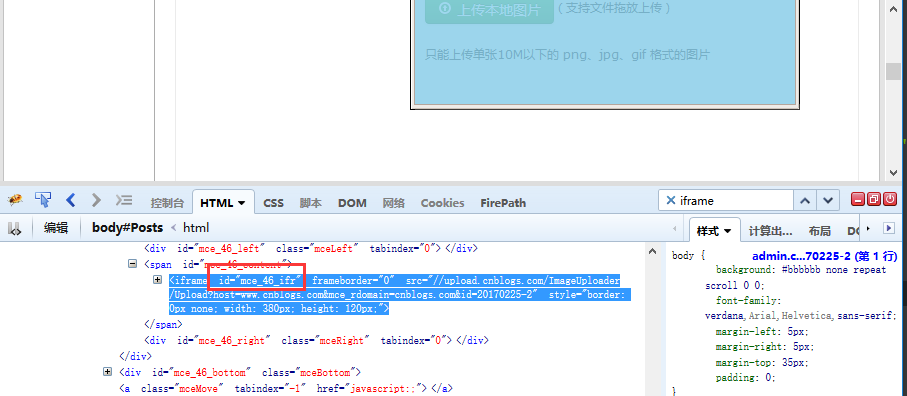
二、定位iframe 1.这里定位图片上传按钮情况有点复杂,首先它是在iframe上。 2.这个iframe的id是动态的,且没有name属性,其它属性也不是很明显。 3.通过搜索发现,这个页面上有两个iframe,需要定位的这个iframe是处于第二个位置。
4.可以通过标签定位所有的iframe标签,然后取对应的第几个就可以了。
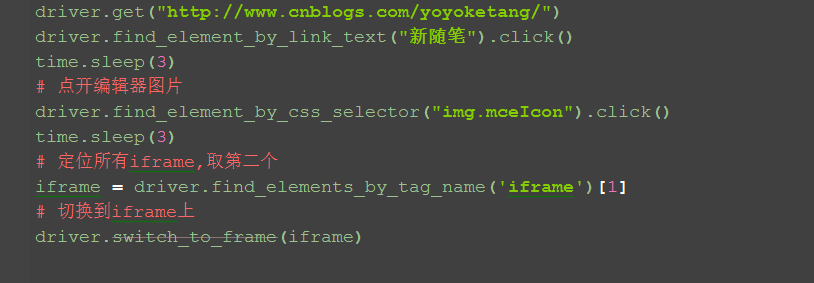
三、文件上传
1.先定位到文件上传按钮,直接调用send_keys()方法就可以实现啦
# coding:utf-8
from selenium import webdriver
import time
profileDir = r'C:\Users\Gloria\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
profile = webdriver.FirefoxProfile(profileDir)
driver = webdriver.Firefox(profile)
driver.implicitly_wait(30)
driver.get("http://www.cnblogs.com/yoyoketang/")
driver.find_element_by_link_text("新随笔").click()
time.sleep(3)
# 点开编辑器图片
driver.find_element_by_css_selector("img.mceIcon").click()
time.sleep(3)
# 定位所有iframe,取第二个
iframe = driver.find_elements_by_tag_name('iframe')[1]
# 切换到iframe上
driver.switch_to_frame(iframe)
# 文件路径
driver.find_element_by_name('file').send_keys(r"D:\test\xuexi\test\14.png")
非input标签的文件上传,就不适用于此方法了,需要借助autoit工具或者SendKeys第三方库。
2.17 获取元素属性
前言 通常在做断言之前,都要先获取界面上元素的属性,然后与期望结果对比。本篇介绍几种常见的获取元素属性方法。 一、获取页面title 1.有很多小伙伴都不知道title长在哪里,看下图左上角。
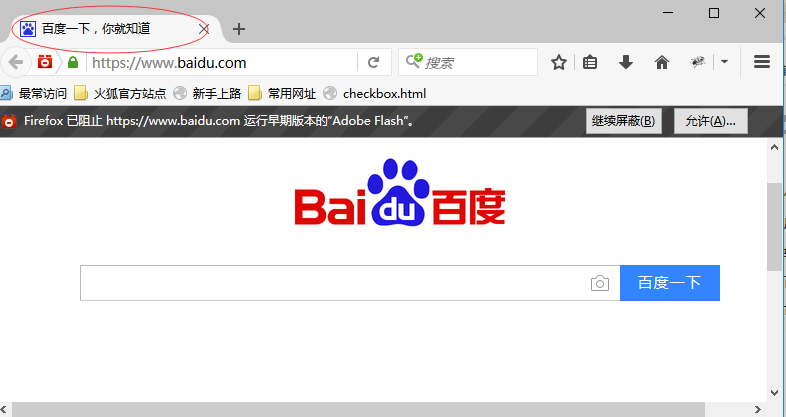
2.获取title方法很简单,直接driver.title就能获取到。

二、获取元素的文本 1.如下图这种显示在页面上的文本信息,可以直接获取到 2.查看元素属性:<a id="setf" target="_blank" onmousedown="return ns_c({'fm':'behs','tab':'favorites','pos':0}) " href="//www.baidu.com/cache/sethelp/help.html">把百度设为主页</a>

3.通过driver.text获取到文本
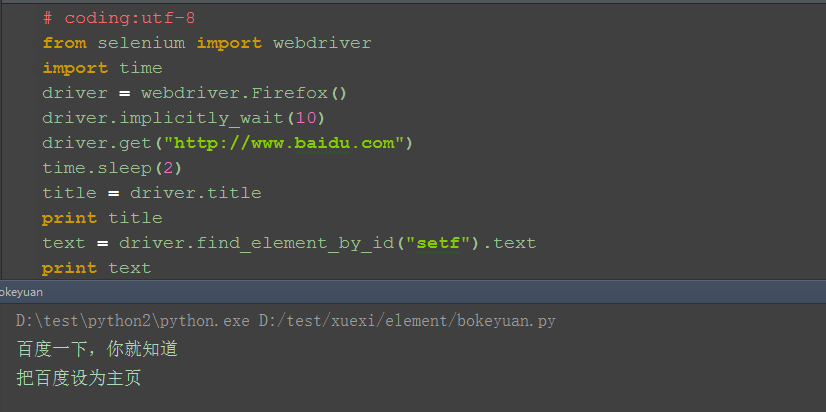
三、获取元素的标签 1.获取百度输入框的标签属性
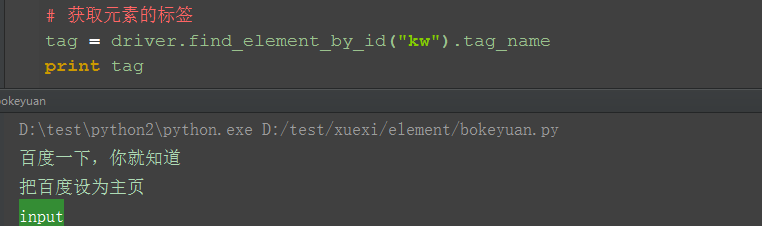
四、获取元素的其它属性 1.获取其它属性方法:get_attribute("属性"),这里的参数可以是class、name等任意属性 2.如获取百度输入框的class属性

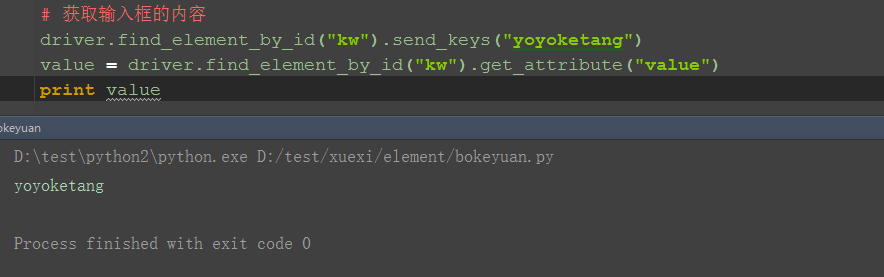
五、获取输入框内的文本值 1、如果在百度输入框输入了内容,这里输入框的内容也是可以获取到的
六、获取浏览器名称 1.获取浏览器名称很简单,用driver.name就能获取到
# 获取浏览器名称 driver.name 七、参考代码
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
time.sleep(2)
title = driver.title
print title
text = driver.find_element_by_id("setf").text
print text
# 获取元素的标签
tag = driver.find_element_by_id("kw").tag_name
print tag
# 获取元素的其它属性
name = driver.find_element_by_id("kw").get_attribute("class")
print name
# 获取输入框的内容
driver.find_element_by_id("kw").send_keys("yoyoketang")
value = driver.find_element_by_id("kw").get_attribute("value")
print value
# 获取浏览器名称
print driver.name
2.18 爬页面源码(page_source)
前言 有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。 一、page_source 1.selenium的page_source方法可以直接返回页面源码 2.重新赋值后打印出来
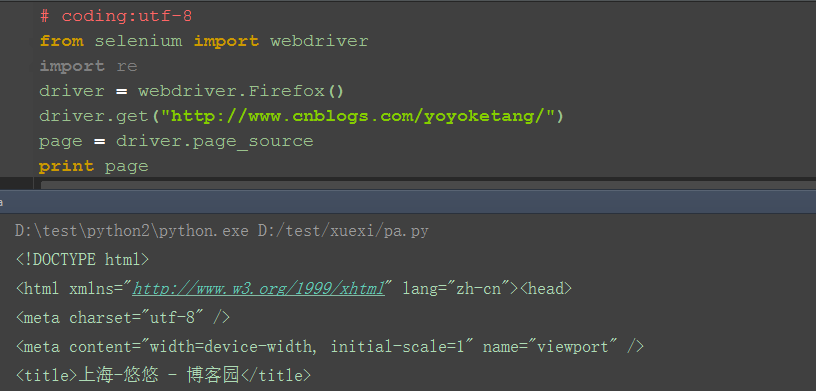
二、re非贪婪模式 1.这里需导入re模块(正则表达式模块) 2.用re的正则匹配:非贪婪模式 3.findall方法返回的是一个list集合 4.匹配出来之后发现有一些不是url链接,可以筛选下
