
大二上 网络新科学 链路预测算法及其应用 20241211
大模型讲解概念如此说:


matlab代码实操:
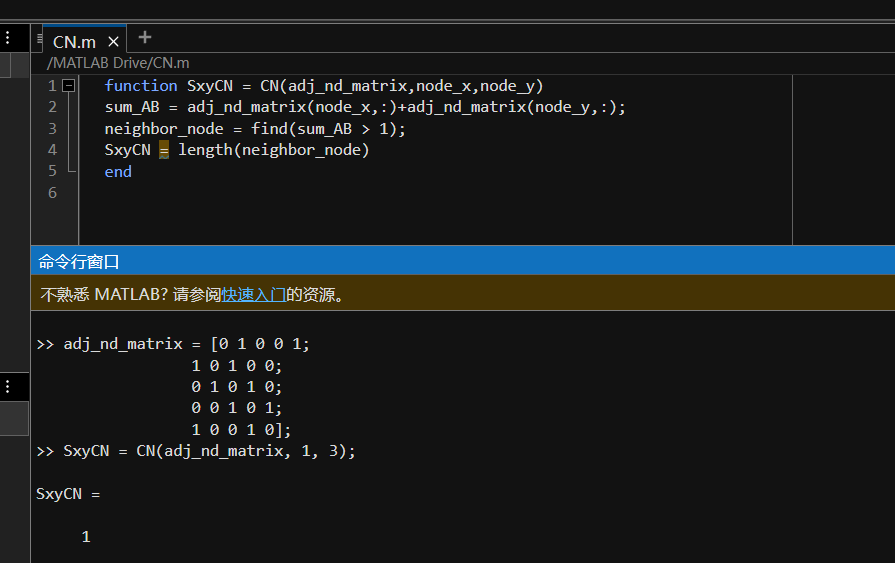
function SxyCN = CN(adj_nd_matrix,node_x,node_y)
sum_AB = adj_nd_matrix(node_x,:)+adj_nd_matrix(node_y,:);
neighbor_node = find(sum_AB > 1);
SxyCN = length(neighbor_node)
end
解释:
这段MATLAB代码定义了一个名为 CN 的函数,它用于计算两个节点 node_x 和 node_y 在一个无向图中的共同邻居数量。这个函数接受三个参数:
adj_nd_matrix:邻接矩阵,表示图中节点之间的连接关系。如果节点 i 和节点 j 之间有边,则 adj_nd_matrix(i,j) 的值为1(或大于0,取决于图的类型,如果是无权图则为1),否则为0。
node_x:第一个节点的索引。
node_y:第二个节点的索引。
函数的工作流程如下:
sum_AB = adj_nd_matrix(node_x,:)+adj_nd_matrix(node_y,:); 这一行计算节点 node_x 和 node_y 的邻居节点集合。对于 node_x,adj_nd_matrix(node_x,:) 会返回一个向量,表示 node_x 与图中所有节点的连接情况。同理,adj_nd_matrix(node_y,:) 表示 node_y 的连接情况。将这两个向量相加,得到一个新的向量 sum_AB,其中的每个元素表示对应节点是否同时是 node_x 和 node_y 的邻居(如果两个节点都是邻居,则该位置的值为2)。
neighbor_node = find(sum_AB > 1); 这一行找出 sum_AB 中大于1的元素的索引,即找出同时是 node_x 和 node_y 邻居的节点。
SxyCN = length(neighbor_node); 这一行计算 neighbor_node 中元素的数量,即 node_x 和 node_y 的共同邻居数量,并将这个值赋给 SxyCN。
如何使用这个函数:
首先,你需要有一个图的邻接矩阵 adj_nd_matrix。
确定你想要计算共同邻居数量的两个节点的索引 node_x 和 node_y。
调用函数 CN(adj_nd_matrix, node_x, node_y),它将返回这两个节点的共同邻居数量。

实际效果如图:
function AUC_DATA = AUC_CN(adj_nd_matrix, ntimes)
[a,b] = find(adj_nd_matrix == 1);
p = 0.1;
j = 1;
while j <= ntimes
B = adj_nd_matrix;
for i = 1:length(a)
r = rand (1,1);
if r < p
B(a(i), b(i)) = 0;
B(b(i), a(i)) = 0;
end
end
maxsize = length(adj_nd_matrix);
C = sparse (maxsize, maxsize);
C = adj_nd_matrix - B;
[a3, a4] = find(C == 1);
n1 = 0;