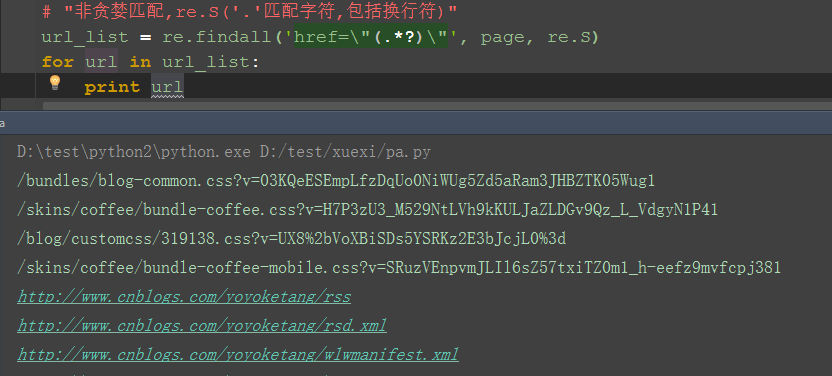
三、筛选url地址出来 1.加个if语句判断,‘http’在url里面说明是正常的url地址了 2.把所有的url地址放到一个集合,就是我们想要的结果啦
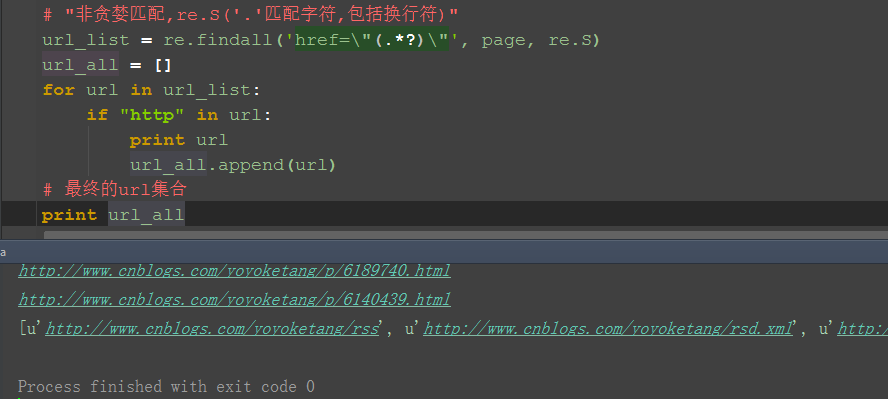
四、参考代码
# coding:utf-8
from selenium import webdriver
import re
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang/")
page = driver.page_source
# print page
# "非贪婪匹配,re.S('.'匹配字符,包括换行符)"
url_list = re.findall('href=\"(.*?)\"', page, re.S)
url_all = []
for url in url_list:
if "http" in url:
print url
url_all.append(url)
# 最终的url集合
print url_all
2.19 cookie相关操作
前言 虽然cookie相关操作在平常ui自动化中用得少,偶尔也会用到,比如登录有图形验证码,可以通过绕过验证码方式,添加cookie方法登录。 登录后换账号登录时候,也可作为后置条件去删除cookie然后下个账号登录 一、获取cookies:get_cookies() 1.获取cookies方法直接用:get_cookies() 2.先启动浏览器,获取cookies,打印出来发现是空:[] 3.打开博客首页后,重新获取cookies,打印出来,就有值了

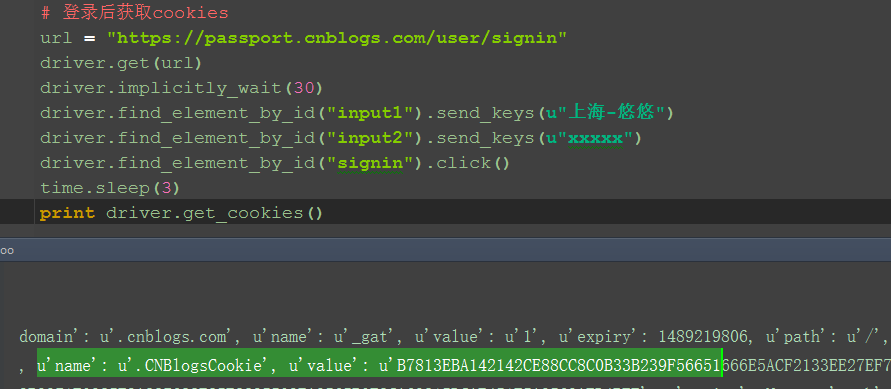
二、登录后的cookies 1.先登录博客园(这里登录用自己的账号和密码吧) 2.重新获取cookies,发现跟之前获取的不一样了 3.主要是找到这一个cookie,发现它的name和value发生了变化,这就是未登录和已登录的区别了(对比上下两张图) {u'name': u'.CNBlogsCookie', u'value': u'B7813EBA142142CE88CC8C0B33B239F566xxxx'}
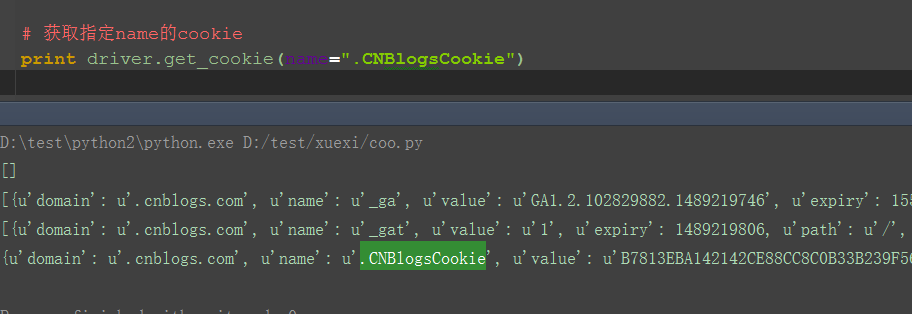
三、获取指定name的cookie:driver.get_cookie(name) 1.获取cookies发现里面有多个cookie,有时候我们只需要其中的一个,把重要的提出来,比如登录的cookie 2.这里用get_cookie(name),指定对应的cookie的name值就行了,比如博客园的:.CNBlogsCookie
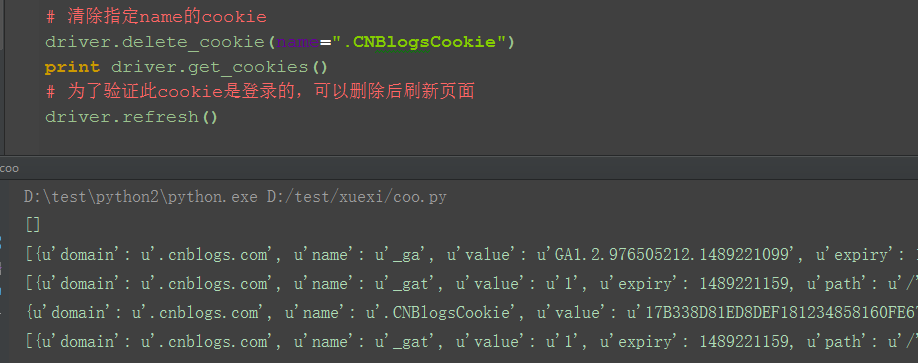
四、清除指定cookie:delete_cookie() 1.为了进一步验证上一步获取到的就是登录的cookie,可以删除它看看页面什么变化 2.删除这个cookie后刷新页面,发现刚才的登录已经失效了,变成未登录状态了
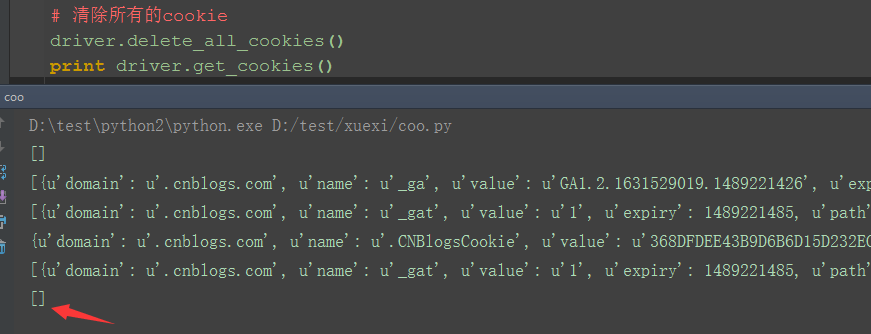
五、清除所有cookies:delete_all_cookies() 1.清除所有cookies后登录状态也失效了,cookies为空[]
六、cookie操作的几个方法 1.get_cookies():获取所有cookies 2.driver.get_cookie(name):获取指定name的cookie: 3.清除指定cookie:delete_cookie() 4.delete_all_cookies():清除所有cookies 5.add_cookie(cookie_dict):添加cookie的值 (第五个方法可以用于绕过验证码登录,下篇详细介绍)
七、参考代码
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
# 启动浏览器后获取cookies
print driver.get_cookies()
driver.get("http://www.cnblogs.com/yoyoketang/")
# 打开主页后获取cookies
print driver.get_cookies()
# 登录后获取cookies
url = "https://passport.cnblogs.com/user/signin"
driver.get(url)
driver.implicitly_wait(30)
driver.find_element_by_id("input1").send_keys(u"上海-悠悠")
driver.find_element_by_id("input2").send_keys(u"xxx")
driver.find_element_by_id("signin").click()
time.sleep(3)
print driver.get_cookies()
# 获取指定name的cookie
print driver.get_cookie(name=".CNBlogsCookie")
# 清除指定name的cookie
driver.delete_cookie(name=".CNBlogsCookie")
print driver.get_cookies()
# 为了验证此cookie是登录的,可以删除后刷新页面
driver.refresh()
# 清除所有的cookie
driver.delete_all_cookies()
print driver.get_cookies()
2.20 绕过验证码(add_cookie)