i = 0;
while i < ntimes
a5 = ceil(rand(1) * length(adj_nd_matrix));
a6 = ceil(rand(1) * length(adj_nd_matrix));
num1 = ceil(rand(1)* length(a3));
if adj_nd_matrix(a5,a6) == 0
if CN(B, a3(num1), a4(num1)) > CN(B, a5, a6)
n1 = n1 + 1;
else if CN(B, a3(num1), a4(num1)) == CN(B, a5, a6)
n1 = n1 + 0.5
end
end
i = i + 1;
end
end
DATA(j) = n1/ntimes;
j = j+1;
end
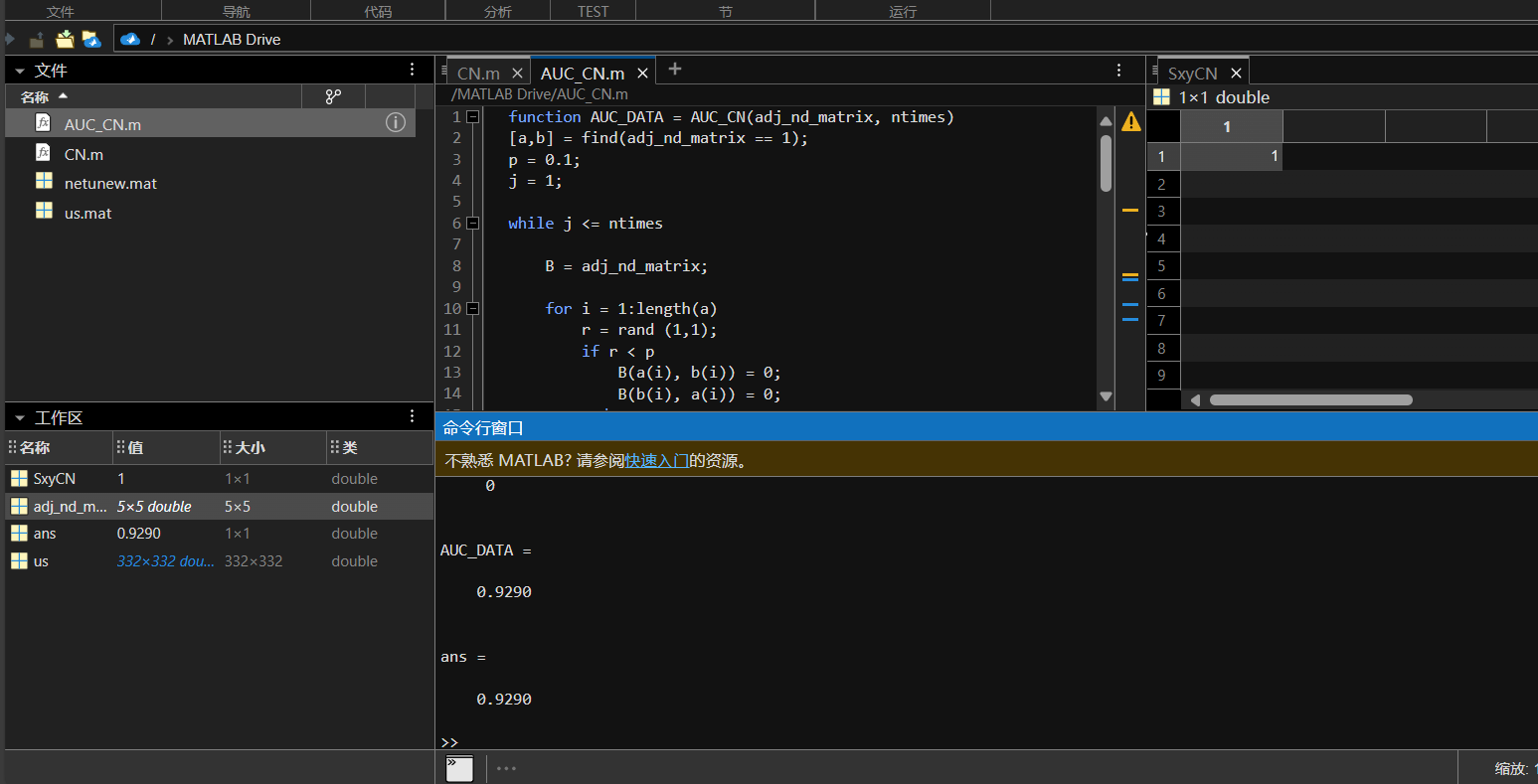
AUC_DATA = mean(DATA)
end
这段MATLAB代码定义了一个名为 AUC_CN 的函数,它用于评估一个图模型的AUC(Area Under the Curve)值,这是一个衡量分类器性能的指标。这个函数通过模拟边的随机删除和添加来评估图的连通性变化,从而估计AUC值。函数接受两个参数:
adj_nd_matrix:邻接矩阵,表示图中节点之间的连接关系。
ntimes:模拟的次数。
函数的工作流程如下:
使用 find(adj_nd_matrix == 1) 找出邻接矩阵中所有为1的元素的索引,即图中所有的边。
初始化概率 p 和计数器 j。
while j <= ntimes:开始一个循环,模拟 ntimes 次。
复制邻接矩阵到 B,并遍历所有的边,以概率 p 删除边。
计算新的邻接矩阵 C,即 adj_nd_matrix - B。
find(C == 1):找出新邻接矩阵中所有为1的元素的索引,即图中剩余的边。
初始化计数器 n1 和循环计数器 i。
while i < ntimes:开始一个内部循环,模拟 ntimes 次。
随机选择两个节点 a5 和 a6,并随机选择一个共同邻居 num1。
如果节点 a5 和 a6 之间没有边,比较这两个节点与共同邻居的共同邻居数量,根据比较结果更新 n1。
更新内部循环计数器 i。
计算每次模拟的平均值 DATA(j) = n1/ntimes。
更新外部循环计数器 j。
最后,计算所有模拟的平均值 AUC_DATA = mean(DATA) 作为AUC值。
如何使用这个函数:
首先,你需要有一个图的邻接矩阵 adj_nd_matrix,这个邻接矩阵可以存储在一个 .mat 文件中。
确定你想要模拟的次数 ntimes。
加载 .mat 文件中的邻接矩阵到变量 us。
调用函数 AUC_CN(us, ntimes),它将返回图的AUC值。
例如,如果你有一个名为 us.mat 的文件,其中包含邻接矩阵 us,你可以这样使用这个函数:
matlab
load('us.mat'); % 加载.mat文件中的邻接矩阵
AUC_DATA = AUC_CN(us, 100); % 调用函数并传入邻接矩阵和模拟次数
这将返回图的AUC值。这个值可以用来评估图模型的性能,特别是在图分类或图匹配任务中。
输入AUC_CN(us,100)效果如图:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~