前言 验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的。如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了。 对于验证码,要么是让开发在测试环境弄个万能的验证码,如:1234,要么就是尽量绕过去,如本篇介绍的添加cookie的方法。 一、fiddler抓包 1.前一篇讲到,登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。 2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了 3.先打开博客园登录界面,手动输入账号和密码(不要点登录按钮)
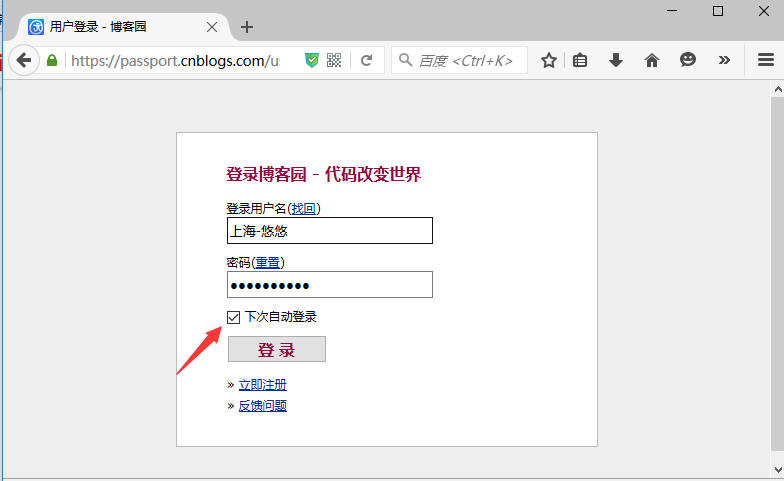
4.打开fiddler抓包工具,此时再点博客园登录按钮
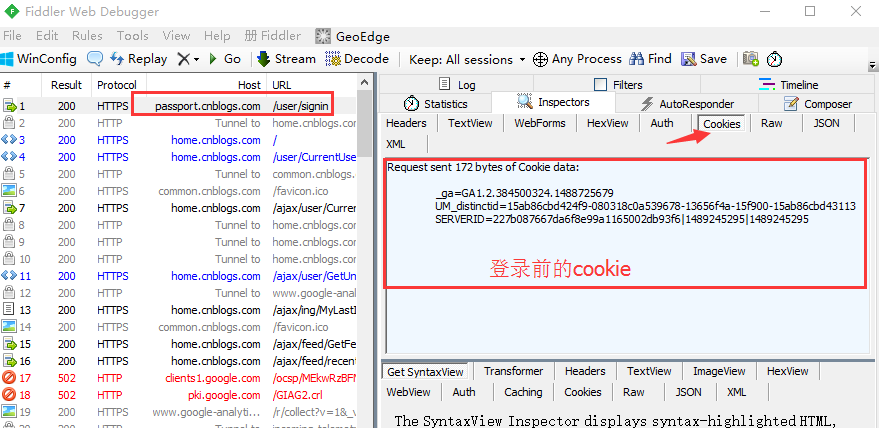
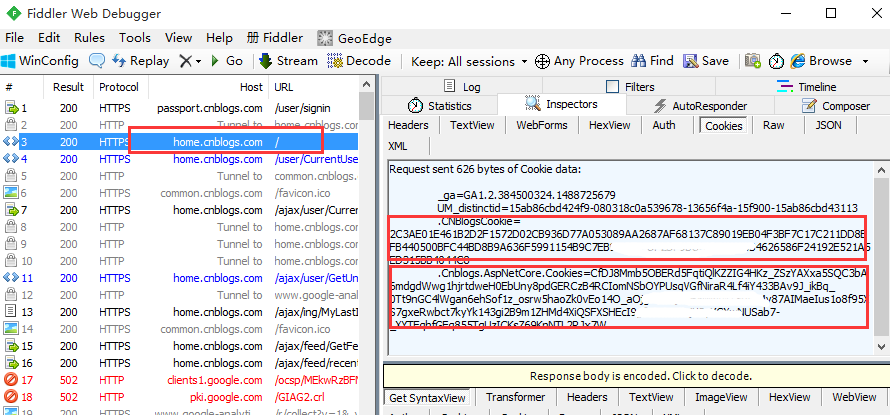
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
二、添加cookie方法:driver.add_cookie() 1.add_cookie(cookie_dict)方法里面参数是cookie_dict,说明里面参数是字典类型。 2.源码官方文档介绍:
add_cookie(self, cookie_dict):
Adds a cookie to your current session.
:Args:
- cookie_dict: A dictionary object, with required keys - "name" and "value";
optional keys - "path", "domain", "secure", "expiry"
Usage:
driver.add_cookie({'name' : 'foo', 'value' : 'bar'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/', 'secure':True})
3.从官方的文档里面可以看出,添加cookie时候传入字典类型就可以了,等号左边的是name,等号右边的是value。 4.把前面抓到的两组数据(参数不仅仅只有name和value),写成字典类型: {'name':'.CNBlogsCookie','value':'2C3AE01E461B2D2F1572D02CB936D77A053089AA2xxxx...'} {'name':'.Cnblogs.AspNetCore.Cookies','value':'CfDJ8Mmb5OBERd5FqtiQlKZZIG4HKz_Zxxx...'}
三、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数。 2.cookie参数组成,以下参数是我通过get_cookie(name)获取到的。
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
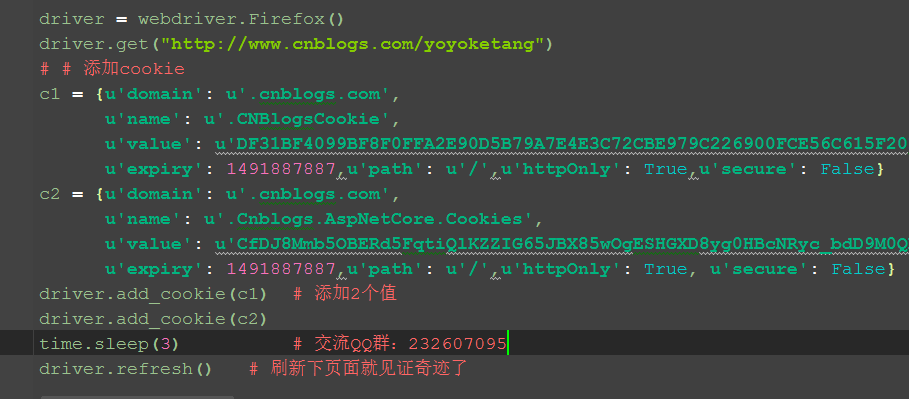
四、添加cookie 1.这里需要添加两个cookie,一个是.CNBlogsCookie,另外一个是.Cnblogs.AspNetCore.Cookies。 2.我这里打开的网页是博客的主页:http://www.cnblogs.com/yoyoketang,没进入登录页。 3.添加cookie后刷新页面,接下来就是见证奇迹的时刻了。
五、参考代码:
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang")
# # 添加cookie
c1 = {u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
c2 = {u'domain': u'.cnblogs.com',
u'name': u'.Cnblogs.AspNetCore.Cookies',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
driver.add_cookie(c1) # 添加2个值
driver.add_cookie(c2)
time.sleep(3) # 交流QQ群:232607095
# 刷新下页面就见证奇迹了
driver.refresh()
有几点需要注意:
1.登录时候要勾选下次自动登录按钮。
2.add_cookie()只添加name和value,对于博客园的登录是不成功。
3.本方法并不适合所有的网站,一般像博客园这种记住登录状态的才会适合。
2.21 JS处理滚动条
前言 selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了。 常见场景: 当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的。这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。滚动条是无法直接用定位工具来定位的。selenium里面也没有直接的方法去控制滚动条,这时候只能借助J了,还好selenium提供了一个操作js的方法:execute_script(),可以直接执行js的脚本。
一、JavaScript简介
1.JavaScript是世界上最流行的脚本语言,因为你在电脑、手机、平板上浏览的所有的网页,以及无数基于HTML5的手机App,交互逻辑都是由JavaScript驱动的。简单地说,JavaScript是一种运行在浏览器中的解释型的编程语言。那么问题来了,为什么我们要学JavaScript?
2.有些特殊的操作selenium2+python无法直接完成的,JS刚好是这方面的强项,所以算是一个很好的补充。对js不太熟悉的,可以网上找下教程,简单了解些即可。 http://www.w3school.com.cn/js/index.asp4
二、控制滚动条高度 1.滚动条回到顶部:
js="var q=document.getElementById('id').scrollTop=0" driver.execute_script(js)
2.滚动条拉到底部
js="var q=document.documentElement.scrollTop=10000" driver.execute_script(js)
3.这里可以修改scrollTop 的值,来定位右侧滚动条的位置,0是最上面,10000是最底部。
三、横向滚动条 1.有时候浏览器页面需要左右滚动(一般屏幕最大化后,左右滚动的情况已经很少见了)。
2.通过左边控制横向和纵向滚动条
scrollTo(x, y)js = "window.scrollTo(100,400);" driver.execute_script(js)
3.第一个参数x是横向距离,第二个参数y是纵向距离

四、Chrome浏览器 1.以上方法在Firefox上是可以的,但是用Chrome浏览器,发现不管用。 谷歌浏览器就是这么任性,不听话,于是用以下方法解决谷歌浏览器滚动条的问题。 2.Chrome浏览器解决办法:
js = "var q=document.body.scrollTop=0" driver.execute_script(js) 五、元素聚焦 1.虽然用上面的方法可以解决拖动滚动条的位置问题,但是有时候无法确定我需要操作的元素 在什么位置,有可能每次打开的页面不一样,元素所在的位置也不一样,怎么办呢? 2.这个时候我们可以先让页面直接跳到元素出现的位置,然后就可以操作了。同样需要借助JS去实现。 3.元素聚焦: target = driver.find_element_by_xxxx() driver.execute_script("arguments[0].scrollIntoView();", target)
六、获取浏览器名称:driver.name 1.为了解决不同浏览器操作方法不一样的问题,可以写个函数去做兼容。 2.先用driver.name获取浏览器名称,然后用if语句做个判断

七、兼容性 1.兼容谷歌和firefox/IE
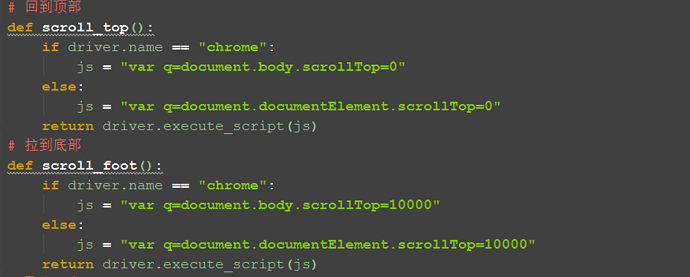
八、scrollTo函数 楼下有个小伙伴说这个scrollTo函数不存在兼容性问题,小编借花献佛了。 --scrollHeight 获取对象的滚动高度。 --scrollLeft 设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离。 --scrollTop 设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离。
--scrollWidth 获取对象的滚动宽度。
scrollTo函数不存在兼容性问题,直接用这个函数就可以了
#滚动到底部
js = "window.scrollTo(0,document.body.scrollHeight)"
driver.execute_script(js)
#滚动到顶部
js = "window.scrollTo(0,0)"
driver.execute_script(js)
九、参考代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")
print driver.name
## 回到顶部
#def scroll_top():
# if driver.name == "chrome":
# js = "var q=document.body.scrollTop=0"
# else:
# js = "var q=document.documentElement.scrollTop=0"
# return driver.execute_script(js)
# 拉到底部
#def scroll_foot():
# if driver.name == "chrome":
# js = "var q=document.body.scrollTop=10000"
# else:
# js = "var q=document.documentElement.scrollTop=10000"
# return driver.execute_script(js)
#滚动到底部
js = "window.scrollTo(0,document.body.scrollHeight)"
driver.execute_script(js)
#滚动到顶部
js = "window.scrollTo(0,0)"
driver.execute_script(js)
# 聚焦元素
target = driver.find_element_by_xxxx()
driver.execute_script("arguments[0].scrollIntoView();", target)
JS功能还是很强大的,它还可以处理富文本、内嵌滚动条的问题。
2.22 JS处理富文本
前言 <富文本>这篇解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的问题 一、加载配置 1.打开博客园写随笔,首先需要登录,这里为了避免透露个人账户信息,我直接加载配置文件,免登录了。 不懂如何加载配置文件的,看加载firefox配置
二、打开编辑界面 1.博客首页地址:bolgurl = "http://www.cnblogs.com/" 2.我的博客园地址:yoyobolg = bolgurl + "yoyoketang" 3.点击“新随笔”按钮,id=blog_nav_newpost

三、定位iframe 1.打开编辑界面后先不要急着输入内容,先sleep几秒钟 2.输入标题,这里直接通过id就可以定位到,没什么难点 3.接下来就是重点要讲的富文本的编辑,这里编辑框有个iframe,所以需要先切换
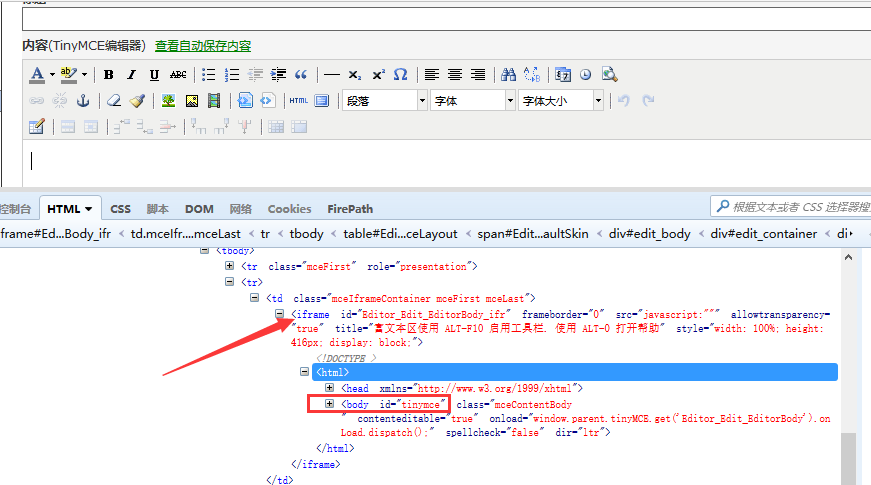
四、js输入中文 1.这里定位编辑正文是定位上图的红色框框位置body部分,也就是id=tinymce
2.定位到之后,用js的方法直接输入,无需切换iframe
3.直接点保存按钮,无需再切回来
五、参考代码:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# profileDir路径对应直接电脑的配置路径
profileDir = r'C:\xxx\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
profile = webdriver.FirefoxProfile(profileDir)
driver = webdriver.Firefox(profile)
bolgurl = "http://www.cnblogs.com/"
yoyobolg = bolgurl + "yoyoketang"
driver.get(yoyobolg)
driver.find_element_by_id("blog_nav_newpost").click()
time.sleep(5)
edittile = u"Selenium2+python自动化23-富文本"
editbody = u"这里是发帖的正文"
driver.find_element_by_id("Editor_Edit_txbTitle").send_keys(edittile)
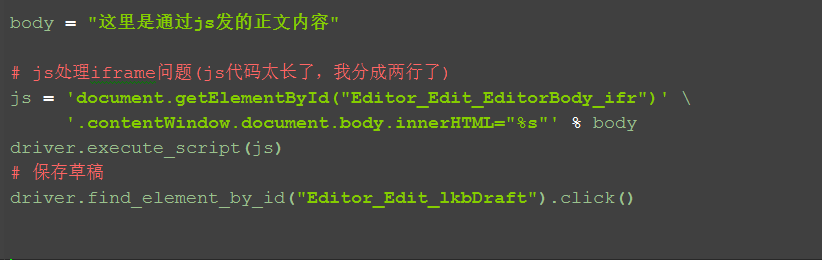
body = "这里是通过js发的正文内容"
# js处理iframe问题(js代码太长了,我分成两行了)
js = 'document.getElementById("Editor_Edit_EditorBody_ifr")' \
'.contentWindow.document.body.innerHTML="%s"' % body
driver.execute_script(js)
# 保存草稿
driver.find_element_by_id("Editor_Edit_lkbDraft").click()
2.23 js处理日历控件(修改readonly属性)
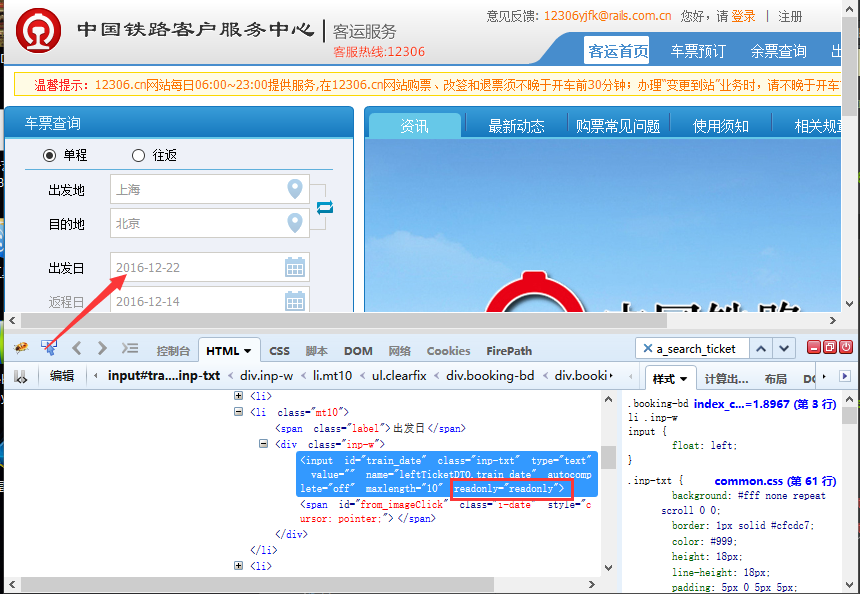
前言 日历控件是web网站上经常会遇到的一个场景,有些输入框是可以直接输入日期的,有些不能,以我们经常抢票的12306网站为例,详细讲解如何解决日历控件为readonly属性的问题。 基本思路:先用js去掉readonly属性,然后直接输入日期文本内容 一、日历控件 1.打开12306的车票查询界面,在出发日期输入框无法直接输入时间 2.常规思路是点开日历控件弹出框,从日历控件上点日期,这样操作比较烦躁,并且我们测试的重点不在日历控件上,只是想输入个时间,做下一步的操作 3.用firebug查看输入框的属性:readonly="readonly",如下:
<input id="train_date" class="inp-txt" type="text" value="" name="leftTicketDTO.train_date" autocomplete="off" maxlength="10" readonly="readonly">
二、去掉readonly属性
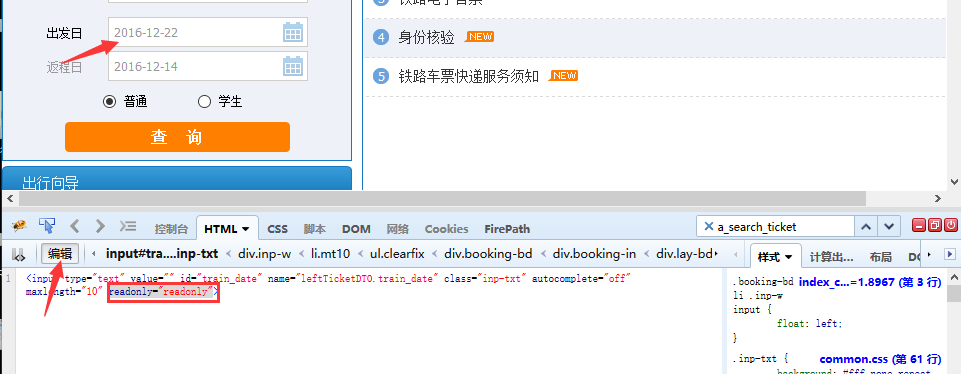
1.很明显这种元素的属性是readonly,输入框是无法直接输入的,这时候需要先去掉元素的readonly属性,然后就可以输入啦。
2.点左下角firebug的“编辑按钮”,找到对应元素,直接删除readonly="readonly",然后回车。
3.在页面出发日位置输入:yoyoketang 试试,嘿嘿,有没有发现可以输入成功。当然这里只是为了验证可以输入内容,测试时候还是输入测试的日期。
三、用js去掉readonly属性 1.用js去掉元素属性基本思路:先定位到元素,然后用removeAttribute("readonly")方法删除属性。 2.出发日元素id为:train_date,对应js代码为:'document.getElementById("train_date").removeAttribute("readonly");'

四、输入日期 1.输入日期前,一定要先清空文本,要不然无法输入成功的。 2.这里输入日期后,会自动弹出日历控件,随便点下其它位置就好了,接下来会用js方法传入日期,就不会弹啦!
五、js方法输入日期 1.这里也可以用js方法输入日期,其实很简单,直接改掉输入框元素的value值就可以啦。
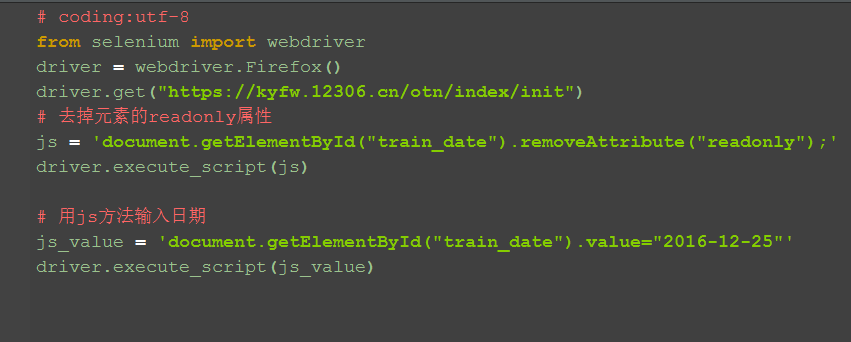
六、参考代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://kyfw.12306.cn/otn/index/init")
# 去掉元素的readonly属性
js = 'document.getElementById("train_date").removeAttribute("readonly");'
driver.execute_script(js)
# 用js方法输入日期
js_value = 'document.getElementById("train_date").value="2016-12-25"'
driver.execute_script(js_value)
# # 清空文本后输入值
# driver.find_element_by_id("train_date").clear()
# driver.find_element_by_id("train_date").send_keys("2016-12-25")
2.24 js处理内嵌div滚动条
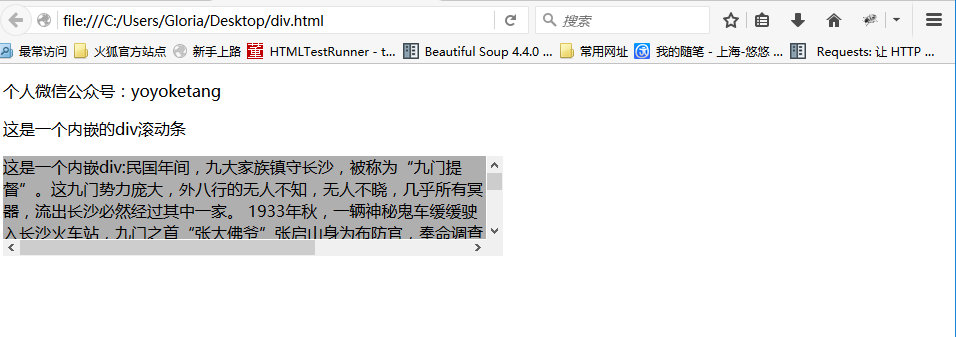
前言 前面有篇专门用js解决了浏览器滚动条的问题,生活总是多姿多彩,有的滚动条就在页面上,这时候又得仰仗js大哥来解决啦。 一、内嵌滚动条 1.下面这张图就是内嵌div带有滚动条的样子,记住它的长相。
2.页面源码如下:(老规矩:copy下来,用文本保存下来,后缀改成.html,用浏览器打开)
<!DOCTYPE html>
<meta charset="UTF-8"> <!-- for HTML5 -->
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<html>
<head>
<style type="text/css">
div.scroll
{
background-color:#afafaf;
width:500px;
height:100px;
overflow:auto;
}
</style>
</head>
<body>
<p>个人微信公众号:yoyoketang</p>
<p>这是一个内嵌的div滚动条</p>
<div id="yoyoketang" name="yoyo" class="scroll">这是一个内嵌div:民国年间,九大家族镇守长沙,被称为“九门提督”。这九门势力庞大,外八行的无人不知,无人不
晓,几乎所有冥器,流出长沙必然经过其中一家。1933年秋,一辆神秘鬼车缓缓驶入长沙火车站,九门之首“张大佛爷”张启山身为布防官,奉命调查始末。张启山与八爷齐铁嘴一路探访,发现长沙城外有一座疑点重重的矿山,一直被日本人窥伺。
为破解矿山之谜,张启山求助同为九门上三门的戏曲名伶二月红,无奈二月红虽出身考古世家,却心系重病的妻子丫头,早已金盆洗手。张启山为了国家大义和手足之情,北上去往新月饭店为二月红爱妻求药。在北平,张启山邂逅了新月饭店的大小姐尹新月,并为尹新月连点三盏天灯,散尽家财。尹新月帮助张启山等人顺利返回
长沙,二人暗生情愫。二月红爱妻病入膏肓,服药后不见好转,最终故去。二月红悲伤之余却意外发现家族祖辈与矿山亦有重大关联,于是振作精神,决定与张启山联手,解开矿山之谜zhegedancihenchanghenchangchangchangchangchanchanchanchangchangchangchancg </div>
</body>
</html>
二、纵向滚动
1.这个是div的属性:<div id="yoyoketang" name="yoyo" class="scroll">
2.这里最简单的通过id来定位,通过控制 scrollTop的值来控制滚动条高度
3.运行下面代码,观察页面是不是先滚动到底部,过五秒再回到顶部。(get里面地址是浏览器打开该页面的地址)

三、横向滚动
1.先通过id来定位,通过控制scrollLeft的值来控制滚动条高度
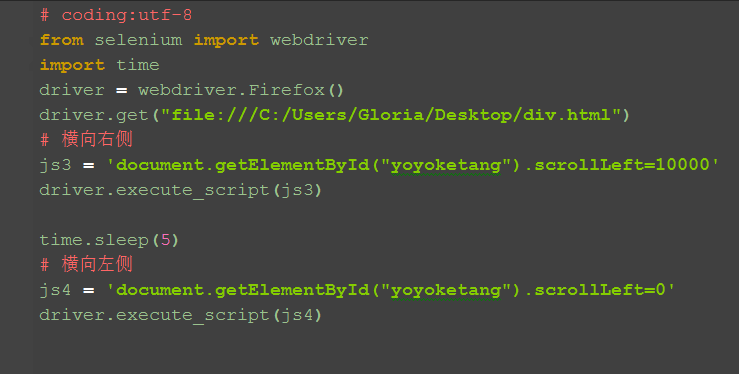
四、用class属性定位 1.js用class属性定位,返回的是一个list对象,这里取第一个就可以了。 2.这里要注意了,element和elements有很多小伙伴傻傻分不清楚。
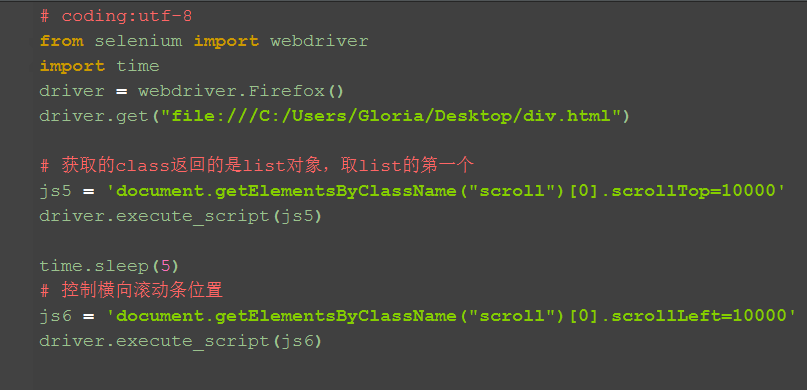
有时候很多元素属性都一样时候,就可以用复数定位,取对应的第几个就可以了。
2.25 js处理多窗口
前言 在打开页面上链接的时候,经常会弹出另外一个窗口(多窗口情况前面这篇有讲解:Selenium2+python自动化13-多窗口、句柄(handle)),这样在多个窗口之间来回切换比较复杂,那么有没有办法让新打开的链接在一个窗口打开呢? 要解决这个问题,得从html源码上找到原因,然后修改元素属性才能解决。很显然js在这方面是万能的,于是本篇得依靠万能的js大哥了。 一、多窗口情况 1.在打baidu的网站链接时,会重新打开一个窗口 (注意:我的百度页面是已登录状态,没登录时候是不会重新打开窗口的)
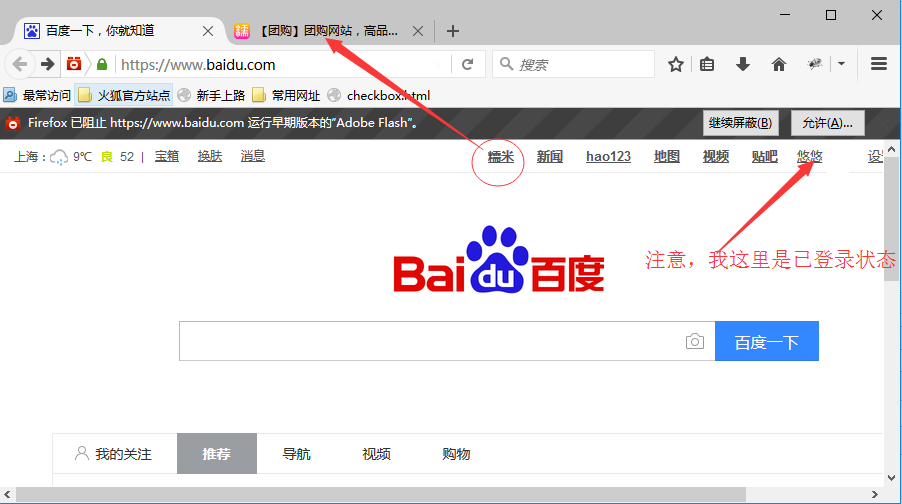
二、查看元素属性:target="_blank" 1.查看元素属性,会发现这些链接有个共同属性:target="_blank"

三、去掉target="_blank"属性 1.因为此链接元素target="_blank",所以打开链接的时候会重新打开一个标签页,那么解决这个问题,去掉该属性就可以了。 2.为了验证这个问题,可以切换到html编辑界面,手动去掉“_blank”属性。
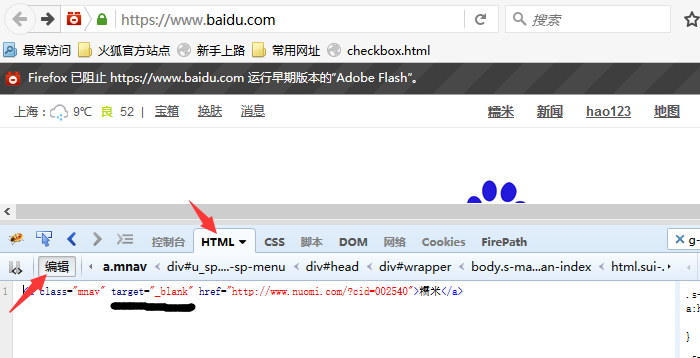
3.删除“_blank”属性后,重新打开链接,这时候会发现打开的新链接会在原标签页打开。
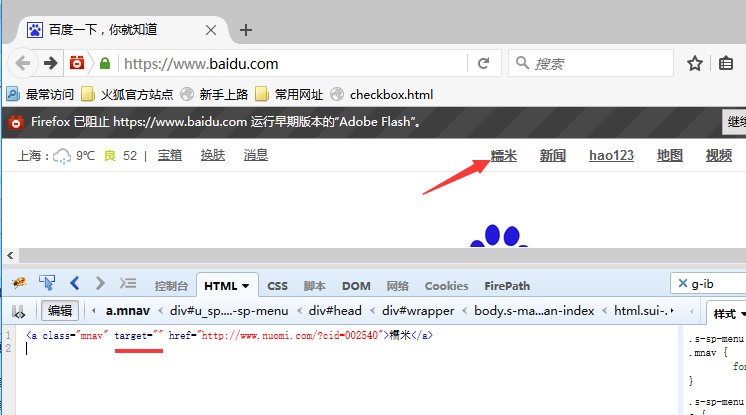
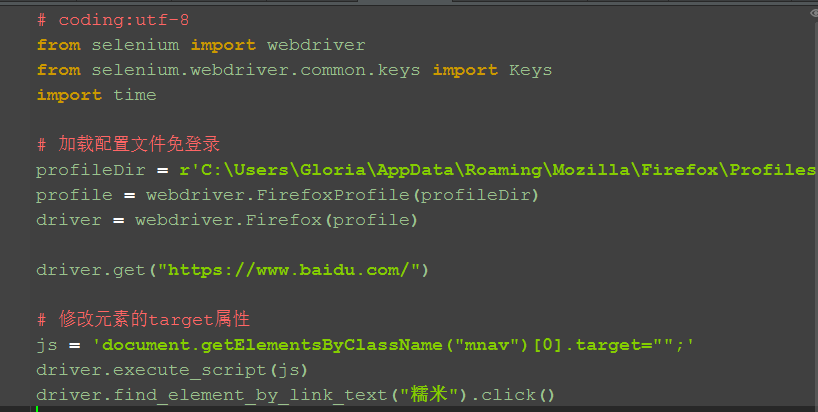
四、js去掉target="_blank"属性 1.第一步为了先登录,我这里加载配置文件免登录了(不会的看这篇:Selenium2+python自动化18-加载Firefox配置) 2.这里用到js的定位方法,定位该元素的class属性 3.定位到该元素后直接修改target属性值为空
五、参考代码
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# 加载配置文件免登录
profileDir = r'C:\Users\Gloria\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
profile = webdriver.FirefoxProfile(profileDir)
driver = webdriver.Firefox(profile)
driver.get("https://www.baidu.com/")
# 修改元素的target属性
js = 'document.getElementsByClassName("mnav")[0].target="";'
driver.execute_script(js)
driver.find_element_by_link_text("糯米").click()
注意:并不是所有的链接都适用于本方法,本篇只适用于有这个target="_blank"属性链接情况。
本篇仅提供解决问题的办法和思路,不要完全照搬代码!!!
2.26 js解决click失效问题
前言 有时候元素明明已经找到了,运行也没报错,点击后页面没任何反应。这种问题遇到了,是比较头疼的,因为没任何报错,只是click事件失效了。 本篇用2种方法解决这种诡异的点击事件失效问题 一、遇到的问题 1.在练习百度的搜索设置按钮时,点保存设置按钮,alert弹出没弹出(代码没报错,只是获取alert失败),相信不只是我一个人遇到过。
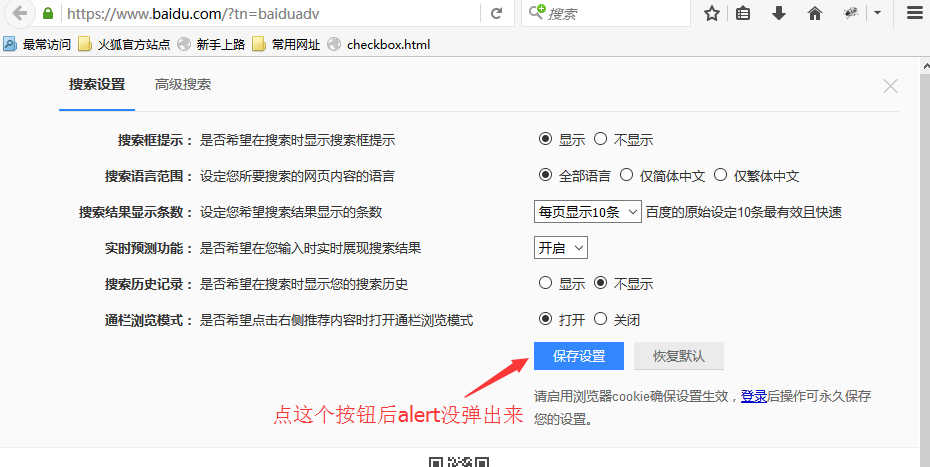
二、点击父元素 1.遇到这种问题,应该是前面操作select后导致的后遗症(因为我注释掉select那段是可以点击成功的)。 2.第一种解决办法,先点击它的父元素一次,然后再点击这个元素。
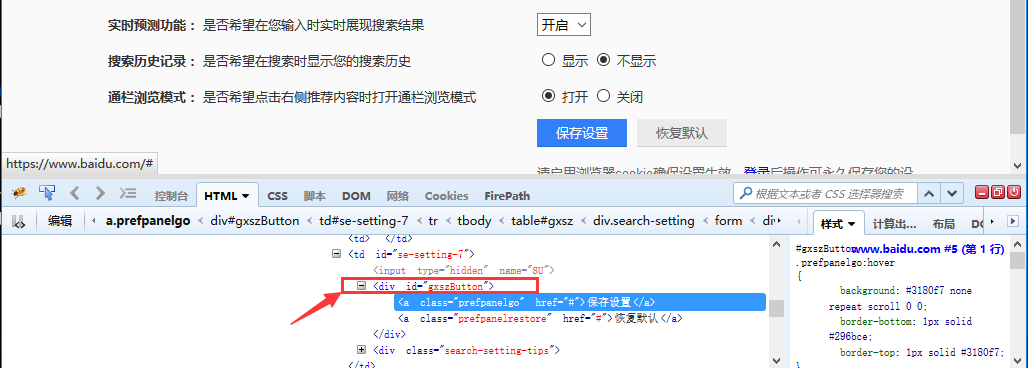
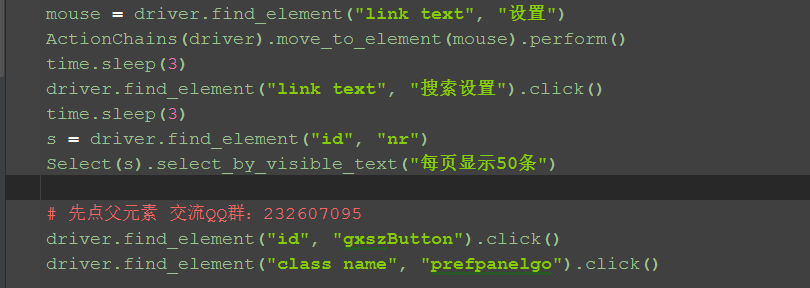
3.实现代码如下
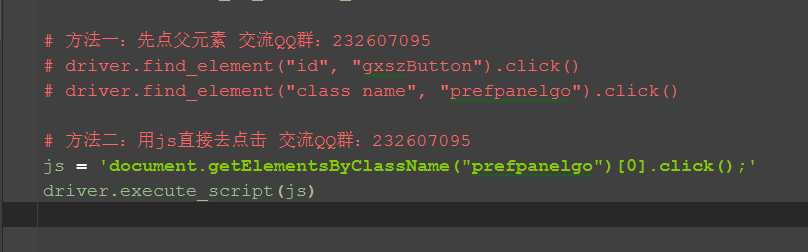
三、js直接点击
1.遇到这种诡异问题,是时候出绝招了:js大法。 2.用js直接执行点击事件。
四、参考代码
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import time
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
time.sleep(3)
mouse = driver.find_element("link text", "设置")
ActionChains(driver).move_to_element(mouse).perform()
time.sleep(3)
driver.find_element("link text", "搜索设置").click()
time.sleep(3)
s = driver.find_element("id", "nr")
Select(s).select_by_visible_text("每页显示50条")
# 方法一:先点父元素 交流QQ群:232607095
# driver.find_element("id", "gxszButton").click()
# driver.find_element("class name", "prefpanelgo").click()
# 方法二:用js直接去点击 交流QQ群:232607095
js = 'document.getElementsByClassName("prefpanelgo")[0].click();'
driver.execute_script(js)
2.27 18种定位方法总结
前言 江湖传言,武林中流传八种定位,其中xpath是宝刀屠龙,css是倚天剑。 除了这八种,其实还有十种定位方法,眼看就快失传了,今天小编让失传已久的定位方法重出江湖!
一、十八种定位方法
前八种是大家都熟悉的,经常会用到的
1.id定位:find_element_by_id(self, id_) 2.name定位:find_element_by_name(self, name) 3.class定位:find_element_by_class_name(self, name) 4.tag定位:find_element_by_tag_name(self, name) 5.link定位:find_element_by_link_text(self, link_text) 6.partial_link定位find_element_by_partial_link_text(self, link_text) 7.xpath定位:find_element_by_xpath(self, xpath) 8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式
9.id复数定位find_elements_by_id(self, id_) 10.name复数定位find_elements_by_name(self, name) 11.class复数定位find_elements_by_class_name(self, name) 12.tag复数定位find_elements_by_tag_name(self, name) 13.link复数定位find_elements_by_link_text(self, text) 14.partial_link复数定位find_elements_by_partial_link_text(self, link_text) 15.xpath复数定位find_elements_by_xpath(self, xpath) 16.css复数定位find_elements_by_css_selector(self, css_selector)
这两种就是快失传了的
17.find_element(self, by='id', value=None) 18.find_elements(self, by='id', value=None)
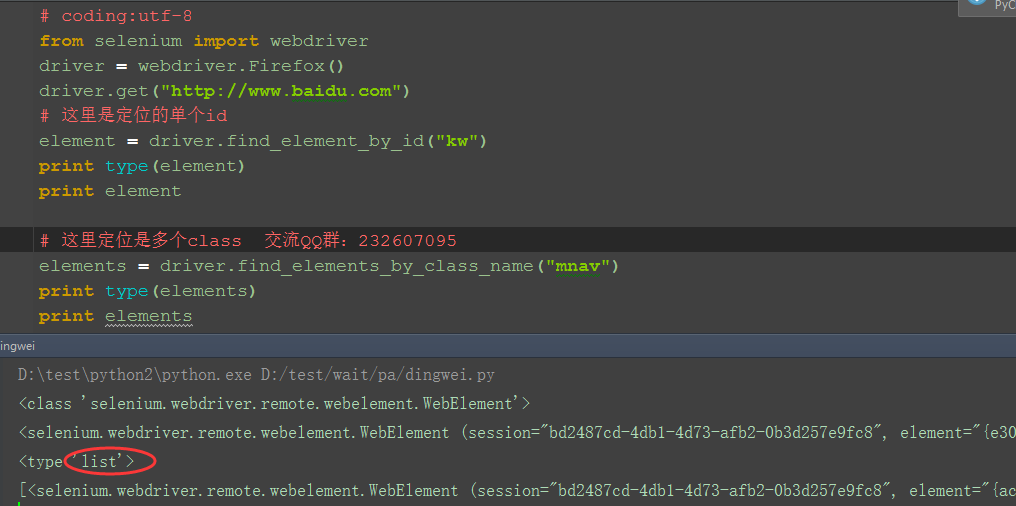
二、element和elements傻傻分不清 1.element方法定位到是是单数,是直接定位到元素 2.elements方法是复数,这个学过英文的都知道,定位到的是一组元素,返回的是list队列 3.可以用type()函数查看数据类型 4.打印这个返回的内容看看有什么不一样
三、elements定位方法 1.前面2.8章节讲过定位一组元素用elements的方法,elements也可以用于单数定位。
2.这里重点介绍下用elements方法如何定位元素,当一个页面上有多个属性相同的元素时,然后父元素的属性也比较模糊,不太好定位。这个时候不用怕,换个思维,别老想着一次定位到,可以先把相同属性的元素找出来,取对应的第几个就可以了。
3.如下图,百度页面上有六个class一样的元素,我要定位“地图”这个元素。
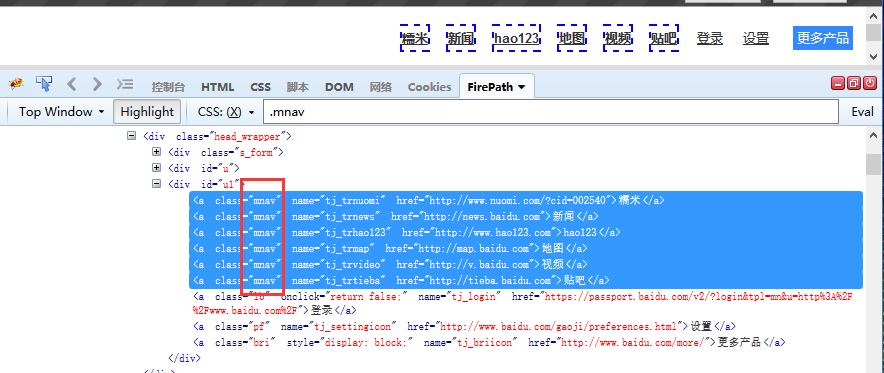
4.取对应下标即可定位了。
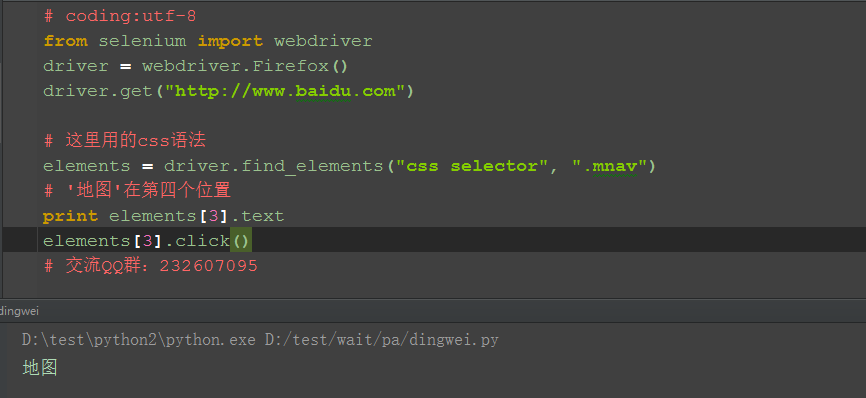
四、参考代码
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 这里是定位的单个id
element = driver.find_element_by_id("kw")
print type(element)
print element
# 这里定位是多个class
elements = driver.find_elements_by_class_name("mnav")
print type(elements)
print elements
# 这里用的css语法
s = driver.find_elements("css selector", ".mnav")
# '地图'在第四个位置
print s[3].text
s[3].click()
# 这个写法也是可以的
# driver.find_elements("css selector", ".mnav")[3].click()
2.28 查看webdriver API(带翻译)
前言 前面都是点点滴滴的介绍selenium的一些api使用方法,那么selenium的api到底有多少呢?本篇就教大家如何去查看selenium api,不求人,无需伸手找人要,在自己电脑就有。 pydoc是Python自带的模块,主要用于从python模块中自动生成文档,这些文档可以基于文本呈现的、也可以生成WEB 页面的,还可以在服务器上以浏览器的方式呈现! 一、pydoc 1.到底什么是pydoc? ,这个是准确的解释:Documentation generator and online help system. pydoc是Python自带的模块,主要用于从python模块中自动生成文档,这些文档可以基于文本呈现的、也可以生成WEB 页面的,还可以在服务器上以浏览器的方式呈现!简而言之,就是帮你从代码和注释自动生成文档的工具。
2.举个栗子,我需要查看python里面open函数的功能和语法,打开cmd,输入:python -m pydoc open
3.-m参数:python以脚本方法运行模块 >>python -m pydoc open
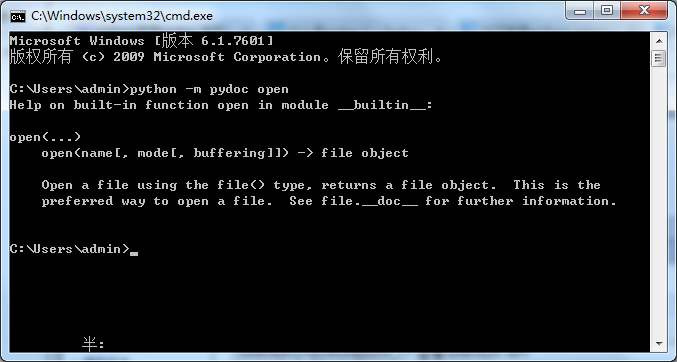
那么问题来了,这个是已经知道有这个函数,去查看它的功能,selenium里面不知道到底有多少个函数或方法,那如何查看呢?
二、启动server 1.打开cmd命令行,输入:python -m pydoc -p 6666 2.-p参数:这个表示在本机上启动服务 3.6666参数:这个是服务端口号,随意设置
打开后,界面会出现一个地址:http://localhost:6666/,在浏览器直接打开。
三、浏览器查看文档 1.在浏览器输入:http://localhost:6666/ 2.Built-in Moudles :这个是python自带的模块
四、webdriver API
1.找到这个路径:python2.7\lib\site-packages,点开selenium 2.打开的selenium>webdriver>firefox>webdriver,最终路径:http://localhost:6666/selenium.webdriver.firefox.webdriver.html 3.最终看到的这些就是selenium的webdriver API帮助文档啦
【附录】webdriver API(带翻译)
1.找到这个路径:python2.7\lib\site-packages,点开selenium 2.打开的selenium>webdriver>firefox>webdriver,最终路径:http://localhost:6666/selenium.webdriver.firefox.webdriver.html 3.最终看到的这些就是selenium的webdriver API帮助文档啦
1.add_cookie(self,cookie_dict)
##翻译:添加cookie,cookie参数为字典数据类型
Adds a cookie to your current session.
:Args:
- cookie_dict: A dictionary object, with required keys - "name" and"value";
optional keys - "path", "domain", "secure","expiry"
Usage:
driver.add_cookie({'name' : 'foo', 'value' : 'bar'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/','secure':True})
2.back(self)
##浏览器返回
Goes one step backward in the browser history.
:Usage:
driver.back()
3.close(self)
##关闭浏览器
Closes the current window.
:Usage:
driver.close()
4.create_web_element(self,element_id)
##给元素分配一个id
Creates a web element with the specified element_id.
5.delete_all_cookies(self)
##删除所有的cookies
Delete all cookies in the scope of the session.
:Usage:
driver.delete_all_cookies()
6.delete_cookie(self,name)
##删除指定name的cookie
Deletes a single cookie with the given name.
:Usage:
driver.delete_cookie('my_cookie')
7.execute(self,driver_command, params=None)
Sends a command to be executed by a command.CommandExecutor.
:Args:
- driver_command: The name of the command to execute as a string.
- params: A dictionary of named parameters to send with the command.
:Returns:
The command's JSON response loaded into a dictionary object.
8.execute_async_script(self,script, *args)
Asynchronously Executes JavaScript in the current window/frame.
:Args:
- script: The JavaScript to execute.
- \*args: Any applicable arguments for your JavaScript.
:Usage:
driver.execute_async_script('document.title')
9.execute_script(self,script, *args)
##执行JS
Synchronously Executes JavaScript in the current window/frame.
:Args:
- script: The JavaScript to execute.
- \*args: Any applicable arguments for your JavaScript.
:Usage:
driver.execute_script('document.title')
10.file_detector_context(*args,**kwds)
Overrides the current file detector (if necessary) in limited context.
Ensures the original file detector is set afterwards.
Example:
with webdriver.file_detector_context(UselessFileDetector):
someinput.send_keys('/etc/hosts')
:Args:
- file_detector_class - Class of the desired file detector. If the class is different
from the current file_detector, then the class is instantiated with args andkwargs
and used as a file detector during the duration of the context manager.
- args - Optional arguments that get passed to the file detector class during
instantiation.
- kwargs - Keyword arguments, passed the same way as args.
11.find_element(self,by='id', value=None)
##定位元素,参数化的方法
'Private' method used by the find_element_by_* methods.
:Usage:
Use the corresponding find_element_by_* instead of this.
:rtype: WebElement
12.find_element_by_class_name(self,name)
##通过class属性定位元素
Finds an element by class name.
:Args:
- name: The class name of the element to find.
:Usage:
driver.find_element_by_class_name('foo')
13.find_element_by_css_selector(self,css_selector)
##通过css定位元素
Finds an element by css selector.
:Args:
- css_selector: The css selector to use when finding elements.
:Usage:
driver.find_element_by_css_selector('#foo')
14.find_element_by_id(self,id_)
##通过id定位元素
Finds an element by id.
:Args:
- id\_ - The id of the element to be found.
:Usage:
driver.find_element_by_id('foo')
15.find_element_by_link_text(self,link_text)
##通过link链接定位
Finds an element by link text.
:Args:
- link_text: The text of the element to be found.
:Usage:
driver.find_element_by_link_text('Sign In')
16.find_element_by_name(self,name)
##通过name属性定位
Finds an element by name.
:Args:
- name: The name of the element to find.
:Usage:
driver.find_element_by_name('foo')
17.find_element_by_partial_link_text(self,link_text)
##通过部分link的模糊定位
Finds an element by a partial match of its link text.
:Args:
- link_text: The text of the element to partially match on.
:Usage:
driver.find_element_by_partial_link_text('Sign')
18.find_element_by_tag_name(self,name)
##通过标签定位
Finds an element by tag name.
:Args:
- name: The tag name of the element to find.
:Usage:
driver.find_element_by_tag_name('foo')
19.find_element_by_xpath(self,xpath)
##通过xpath语法定位
Finds an element by xpath.
:Args:
- xpath - The xpath locator of the element to find.
:Usage:
driver.find_element_by_xpath('//div/td[1]')
20.find_elements(self,by='id', value=